Как да измерим мрежовата латентност: Практическо ръководство за разработчици
Научете как да измервате латентността на мрежата с това изчерпателно ръководство. Обхващаме основни инструменти като ping и traceroute, както и техники за тестване в браузър.

Препоръчани разширения
Искате ли да измерите латентността на мрежата? Можете да започнете с прости вградени инструменти за команден ред като ping и traceroute, за да получите бърза представа за Времето за обиколка (RTT). Или можете да отворите инструментите за разработчици на браузъра си, за да видите как забавянията влияят на това, което вашите потребители всъщност изпитват.
Тези методи ви дават бърз и полезен моментен поглед върху това колко време отнема на пакет данни да пътува от източник до дестинация и да се върне обратно.
Защо измерването на латентността е неизменна част
Преди да преминем към "как", нека поговорим за "защо". За разработчици и мрежови инженери латентността не е просто число на екрана; тя е невидимата ръка, която оформя цялостното потребителско изживяване. В днешните приложения милисекундите са всичко. Дори и най-малкото забавяне може да бъде разликата между услуга, която изглежда мигновена, и такава, която изглежда счупена.
Помислете за реалните последици:
- Отзивчивост на API: Едно бавно API повикване може да създаде домино ефект, забавяйки всичко - от зареждането на профила на потребителя до обработката на критично плащане.
- Данни в реално време: За онлайн игри, живо видео или финансови търговии, ниската и постоянна латентност е абсолютната основа. Без нея тези приложения просто не работят.
- Задържане на потребители: Има пряка връзка между бавно зареждащите се уебсайтове и приложения и по-високите проценти на отпадане и изоставени колички за пазаруване. Тези неща удрят по крайния резултат, сериозно.
Разграничаване на ключови концепции за латентност
За да измерите латентността на мрежата точно, трябва да знаете какво гледате. Двете най-фундаментални концепции са Време за обиколка (RTT) и латентност в едната посока.
RTT е общото време, необходимо на сигнал да премине от точка A до точка B и обратно. Това е най-често срещаната метрика, която ще видите, защото е лесна за измерване - нужно е само да имате достъп до единия край на връзката.
Латентност в едната посока, както подсказва името, измерва времето, необходимо на данните да пътуват в само една посока. Това е много по-трудно измерване, защото изисква перфектно синхронизирани часовници на двата края. Въпреки това, това е много по-точен индикатор за асиметрични връзки, където пътищата за качване и сваляне се държат много различно.
Важността на всичко това става кристално ясна, когато правите сериозно тестиране на производителността при натоварване, където теорията среща реалността и задръстванията се разкриват.
За да поставим някои числа, експертите по мониторинг на мрежата обикновено класифицират латентността по следния начин:
- Ниска латентност: Под 50 милисекунди
- Умерена латентност: 50-150 ms
- Висока латентност: Над 150 ms
От моя опит, бърз тест до близък сървър може да покаже напълно приемливи 20-40 ms. Но това число може лесно да нарасне до над 200 ms за трафик, който трябва да премине през океан, което може да бъде решаващо за производителността на вашето приложение.
За да разберете жаргона, с който ще се сблъскате, ето бърза справка.
Ключови концепции за латентност на един поглед
| Концепция | Какво измерва | Защо е важно |
|---|---|---|
| Латентност (Ping) | Времето, необходимо на един пакет данни да премине от източник до дестинация и обратно. Измерва се в милисекунди (ms). | Това е суровото измерване на забавянето. Ниската латентност е от съществено значение за приложения в реално време като игри, VoIP и видеоконференции. |
| Време за обиколка (RTT) | По същество същото като латентността, това е общата продължителност за изпращане на сигнал плюс времето за получаване на потвърждение. | RTT е най-често срещаният и практичен начин за измерване на латентността от една точка, което го прави основна метрика за инструменти като ping. |
| Латентност в едната посока | Времето, необходимо на пакет да премине от източник до дестинация в една посока. | Предоставя по-подробен поглед, особено за асиметрични мрежи, където пътищата за качване и сваляне имат различна латентност. |
| Джитър | Вариацията в латентността с времето. Измерва непостоянството на времето за пристигане на пакетите. | Високият джитър е също толкова лош, колкото и високата латентност за стрийминг медии и онлайн разговори, причинявайки заеквания, буфериране и проблеми. |
| Пропускателна способност | Максималното количество данни, което може да бъде предадено през мрежова връзка за определен период от време. Измерва се в Mbps или Gbps. | Често се бърка със скоростта, пропускателната способност е свързана с капацитета. Можете да имате висока пропускателна способност, но все пак да страдате от висока латентност. |
Тези концепции са основните блокове за разбиране на всякакви проблеми с производителността на мрежата.
Тук е важно да имате достъпни, интегрирани инструменти. Вместо да изпълнявате сложни диагностични пакети, съвременните разширения на браузъра и инструменти за разработка могат да ви предоставят необходимата информация, без да напускате работния си процес. Става въпрос за това да направите измерването на латентността лесна, рутинна част от изграждането и поддържането на страхотен софтуер.
Започнете с инструменти за латентност от командния ред
За да получите истинска представа за производителността на вашата мрежа, трябва да отворите терминала. Командният ред е мястото, където ще намерите основните инструменти, които ви дават сурови, нефилтрирани данни за вашата връзка. Става въпрос за това да видите какво наистина се случва с пакетите, преминаващи между вас и дестинацията, и това е основната първа стъпка за всеки разработчик, който сериозно се занимава с измерване на латентността.
Класическият, основен инструмент е ping. Той е изключително прост: изпраща малък пакет данни (ICMP echo request) до сървър и просто чака да се върне. Тази проста обиколка е основата за изчисляване на Времето за обиколка (RTT) и ви дава моментална проверка на здравословното състояние на връзката.
Вашата първа проверка на латентността с Ping
Изпълнението на тест с ping не може да бъде по-лесно. Стартирайте терминала или командния ред, напишете ping и след това добавете домейна, който искате да тествате.
По подразбиране ping ще продължи да работи безкрайно на macOS и Linux, докато Windows изпраща само четири пакета и спира. За всякакъв реален анализ, ще искате да контролирате това. Изпращането на десет или двадесет пакета ви дава много по-надеждна представа за стабилността на връзката, отколкото само няколко.
След като приключи, ще получите подреден резюме с важните числа:
- Изпратени/Получени пакети: Това ви казва дали е загубен някакъв данни по пътя. Дори и малко количество загуба на пакети е сериозен червен флаг за проблеми с мрежата.
- Минимум/Средно/Максимум/Средно отклонение на обиколката: Това са основните ви статистики за латентност. Получавате най-доброто време (
min), средното (avg) и най-лошото (max).mdev(средно отклонение) е вашата мярка за джитър - колко варира латентността от един пакет до следващия.
Обърнете внимание на разликата между минималната и максималната RTT. Ако е широка, вашата връзка е нестабилна, дори ако средното изглежда добре. Този джитър може да бъде много по-разрушителен за приложения в реално време като видеозвънене или игри, отколкото връзка, която е последователно малко бавна.
Честа грешка е просто да се погледне средната RTT. Средно 50ms може да изглежда добре, но ако минималната е 20ms и максималната е 250ms, потребителското изживяване ще изглежда накъсано и ненадеждно. Винаги разглеждайте целия диапазон, за да разберете джитъра.
Следвайки следите с Traceroute и MTR
И така, какво правите, когато ping разкрие висока латентност или загуба на пакети? Следващата ви задача е да разберете къде е проблемът. За това е предназначен traceroute (или tracert на Windows). Той картографира целия път, по който преминават вашите пакети, показвайки ви всяко "скок" - всеки рутер - между вашата машина и крайната дестинация.
Всяка линия в изхода на traceroute е скок, и обикновено показва три отделни измервания на латентността до тази точка. Това ви позволява да определите дали конкретен рутер по пътя причинява значително забавяне или загуба на пакети.
Но traceroute е еднократен моментен поглед. За по-динамичен, непрекъснат поглед, повечето мрежови специалисти, които познавам, се кълнат в MTR (My Traceroute). MTR е като супер зареден инструмент, който комбинира ping и traceroute. Той постоянно изпраща пакети до всеки скок по маршрута, предоставяйки ви жив, актуализиран поглед върху латентността и загубата на пакети на всяка точка. Това го прави изключително ефективен за улавяне на интермитентни проблеми, които един traceroute вероятно би пропуснал.
Защо изборът на инструмент е важен
Инструментът, който изберете, и как го конфигурирате, могат драстично да променят резултатите ви. Това е особено вярно в ултра-бързи, нисколатентни среди като облачни центрове за данни.
Всъщност е доста поразително колко различни могат да бъдат числата. В детайлен експеримент, проведен от Google Cloud, стандартен тест с ping отчете средна RTT от 146 микросекунди. Но когато използваха друг инструмент, който изпраща транзакции последователно без пауза, RTT спадна до само 66.59 микросекунди - повече от два пъти по-бързо!
Това е перфектен пример за това защо ping понякога може да надценява латентността. То показва, че разбирането на как работи инструментът е критично за получаване на измервания, на които можете да се доверите.
Намиране на максималната скорост на вашата връзка с iperf
Латентността не винаги е цялата картина. Понякога трябва да знаете максималното количество данни, което вашата връзка наистина може да предаде - нейната пропускателна способност. За тази работа инструментът, който искате, е iperf.
Докато ping измерва забавянето, iperf е изцяло за пропускателната способност. Той работи, като настройва клиент-сървърна връзка и след това изпраща колкото се може повече данни между тях за определен период от време.
За да използвате iperf, ще ви трябват две машини:
- На едната машина стартирате
iperfв сървърен режим. Той просто ще седи там и ще слуша за връзка. - На другата машина стартирате
iperfв клиентски режим, насочвайки го към адреса на сървъра.
Клиентът ще се свърже и тестът ще започне. Изходът ви казва общото количество прехвърлени данни и, най-важното, битрейт (вашата пропускателна способност) в мегабити или гигабити в секунда. Това е перфектният начин да тествате натоварването на мрежовата връзка и да разберете какво наистина е способна.
Измерване на латентността от перспективата на потребителя
Докато инструментите за команден ред ви дават суров, нефилтриран поглед върху вашата мрежа, единствената латентност, която наистина има значение за уеб приложение, е това, което крайният потребител всъщност изпитва. Тук прехвърляме фокуса си от терминала към самия браузър. Това, което се случва вътре в браузъра, разказва много по-богата и по-релевантна история за производителността.
Никога не става въпрос само за обиколката на един пакет. Латентността, която потребителят усеща, е сложен коктейл от DNS запитвания, TCP ръкостискания, TLS преговори, време за обработка на сървъра и разбира се, времето, необходимо за действително визуализиране на съдържанието на екрана. За щастие, съвременните браузъри идват с мощни вградени инструменти, които ни помагат да анализираме целия този процес.
Задълбочаване в инструментите за разработчици на браузъра
Всеки основен браузър - Chrome, Firefox, Edge, Safari - е оборудван с набор от инструменти за разработчици. Вкладката "Мрежа" в тези инструменти е вашият команден център за разбиране на начина, по който вашият сайт се зарежда. Тя представя всичко в графика на водопад, която е визуален анализ на всяко едно запитване, което браузърът прави, за да визуализира страница.
Този водопаден изглед е безценен. Можете да видите точно колко време е отнело на всеки актив да се изтегли, от началния HTML документ и CSS стиловете до изображенията и API повикванията. По-важно е, че той разбива жизнения цикъл на всяко запитване на отделни фази:
- DNS Запитване: Времето, необходимо за разрешаване на домейн името до IP адрес.
- Начална Връзка: Времето, прекарано за установяване на TCP връзка със сървъра.
- SSL/TLS Ръкостискане: Разходите, необходими за настройка на сигурна връзка.
- Време до Първия Байтове (TTFB): Това е голямо. То измерва колко време е чакал браузърът, преди да получи първия байт данни от сървъра.
- Изтегляне на Съдържание: Времето, прекарано за действително изтегляне на ресурса.
Висок TTFB, например, е класически знак за бавен бекенд или проблем с обработката на сървъра - нещо, което прост тест с ping никога не би разкрил. Чрез анализиране на този водопад можете бързо да откриете кои ресурси блокират визуализацията или просто отнемат твърде много време за зареждане.
Ключов извод от моя опит е да не се гледа само общото време за зареждане, а да се търсят най-дългите ленти в водопада. Един единствен неоптимизиран образ или бавен API на трета страна може да задържи цялата страница, създавайки лошо потребителско изживяване, дори ако останалата част от сайта е светкавично бърза.
Програмно измерване с Timing APIs
За по-автоматизирани и прецизни измервания можете да се възползвате от вградените JavaScript APIs на браузъра. Navigation Timing API и Resource Timing API ви дават програматичен достъп до същите подробни данни за производителността, които виждате в инструментите за разработчици. Това е перфектно за събиране на данни за реално потребителско наблюдение (RUM), за да разберете как вашият сайт работи за действителни посетители по целия свят.
Можете да получите тези метрики с само няколко реда JavaScript, направо в конзолата на браузъра. За да получите основните времеви показатели за основното зареждане на страницата, например, можете да използвате performance.getEntriesByType('navigation'). Това връща обект, пълен с ценни времеви печати.
От тези данни можете да изчислите жизненоважни метрики:
- Време за DNS Запитване:
domainLookupEnd - domainLookupStart - Време за TCP Ръкостискане:
connectEnd - connectStart - Време до Първия Байтове (TTFB):
responseStart - requestStart - Общо Време за Зареждане на Страницата:
loadEventEnd - startTime
Този подход ви позволява да изградите персонализирани табла за управление или да изпратите данни за производителността на вашите аналитични инструменти, предоставяйки ви непрекъснато наблюдение на реалната производителност на вашето приложение. В уеб разработката оптимизацията на изображенията е често срещан начин за подобряване на тези метрики; за тези, които се интересуват, имаме полезно ръководство за избора на най-добрия формат на изображение за вашия уебсайт.
Оптимизиране на проверките с интегрирани инструменти
Скачането между терминала, инструментите за разработка на браузъра и персонализираните скриптове може бързо да стане досадно. Тук интегрираните разширения за браузъра могат наистина да улеснят вашия работен процес, като обединят тези проверки. Например, комплектът ShiftShift Extensions включва вграден инструмент Speed Test, който можете да отворите незабавно от всяка раздела.
Това ви дава бърз, фокусиран върху конфиденциалността начин за измерване на скоростта на изтегляне, скоростта на качване и латентността на вашата връзка, без да е необходимо да навигирате до отделен уебсайт или да отваряте терминал. Тъй като е част от по-голям инструментариум, можете да извършите проверка на скоростта, да форматирате JSON отговор и да проверите бисквитка, всичко от същата обединена палитра на команди. Този вид интеграция прави проверките на производителността естествена, безпроблемна част от ежедневната разработка.
Как да проектирате тест за латентност, който наистина да ви каже нещо
Всеки може да изпрати команда ping и да получи число в отговор. Но ако искате данни, на които наистина да се доверите — данни, които ви помагат да вземате реални решения — трябва да бъдете по-деликатни. Едно единствено, изолирано измерване е просто моментна снимка във времето. За да разберете истинското поведение на вашата мрежа, трябва да мислите като детектив, като вземете предвид откъде тествате, колко често тествате и какво всъщност търсите.
Добре проектираният тест превръща суровите числа в приложими прозрения. Лошо проектираният? Просто е шум.
Диаграмата по-долу разлага всички малки забавяния, които се натрупват до това, което потребителят усеща, когато зарежда уеб страница. Това е чудесно напомняне, че простият мрежов ping дори не започва да разказва цялата история.
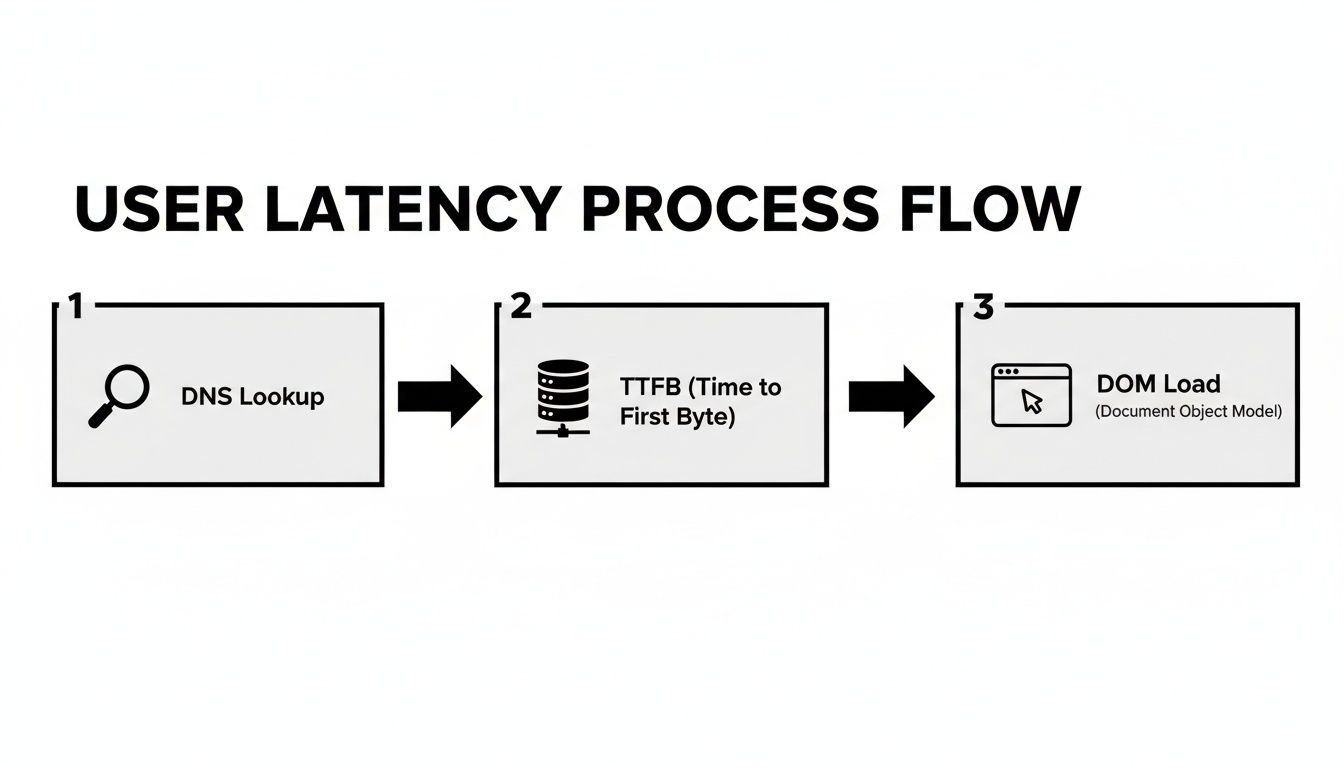
Както можете да видите, от началното DNS търсене до финалното рендериране, множество стъпки допринасят за общото време на изчакване.
Избор на вашите тестови крайни точки
Първото правило на надеждното тестване е, че географията има значение. Тест от вашия офис в Ню Йорк до сървър наблизо в Ню Джърси не ви казва абсолютно нищо за опита на вашите клиенти в Токио. За да получите реалистична картина, трябва да тествате от разнообразни места, които наистина отразяват вашата потребителска база.
Вашият списък с крайни точки трябва да обхваща няколко ключови области:
- Вашите най-големи потребителски хъбове: Къде живеят повечето от вашите клиенти? Тествайте от там.
- Крос-континентални пътища: Вижте какво се случва, когато данните трябва да преминат през океан. Тествайте между Европа и Северна Америка или Азия и САЩ, за да разберете производителността на дълги разстояния.
- Вашите облачни региони: Ако сте на AWS, Azure или GCP, тествайте свързаността към и между конкретните региони на центровете за данни, на които разчитате.
Разпределянето на тестовете по този начин създава много по-точна карта на глобалната производителност. То ви помага да откриете специфични за региона задръствания, които иначе бихте пропуснали напълно. Това е и добър момент да проверите настройките на домейна си; можете да намерите полезни съвети за как да проверите наличността на домейна и свързаните конфигурации, за да се уверите, че всичко е наред.
Намиране на правилния ритъм на тестване
Мрежовите условия постоянно се променят. Те се променят през деня, седмицата и дори минутата. Тест, проведен в 3 сутринта в вторник, може да изглежда фантастично, но този резултат е безполезен, ако пикът на трафика е в 2 следобед в петък, когато всички са онлайн.
За да получите истинска основа, трябва да тествате последователно с течение на времето. Смесете го:
- Извършвайте тестове по време на пикова бизнес активност.
- Планирайте някои за нощни поддръжки.
- Не забравяйте уикендите, когато трафикът може да бъде напълно различен.
Чрез многократно вземане на проби от данни можете да изгладите случайните върхове и спадове. Така откривате повтарящи се проблеми, като например мрежата да се задръства всеки работен ден след обяд.
Не забравяйте за джитър
Средната латентност е солидна отправна точка, но често крие по-зловещ проблем: джитър. Джитърът е просто вариацията на вашата латентност с времето. Помислете за това — стабилна връзка с предсказуема 80ms закъснение често е много по-добра за приложения в реално време от такава, която средно е 50ms, но скача драстично между 10ms и 200ms.
Джитърът е тихият убиец на потребителското изживяване за всичко в реално време, като VoIP обаждания, видео конференции или онлайн игри. Високият джитър е това, което причинява накъсване на звука, замръзване на видеото и дразнещи забавяния, които правят приложението да изглежда напълно счупено, дори когато средната латентност изглежда добра на хартия.
Разбирането на джитъра означава да погледнете отвъд средното. Това е незабележимият злодей, защото разкрива защо само средните стойности могат да бъдат толкова подвеждащи. Например, данни от Pandora FMS показват, че джитър над 30ms може да увеличи процента на загуба на пакети в игрите до 15% — достатъчно, за да направи играта непоносима. Измерването на стандартното отклонение на вашите резултати за латентност е първата стъпка към поставянето на число на тази нестабилност.
Контролен списък за проектиране на тест за латентност
За да обобщим всичко това, ето един бърз контролен списък, който да ви ръководи. Следването на тези стъпки ще помогне да се уверите, че данните, които събирате, са както точни, така и наистина полезни.
| Контролен елемент | Защо е важно | Действащ съвет |
|---|---|---|
| Определете ясни цели | Не можете да измервате това, което не определяте. Решавате ли конкретен проблем или установявате основа? | Запишете целта си преди да започнете. "Диагностицирайте забавянето за потребители в Югоизточна Азия" е по-добра цел от "проверете латентността." |
| Изберете разнообразни крайни точки | Един единствен път не представлява вашето глобално потребителско изживяване. | Изберете 3-5 места: едно местно, едно на друг континент и няколко в ключовите ви потребителски пазари. |
| Установете ритъм | Еднократните тестове пропускат времеви модели като задръствания в пиковите часове. | Планирайте тестовете да се изпълняват автоматично всеки час в продължение на седмица, за да уловите пълен цикъл на мрежовото поведение. |
| Измервайте джитър | Средните стойности крият непостоянната производителност, която разваля приложенията в реално време. | Не гледайте само на средния RTT. Изчислете стандартното отклонение или използвайте инструмент като mtr, който показва минимална/максимална/средна латентност. |
| Използвайте правилните инструменти | ping е добър за бърза проверка, но инструменти като mtr или iperf предоставят по-дълбоки прозрения. |
За уеб производителност използвайте инструментите за разработка на браузъра. За сурови мрежови пътища mtr е отличен избор. |
| Документирайте всичко | Ще забравите "защо" зад теста си след шест месеца. | Поддържайте прост дневник: дата, час, крайни точки, използван инструмент и кратка бележка за това, което сте наблюдавали. |
Като бъдете методични, преминавате от просто измерване на латентността към истинското й разбиране. Този внимателен подход е това, което отделя случайно число от надежден индикатор за производителност.
Как да разберем числата (и какво да избягваме)
Добре, провели сте тестовете си и имате куп данни. Тук започва истинската работа — превръщането на тези сурови числа в нещо, което наистина означава нещо. Данните разказват история за здравето на вашата мрежа; просто трябва да научите как да я прочетете.
Например, внезапен пик в времето за обратно пътуване (RTT) на traceroute е класически сигнал. Ако латентността скача на трето скок и остава висока до края, вероятно сте намерили проблема си: това е третият рутер или връзката точно след него. Но бъдете внимателни. Ако само този един скок показва висока латентност и крайната дестинация все още е бърза, може просто да е рутер, конфигуриран да приоритизира точно този вид трафик, който вашият тест използва. Това е често срещан фалшив сигнал, който може да ви изпрати в погрешна посока.
Разшифроване на джитър и загуба на пакети
Поглеждайки отвъд простия RTT, ще намерите най-критичните прозрения. Високият джитър, който е просто модерен термин за непостоянна латентност, може да бъде много по-разрушителен от латентността, която е последователно висока. Това е особено вярно за всичко в реално време.
Ако вашите резултати показват среден RTT от 40ms, но минималният е 10ms, а максималният е 150ms, вашата връзка е нестабилна. Тази огромна вариация е точно това, което причинява дразнещи забавяния в видео разговори и избухващи забавяния в онлайн игри.
Загубата на пакети е още по-голям червен флаг. Дори 1% загуба на пакети може напълно да парализира приложенията, базирани на TCP, принуждавайки ги постоянно да изпращат данни отново и забавяйки всичко до пълно спиране. Когато разглеждате резултатите от теста си, всяка реална разлика между изпратените и получените пакети трябва да бъде проучена незабавно.
Една от най-големите грешки, които виждам, е предположението, че един единствен тест разказва цялата история. Мрежовите условия постоянно се променят. Тест, проведен в 3 сутринта, ще изглежда напълно различно от такъв в 3 следобед по време на пикова бизнес активност. Единственият начин да получите истинска основа за производителност е чрез последователно, повторно тестване.
За да се справите с проблемите, си струва да разгледате специализирани инструменти за мониторинг на мрежовата производителност. Това променя подхода ви от паническо поправяне на нещата, когато се счупят, към проактивно поддържане на здравето на вашата мрежа.
Най-честите грешки при измерване
Дори с най-добрите инструменти в света, няколко прости грешки могат да направят резултатите ви напълно безполезни. Избягването на тези често срещани капани е задължително, ако искате данни, на които наистина да се доверите.
- Тестване през Wi-Fi: Наистина, просто не го правете. Безжичните връзки са известни с непостоянството си, податливи на смущения от всичко — от микровълнови печки до рутера на съседа. За всяко сериозно тестване на латентността, свържете се с Ethernet кабел. Това е единственият начин да получите стабилна, надеждна основа.
- Забравяне на VPN натоварването: VPN-ите са страхотни за сигурност, но добавят допълнителна спирка и криптиране в пътуването на вашия трафик. Това винаги увеличава латентността. Ако се опитвате да диагностицирате бавната връзка на потребителя, един от първите ви въпроси трябва да бъде: "На VPN ли сте?" Тестването с и без него ще ви покаже точно колко забавяне добавя.
- Игнориране на местната мрежова задръствания: Резултатите от теста ви ще бъдат изкривени, ако някой друг в мрежата ви заема цялата честотна лента. Ако колега стриймва 4K видео или изтегля огромни файлове, докато тествате, вашите числа за латентност ще бъдат завишени и ще се окажете, че преследвате проблем, който не съществува.
Друг фин, но критичен фактор е инструментът, който избирате. Както обсъдихме, различните утилити измерват латентността по различни начини. Винаги бъдете последователни с инструментите, които използвате за сравнение, и се уверете, че разбирате какво всъщност измерва всеки от тях — независимо дали е прост ICMP echo или сложна заявка на ниво приложение. И не забравяйте, че производителността може да бъде повлияна от много слоеве; например, ако се задълбочавате в уеб производителността, нашето ръководство за Cookie Editor Chrome Extension може да покаже как клиентските елементи играят роля.
Като интерпретирате резултатите си в правилния контекст и избягвате тези често срещани грешки, ще преминете отвъд просто събиране на числа. Ще започнете да разбирате защо зад производителността на вашата мрежа, и това е ключът към изграждането на по-бързи, по-надеждни системи.
Често задавани въпроси относно мрежовата латентност
Дори с правилните инструменти, няколко често задавани въпроса винаги изглежда, че се появяват, когато започнете да се задълбочавате в мрежовата латентност. Нека преминем през някои от най-честите, които чувам, за да ви помогнем да разберете резултатите си.
Какво всъщност е "добро" число за латентност?
Това е класическият въпрос "зависи", но определено можем да зададем някои солидни ориентири. "Добрата" латентност е напълно относителна на това, което се опитвате да постигнете.
- Случайно уеб сърфиране: За повечето от нас всичко под 100ms RTT ще се чувства напълно добре. Страниците се зареждат бързо и няма да забележите никакво реално забавяне.
- Конкурентни онлайн игри: Тук всяка милисекунда има значение. Сериозните геймъри и търговците с висока честота търсят латентност значително под 20ms. Това е разликата между победата и загубата.
- Видео обаждания и VoIP: Тук последователността е крал. Нуждаете се от стабилна латентност под 150ms и нисък джитър (по-малко от 30ms), за да избегнете онова накъсано, несинхронизирано усещане или, още по-лошо, загубени обаждания.
Като правило, повечето мрежови специалисти, които познавам, биха класифицирали всичко под 50ms като ниска латентност. От 50-150ms е умерена, а след като преминете 150ms, ще започнете да усещате забавянето при повечето интерактивни приложения.
Защо резултатите от моя ping и теста за скорост на браузъра никога не съвпадат?
Това е страхотен въпрос и много често срещана точка на объркване. Това се случва, защото командният ред ping и тестът за скорост на браузъра са по същество различни инструменти, измерващи различни неща.
Първо, почти със сигурност говорят с различни сървъри. Когато ping даден домейн, вие удряте конкретна цел. Тестът за уеб скорост, от друга страна, е проектиран да намери географски близък сървър от собствената си мрежа, за да ви предостави най-добрия възможен резултат.
Протоколите също са напълно различни. Ping използва много лек протокол, наречен ICMP. Повечето тестове на браузъра работят през TCP, което изисква цял процес на настройка (т.нар. "тристранно ръкостискане"), само за да се установи връзка. Тази първоначална размяна добавя малко време преди реалният тест дори да започне.
Накрая, тестовете на браузъра често включват повече от просто чистото време за пътуване в мрежата. Номерата им за "латентност" могат да включват времето за обработка на сървъра или дори малки забавяния в самия браузър, което може да увеличи крайната стойност в сравнение с чист ICMP ping.
Как мога наистина да намаля мрежовата си латентност?
Намаляването на латентността е свързано с откриването и премахването на тесните места, независимо дали са в офиса ви или в интернет.
Първото място, на което да се огледате, е вашата непосредствена среда. Най-ефективната промяна, която можете да направите, е да преминете от Wi-Fi към жично Ethernet свързване. Това е истинска революция за стабилността и скоростта. Ако трябва да използвате Wi-Fi, приближете се до рутера си и се свържете с 5GHz честотната лента, ако можете - обикновено е по-малко натоварена.
Ако погледнете извън локалната си мрежа, понякога смяната на DNS може да помогне. Използването на по-бърз DNS сървър може да намали времето за първоначално свързване с милисекунди, когато търсите уебсайт.
Ако се опитвате да подобрите достъпа до услуга, която контролирате, мрежата за доставка на съдържание (CDN) е отговорът. Тя работи, като поставя копия на съдържанието ви физически по-близо до потребителите ви. И ако използвате VPN, опитайте да го изключите. Това допълнително скок и слой на криптиране почти винаги добавят латентност.
Съществуват корпоративни VPN, които добавят до 70ms към времето за връщане. Това може да превърне отлична връзка в изключително бавна. Винаги тествайте с и без вашия VPN, за да видите какъв вид производителност всъщност губите.
Каква е истинската разлика между латентност и пропускателна способност?
Правилното разбиране на това е основополагающе за разбирането на производителността на мрежата. Лесно е да ги объркате, но те измерват две много различни неща.
Ето аналогията, която винаги използвам: помислете за това като за магистрала.
- Пропускателна способност е колко ленти има магистралата. Повече ленти означават, че повече коли (данни) могат да пътуват едновременно.
- Латентност е ограничението на скоростта. То определя колко бързо една кола (пакет от данни) може да стигне от А до Б.
Можете да имате огромна магистрала с десет ленти (огромна пропускателна способност) с ограничение на скоростта от 20 mph (висока латентност). Можете да прехвърлите много данни в крайна сметка, но неща в реално време, като видео разговор, биха били болезнено бавни. От друга страна, връзка с много ниска латентност изглежда изключително бърза и отзивчива, дори ако пропускателната й способност не е огромна. Наистина е необходимо добро балансирано съотношение между двете за отличен опит.
Готови ли сте да направите тестването на производителността безпроблемна част от ежедневния си работен процес? Комплектът ShiftShift Extensions предлага мощен Speed Test, JSON форматиращ инструмент и десетки други инструменти за разработчици директно в браузъра ви, достъпни с една команда. Спирайте да жонглирате с табове и започнете да работите по-умно. Изтеглете ShiftShift Extensions безплатно и увеличете продуктивността си днес.