Wie man Netzwerkverzögerung misst: Ein praktischer Leitfaden für Entwickler
Erfahren Sie, wie Sie die Netzwerkverzögerung mit diesem umfassenden Leitfaden messen können. Wir behandeln wichtige Werkzeuge wie Ping und Traceroute sowie browserbasierte Testtechniken.

Empfohlene Erweiterungen
Sie möchten die Netzwerklatenz messen? Sie können mit einfachen, integrierten Befehlszeilentools wie ping und traceroute beginnen, um einen schnellen Überblick über die Round-Trip Time (RTT) zu erhalten. Oder Sie können die Entwicklertools Ihres Browsers öffnen, um zu sehen, wie Verzögerungen das tatsächliche Nutzererlebnis beeinflussen.
Diese Methoden geben Ihnen einen schnellen, nützlichen Überblick darüber, wie lange es dauert, bis ein Datenpaket von einer Quelle zu einem Ziel reist und wieder zurück.
Warum die Messung der Latenz unverzichtbar ist
Bevor wir ins „Wie“ eintauchen, lassen Sie uns über das „Warum“ sprechen. Für Entwickler und Netzwerkingenieure ist Latenz nicht nur eine Zahl auf einem Bildschirm; sie ist die unsichtbare Hand, die das gesamte Nutzererlebnis prägt. In den heutigen Anwendungen sind Millisekunden alles. Selbst eine kleine Verzögerung kann den Unterschied zwischen einem Dienst ausmachen, der sofort wirkt, und einem, der defekt erscheint.
Denken Sie an die realen Konsequenzen:
- API-Reaktionsfähigkeit: Ein einzelner langsamer API-Aufruf kann einen Dominoeffekt auslösen, der alles von der Ladezeit eines Benutzerprofils bis zur Verarbeitung einer kritischen Zahlung aufhält.
- Echtzeit-Datenströme: Für Online-Spiele, Live-Video oder Finanzhandel ist eine niedrige und konstante Latenz die absolute Grundlage. Ohne sie funktionieren diese Anwendungen einfach nicht.
- Nutzerbindung: Es gibt eine direkte Verbindung zwischen langsam ladenden Websites und Apps und höheren Absprungraten sowie abgebrochenen Warenkörben. Das wirkt sich stark auf das Endergebnis aus.
Wichtige Latenzkonzepte unterscheiden
Um die Netzwerklatenz genau zu messen, müssen Sie wissen, was Sie betrachten. Die beiden grundlegendsten Konzepte sind Round-Trip Time (RTT) und Einweg-Latenz.
RTT ist die Gesamtzeit, die ein Signal benötigt, um von Punkt A nach Punkt B und zurück zu gelangen. Es ist die häufigste Metrik, die Sie sehen werden, da sie einfach zu messen ist – Sie benötigen nur Zugang zu einem Ende der Verbindung.
Einweg-Latenz misst, wie lange es dauert, bis Daten in nur eine Richtung reisen. Dies ist eine viel schwierigere Messung, da sie perfekt synchronisierte Uhren an beiden Endpunkten erfordert. Sie ist jedoch ein viel präziserer Indikator für asymmetrische Verbindungen, bei denen sich Ihre Upload- und Downloadpfade sehr unterschiedlich verhalten.
Die Bedeutung all dessen wird klar, wenn Sie ernsthafte Lastleistungsprüfungen durchführen, wo Theorie auf Realität trifft und Engpässe aufgedeckt werden.
Um einige Zahlen zu nennen, klassifizieren Netzwerküberwachungsexperten Latenz in der Regel wie folgt:
- Niedrige Latenz: Unter 50 Millisekunden
- Moderate Latenz: 50-150 ms
- Hohe Latenz: Über 150 ms
Aus meiner Erfahrung kann ein schneller Test zu einem nahegelegenen Server eine völlig akzeptable 20-40 ms zeigen. Aber diese Zahl kann leicht auf über 200 ms ansteigen, wenn der Datenverkehr einen Ozean überqueren muss, was die Leistung Ihrer Anwendung erheblich beeinträchtigen kann.
Um den Fachjargon, dem Sie begegnen werden, zu verstehen, hier ist ein schneller Überblick.
Wichtige Latenzkonzepte auf einen Blick
| Konzept | Was es misst | Warum es wichtig ist |
|---|---|---|
| Latenz (Ping) | Die Zeit, die benötigt wird, damit ein einzelnes Datenpaket von einer Quelle zu einem Ziel und zurück reist. Gemessen in Millisekunden (ms). | Dies ist das rohe Maß für Verzögerung. Niedrige Latenz ist entscheidend für Echtzeitanwendungen wie Gaming, VoIP und Videokonferenzen. |
| Round-Trip Time (RTT) | Im Wesentlichen dasselbe wie Latenz, dies ist die Gesamtdauer, die benötigt wird, um ein Signal zu senden, plus die Zeit, die benötigt wird, um eine Bestätigung zu erhalten. | RTT ist die gängigste und praktischste Methode zur Messung der Latenz von einem einzelnen Punkt aus, was es zur bevorzugten Metrik für Tools wie ping macht. |
| Einweg-Latenz | Die Zeit, die benötigt wird, damit ein Paket von der Quelle zum Ziel in eine einzige Richtung reist. | Bietet eine detailliertere Sicht, insbesondere für asymmetrische Netzwerke, bei denen Upload- und Downloadpfade unterschiedliche Latenzen aufweisen. |
| Jitter | Die Variation der Latenz über die Zeit. Es misst die Inkonsistenz der Ankunftszeiten von Paketen. | Hoher Jitter ist ebenso schlecht wie hohe Latenz für Streaming-Medien und Online-Anrufe, da er zu Ruckeln, Puffern und Störungen führt. |
| Bandbreite | Die maximale Menge an Daten, die über eine Netzwerkverbindung in einem bestimmten Zeitraum übertragen werden kann. Gemessen in Mbps oder Gbps. | Oft mit Geschwindigkeit verwechselt, bezieht sich die Bandbreite auf die Kapazität. Sie können eine hohe Bandbreite haben, aber dennoch unter hoher Latenz leiden. |
Diese Konzepte sind die Bausteine für das Verständnis von Netzwerkleistungsproblemen.
Hier wird es wichtig, zugängliche, integrierte Tools zu haben. Anstatt komplexe Diagnosetools auszuführen, können moderne Browsererweiterungen und Entwicklungstools Ihnen die Einblicke geben, die Sie benötigen, ohne Ihren Arbeitsablauf zu verlassen. Es geht darum, die Messung der Latenz zu einem mühelosen, routinemäßigen Teil der Entwicklung und Wartung großartiger Software zu machen.
Mit Befehlszeilen-Latenztools ins Detail gehen
Um wirklich ein Gefühl für die Leistung Ihres Netzwerks zu bekommen, müssen Sie das Terminal öffnen. Die Befehlszeile ist der Ort, an dem Sie die grundlegenden Tools finden, die Ihnen rohe, ungefilterte Daten über Ihre Verbindung liefern. Es geht darum, zu sehen, was wirklich mit den Paketen passiert, die zwischen Ihnen und einem Ziel bewegt werden, und es ist der wesentliche erste Schritt für jeden Entwickler, der ernsthaft die Latenz messen möchte.
Das klassische, bewährte Tool ist ping. Es ist wunderschön einfach: Es sendet ein kleines Datenpaket (eine ICMP-Echo-Anfrage) an einen Server und wartet einfach darauf, dass es zurückkommt. Diese einfache Hin- und Rückreise ist die Grundlage für die Berechnung der Round-Trip Time (RTT) und gibt Ihnen einen sofortigen Gesundheitscheck einer Verbindung.
Ihr erster Latenztest mit Ping
Ein ping-Test könnte nicht einfacher sein. Starten Sie Ihr Terminal oder die Eingabeaufforderung, geben Sie ping ein und folgen Sie es mit der Domain, die Sie testen möchten.
Standardmäßig wird ping unter macOS und Linux unendlich weiterlaufen, während Windows nur vier Pakete sendet und stoppt. Für eine echte Analyse möchten Sie dies steuern. Das Senden von zehn oder zwanzig Paketen gibt Ihnen ein viel zuverlässigeres Bild von der Stabilität der Verbindung als nur ein paar.
Sobald es abgeschlossen ist, erhalten Sie eine übersichtliche Zusammenfassung mit den entscheidenden Zahlen:
- Übertragene/Empfangene Pakete: Dies zeigt Ihnen, ob auf dem Weg Daten verloren gegangen sind. Selbst eine kleine Menge an Paketverlust ist ein großes Warnsignal für Netzwerkprobleme.
- Round-Trip min/avg/max/mdev: Dies sind Ihre Kernlatenzstatistiken. Sie erhalten die bestmögliche Zeit (
min), den Durchschnitt (avg) und die schlechteste Zeit (max). Dermdev(mittlere Abweichung) ist Ihr Maß für Jitter – wie stark die Latenz von einem Paket zum nächsten variiert.
Achten Sie genau auf die Lücke zwischen Ihrer minimalen und maximalen RTT. Wenn sie groß ist, ist Ihre Verbindung instabil, selbst wenn der Durchschnitt in Ordnung aussieht. Dieser Jitter kann für Echtzeitanwendungen wie Videoanrufe oder Gaming viel störender sein als eine Verbindung, die konstant etwas langsam ist.
Ein häufiger Fehler ist es, nur einen Blick auf die durchschnittliche RTT zu werfen. Ein Durchschnitt von 50 ms mag in Ordnung erscheinen, aber wenn Ihre minimale 20 ms und Ihre maximale 250 ms beträgt, wird das Nutzererlebnis ruckelig und unzuverlässig erscheinen. Achten Sie immer auf den gesamten Bereich, um den Jitter zu verstehen.
Der Spur mit Traceroute und MTR folgen
Was tun Sie also, wenn ping hohe Latenz oder Paketverlust aufdeckt? Ihre nächste Aufgabe besteht darin, herauszufinden, wo das Problem liegt. Dafür ist traceroute (oder tracert unter Windows) gedacht. Es kartiert den gesamten Pfad, den Ihre Pakete nehmen, und zeigt Ihnen jeden einzelnen „Hop“ – jeden Router – zwischen Ihrem Gerät und dem endgültigen Ziel.
Jede Zeile in der traceroute-Ausgabe ist ein Hop, und sie zeigt normalerweise drei separate Latenzmessungen bis zu diesem Punkt. Dies ermöglicht es Ihnen, genau zu bestimmen, ob ein bestimmter Router auf dem Weg eine erhebliche Verlangsamung verursacht oder Pakete verliert.
Aber traceroute ist eine einmalige Momentaufnahme. Für einen dynamischeren, kontinuierlichen Blick schwören die meisten Netzwerkprofis, die ich kenne, auf MTR (My Traceroute). MTR ist wie ein aufgeladenes Tool, das ping und traceroute kombiniert. Es sendet ständig Pakete zu jedem Hop auf der Route und gibt Ihnen eine live aktualisierte Ansicht von Latenz und Paketverlust an jedem einzelnen Punkt. Dies macht es unglaublich effektiv, um intermittierende Probleme zu erfassen, die ein einzelnes traceroute wahrscheinlich übersehen würde.
Warum Ihre Werkzeugwahl wichtig ist
Das Tool, das Sie wählen, und wie Sie es konfigurieren, können Ihre Ergebnisse drastisch verändern. Dies gilt insbesondere in ultraschnellen, latenzarmen Umgebungen wie Cloud-Rechenzentren.
Es ist tatsächlich ziemlich aufschlussreich, wie unterschiedlich die Zahlen sein können. In einem detaillierten Experiment, das von Google Cloud durchgeführt wurde, berichtete ein standardmäßiger ping-Test von einer durchschnittlichen RTT von 146 Mikrosekunden. Aber als sie ein anderes Tool verwendeten, das Transaktionen ohne Pause hintereinander sendet, fiel die RTT auf nur 66,59 Mikrosekunden – mehr als doppelt so schnell!
Dies ist ein perfektes Beispiel dafür, warum ping manchmal die Latenz überschätzen kann. Es zeigt, dass es entscheidend ist, zu verstehen, wie ein Tool funktioniert, um Messungen zu erhalten, denen Sie vertrauen können.
Die maximale Geschwindigkeit Ihrer Verbindung mit iperf finden
Latenz ist nicht immer das gesamte Bild. Manchmal müssen Sie wissen, wie viel Daten Ihre Verbindung tatsächlich durchschieben kann – ihre Bandbreite. Für diese Aufgabe ist das Tool, das Sie benötigen, iperf.
Während ping die Verzögerung misst, dreht sich bei iperf alles um den Durchsatz. Es funktioniert, indem es eine Client-Server-Verbindung einrichtet und dann so viele Daten wie möglich zwischen ihnen für einen festgelegten Zeitraum überträgt.
Um iperf zu verwenden, benötigen Sie zwei Maschinen:
- Auf einer Maschine führen Sie
iperfim Servermodus aus. Es wird einfach dort sitzen und auf eine Verbindung warten. - Auf der anderen Maschine führen Sie
iperfim Clientmodus aus und zeigen auf die Adresse des Servers.
Der Client wird sich verbinden und der Test beginnt. Die Ausgabe zeigt Ihnen die insgesamt übertragenen Daten und, was am wichtigsten ist, die Bitrate (Ihre Bandbreite) in Megabit oder Gigabit pro Sekunde. Es ist der perfekte Weg, um eine Netzwerkverbindung auf die Probe zu stellen und herauszufinden, was sie wirklich leisten kann.
Die Latenz aus der Perspektive des Nutzers messen
Während Befehlszeilentools Ihnen einen rohen, ungefilterten Blick auf Ihr Netzwerk geben, ist die einzige Latenz, die für eine Webanwendung wirklich zählt, das, was der Endnutzer tatsächlich erlebt. Hier verlagern wir unseren Fokus vom Terminal auf den Browser selbst. Was im Browser passiert, erzählt eine viel reichhaltigere, relevantere Geschichte über die Leistung.
Es geht nie nur um die Hin- und Rückreise eines einzelnen Pakets. Die Latenz, die ein Nutzer fühlt, ist ein komplexer Cocktail aus DNS-Abfragen, TCP-Handshakes, TLS-Verhandlungen, Serververarbeitungszeit und natürlich der Zeit, die benötigt wird, um den Inhalt tatsächlich auf dem Bildschirm darzustellen. Glücklicherweise sind moderne Browser mit leistungsstarken integrierten Tools ausgestattet, die uns helfen, diesen gesamten Prozess zu analysieren.
In die Entwicklertools des Browsers eintauchen
Jeder große Browser – Chrome, Firefox, Edge, Safari – ist mit einer Suite von Entwicklertools ausgestattet. Der Tab „Netzwerk“ innerhalb dieser Tools ist Ihr Kommandocenter, um zu verstehen, wie Ihre Seite geladen wird. Er legt alles in einem Wasserfall-Diagramm dar, das eine visuelle Aufschlüsselung jeder einzelnen Anfrage zeigt, die der Browser zur Darstellung einer Seite stellt.
Diese Wasserfallansicht ist von unschätzbarem Wert. Sie können genau sehen, wie lange jeder Asset benötigt hat, um heruntergeladen zu werden, vom ursprünglichen HTML-Dokument und CSS-Stylesheets bis hin zu Bildern und API-Aufrufen. Noch wichtiger ist, dass sie den Lebenszyklus jeder Anfrage in verschiedene Phasen unterteilt:
- DNS-Abfrage: Die Zeit, die benötigt wird, um einen Domainnamen in eine IP-Adresse aufzulösen.
- Erste Verbindung: Die Zeit, die für die Herstellung einer TCP-Verbindung mit dem Server aufgewendet wird.
- SSL/TLS-Handshake: Der Overhead, der erforderlich ist, um eine sichere Verbindung einzurichten.
- Time to First Byte (TTFB): Dies ist ein großer Punkt. Es misst, wie lange der Browser gewartet hat, bevor er das allererste Byte Daten vom Server erhalten hat.
- Inhaltsdownload: Die Zeit, die tatsächlich für den Download der Ressource selbst benötigt wird.
Eine hohe TTFB ist beispielsweise ein klassisches Zeichen für ein langsames Backend oder ein serverseitiges Verarbeitungsproblem – etwas, das ein einfacher ping-Test niemals aufdecken würde. Durch die Analyse dieses Wasserfalls können Sie schnell erkennen, welche Ressourcen das Rendering blockieren oder einfach viel zu lange zum Laden benötigen.
Eine wichtige Erkenntnis aus meiner Erfahrung ist, nicht nur die gesamte Ladezeit zu betrachten, sondern nach den längsten Balken im Wasserfall zu suchen. Ein einzelnes nicht optimiertes Bild oder eine langsame Drittanbieter-API kann die gesamte Seite in Geiselhaft nehmen und ein schlechtes Nutzererlebnis schaffen, selbst wenn der Rest der Seite blitzschnell ist.
Programmgesteuerte Messung mit Timing-APIs
Für automatisiertere und präzisere Messungen können Sie auf die integrierten JavaScript-APIs des Browsers zugreifen. Die Navigation Timing API und die Resource Timing API geben Ihnen programmgesteuerten Zugriff auf dieselben detaillierten Leistungsdaten, die Sie in den Entwicklertools sehen. Dies ist perfekt, um Daten für das Real User Monitoring (RUM) zu sammeln, um zu verstehen, wie Ihre Seite für tatsächliche Besucher weltweit funktioniert.
Sie können diese Metriken mit nur wenigen Zeilen JavaScript direkt in der Browser-Konsole abrufen. Um beispielsweise die Kernleistungszeiten für das Laden der Hauptseite zu erhalten, können Sie performance.getEntriesByType('navigation') verwenden. Dies gibt ein Objekt zurück, das mit wertvollen Zeitstempeln gefüllt ist.
Aus diesen Daten können Sie wichtige Metriken berechnen:
- DNS-Abfragezeit:
domainLookupEnd - domainLookupStart - TCP-Handshake-Zeit:
connectEnd - connectStart - Time to First Byte (TTFB):
responseStart - requestStart - Gesamte Ladezeit der Seite:
loadEventEnd - startTime
Dieser Ansatz ermöglicht es Ihnen, benutzerdefinierte Dashboards zu erstellen oder Leistungsdaten an Ihre Analysetools zu senden, sodass Sie einen kontinuierlichen Puls auf die reale Leistung Ihrer Anwendung haben. In der Webentwicklung ist die Optimierung von Bildern eine gängige Methode, um diese Kennzahlen zu verbessern; für Interessierte haben wir einen hilfreichen Leitfaden zur Auswahl des besten Bildformats für Ihre Website.
Überprüfung mit integrierten Tools optimieren
Das ständige Wechseln zwischen Terminal, Browser-Entwicklertools und benutzerdefinierten Skripten kann schnell lästig werden. Hier können integrierte Browsererweiterungen Ihren Workflow erheblich verbessern, indem sie diese Überprüfungen vereinheitlichen. Beispielsweise umfasst die ShiftShift Extensions-Suite ein integriertes Speed Test-Tool, das Sie sofort aus jedem Tab öffnen können.
Dies bietet Ihnen eine schnelle, datenschutzorientierte Möglichkeit, die Downloadgeschwindigkeit, Uploadgeschwindigkeit und Latenz Ihrer Verbindung zu messen, ohne eine separate Website aufrufen oder ein Terminal öffnen zu müssen. Da es Teil eines größeren Werkzeugkastens ist, können Sie einen Geschwindigkeitstest durchführen, eine JSON-Antwort formatieren und ein Cookie überprüfen, alles aus demselben einheitlichen Befehlsmenü. Diese Art der Integration macht Leistungsüberprüfungen zu einem natürlichen, reibungslosen Teil des täglichen Entwicklungsprozesses.
Wie man einen Latenztest entwirft, der tatsächlich etwas aussagt
Jeder kann einen ping-Befehl ausführen und eine Zahl zurückbekommen. Aber wenn Sie Daten wollen, denen Sie tatsächlich vertrauen können – Daten, die Ihnen helfen, echte Entscheidungen zu treffen – müssen Sie gezielter vorgehen. Eine einzelne, isolierte Messung ist nur ein Schnappschuss zu einem bestimmten Zeitpunkt. Um das Verhalten Ihres Netzwerks wirklich zu verstehen, müssen Sie wie ein Detektiv denken und berücksichtigen, von wo aus Sie testen, wie oft Sie testen und wonach Sie wirklich suchen.
Ein gut gestalteter Test verwandelt rohe Zahlen in umsetzbare Erkenntnisse. Ein schlecht gestalteter? Es ist einfach nur Lärm.
Das Diagramm unten zeigt alle kleinen Verzögerungen, die sich zu dem summieren, was ein Benutzer beim Laden einer Webseite fühlt. Es ist eine großartige Erinnerung daran, dass ein einfacher Netzwerk-Ping nicht einmal ansatzweise die ganze Geschichte erzählt.
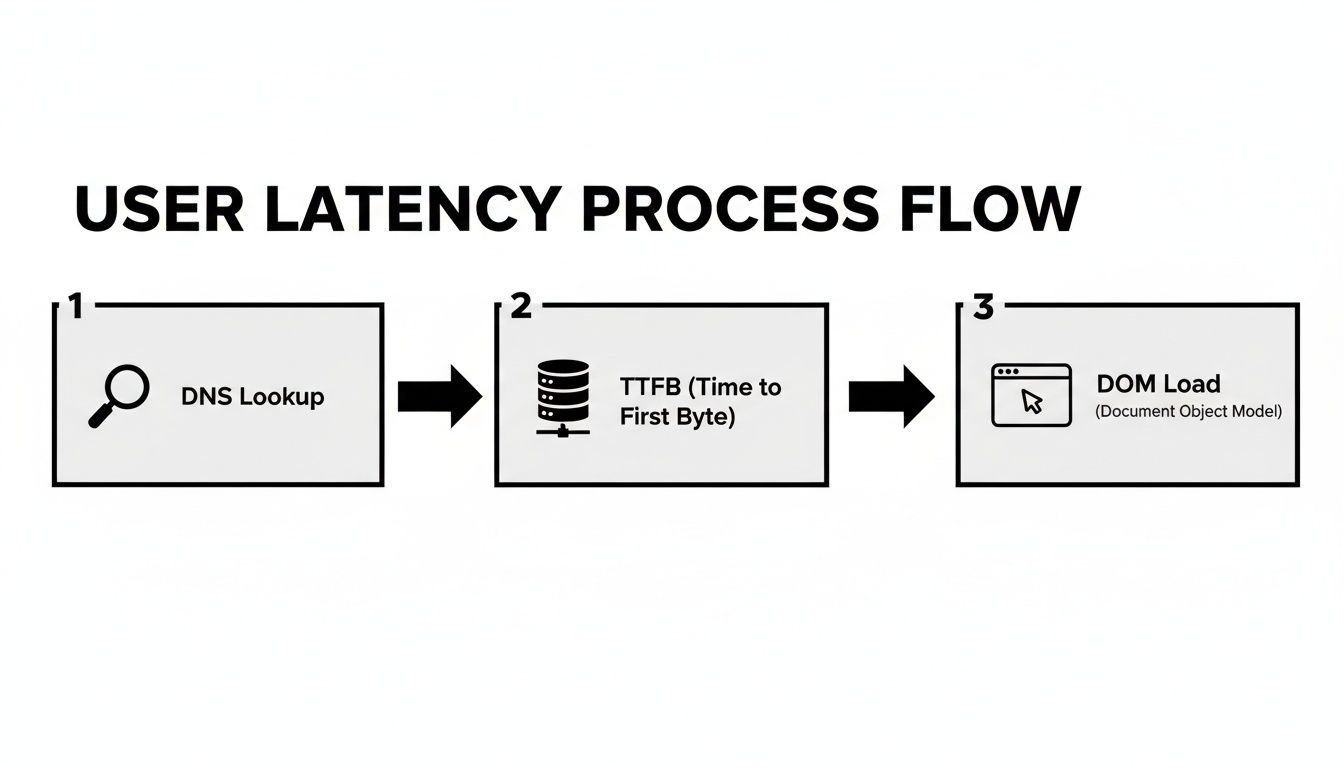
Wie Sie sehen können, tragen mehrere Schritte von der ursprünglichen DNS-Abfrage bis zur endgültigen Darstellung zur gesamten Wartezeit bei.
Wählen Sie Ihre Testendpunkte
Die erste Regel für zuverlässige Tests ist, dass Geografie wichtig ist. Ein Test von Ihrem Büro in New York zu einem Server um die Ecke in New Jersey sagt Ihnen absolut nichts über die Erfahrung Ihrer Kunden in Tokio. Um ein realistisches Bild zu erhalten, müssen Sie von verschiedenen Standorten testen, die tatsächlich Ihre Benutzerbasis widerspiegeln.
Ihre Liste von Endpunkten sollte einige wichtige Bereiche abdecken:
- Ihre größten Benutzerzentren: Wo leben die meisten Ihrer Kunden? Testen Sie von dort.
- Kontinentalübergreifende Pfade: Sehen Sie, was passiert, wenn Daten einen Ozean überqueren müssen. Testen Sie zwischen Europa und Nordamerika oder Asien und den USA, um die Leistung auf langen Strecken zu verstehen.
- Ihre Cloud-Regionen: Wenn Sie AWS, Azure oder GCP verwenden, testen Sie die Konnektivität zu und zwischen den spezifischen Rechenzentrumsregionen, auf die Sie angewiesen sind.
Indem Sie Ihre Tests auf diese Weise verteilen, erstellen Sie eine viel genauere Karte der globalen Leistung. Es hilft Ihnen, regionsspezifische Engpässe zu erkennen, die Sie sonst völlig übersehen würden. Dies ist auch ein guter Moment, um Ihre Domain-Einrichtung zu überprüfen; Sie finden hilfreiche Tipps dazu, wie Sie die Verfügbarkeit von Domains überprüfen und verwandte Konfigurationen, um sicherzustellen, dass alles in Ordnung ist.
Den richtigen Testrhythmus finden
Die Netzwerkbedingungen sind ständig im Fluss. Sie ändern sich im Laufe des Tages, der Woche und sogar der Minute. Ein Test, der um 3 Uhr morgens an einem Dienstag durchgeführt wird, könnte fantastisch aussehen, aber dieses Ergebnis ist nutzlos, wenn Ihr Spitzenverkehr um 14 Uhr an einem Freitag auftritt, wenn alle online sind.
Um eine echte Basislinie zu erhalten, müssen Sie über einen längeren Zeitraum hinweg konsistent testen. Variieren Sie:
- Führen Sie Tests während der Hauptgeschäftszeiten durch.
- Planen Sie einige für nächtliche Wartungsfenster.
- Vergessen Sie nicht die Wochenenden, an denen die Verkehrsmuster völlig anders sein können.
Durch wiederholtes Sampling von Daten können Sie die zufälligen Spitzen und Einbrüche glätten. So erkennen Sie wiederkehrende Probleme, wie z. B. dass das Netzwerk jeden Wochentagnachmittag direkt nach dem Mittagessen überlastet ist.
Vergessen Sie nicht den Jitter
Die durchschnittliche Latenz ist ein solider Ausgangspunkt, aber sie verbirgt oft ein viel heimtückischeres Problem: Jitter. Jitter ist einfach die Variation Ihrer Latenz über die Zeit. Denken Sie darüber nach – eine stabile Verbindung mit einer vorhersehbaren 80ms Verzögerung ist oft viel besser für Echtzeitanwendungen als eine, die im Durchschnitt 50ms beträgt, aber wild zwischen 10ms und 200ms schwankt.
Jitter ist der stille Killer der Benutzererfahrung für alles, was in Echtzeit geschieht, wie VoIP-Anrufe, Videokonferenzen oder Online-Spiele. Hoher Jitter verursacht ruckelnden Audio, eingefrorenes Video und frustrierende Verzögerungsspitzen, die eine Anwendung völlig kaputt erscheinen lassen, selbst wenn die durchschnittliche Latenz auf dem Papier gut aussieht.
Jitter zu verstehen bedeutet, über den Durchschnitt hinauszuschauen. Es ist der unbesungene Bösewicht, weil er aufzeigt, warum Durchschnittswerte allein so irreführend sein können. Beispielsweise zeigen Daten von Pandora FMS, dass Jitter über 30ms die Paketverlustquoten im Gaming auf 15% erhöhen kann – genug, um ein Spiel unspielbar zu machen. Die Messung der Standardabweichung Ihrer Latenzwerte ist der erste Schritt, um eine Zahl für diese Instabilität zu erhalten.
Checkliste für das Design von Latenztests
Um all dies zusammenzufassen, hier ist eine schnelle Checkliste, die Ihnen als Leitfaden dient. Wenn Sie diese Schritte befolgen, stellen Sie sicher, dass die gesammelten Daten sowohl genau als auch wirklich nützlich sind.
| Checklistenpunkt | Warum es wichtig ist | Umsetzbarer Tipp |
|---|---|---|
| Klare Ziele definieren | Sie können nicht messen, was Sie nicht definieren. Beheben Sie ein spezifisches Problem oder stellen Sie eine Basislinie auf? | Schreiben Sie Ihr Ziel auf, bevor Sie beginnen. "Diagnose von Verzögerungen für Benutzer in Südostasien" ist ein besseres Ziel als "Latenz überprüfen." |
| Vielfältige Endpunkte auswählen | Ein einzelner Pfad repräsentiert nicht Ihre globale Benutzererfahrung. | Wählen Sie 3-5 Standorte: einen lokal, einen auf einem anderen Kontinent und einige in Ihren wichtigsten Benutzer-Märkten. |
| Eine Frequenz festlegen | Einmalige Tests verpassen zeitbasierte Muster wie Überlastungen zu Stoßzeiten. | Planen Sie Tests, die automatisch jede Stunde eine Woche lang durchgeführt werden, um einen vollständigen Zyklus des Netzwerkverhaltens zu erfassen. |
| Jitter messen | Durchschnittswerte verbergen die unberechenbare Leistung, die Echtzeitanwendungen ruiniert. | Schauen Sie sich nicht nur die durchschnittliche RTT an. Berechnen Sie die Standardabweichung oder verwenden Sie ein Tool wie mtr, das min/max/avg Latenz anzeigt. |
| Die richtigen Tools verwenden | ping ist gut für eine schnelle Überprüfung, aber Tools wie mtr oder iperf bieten tiefere Einblicke. |
Für die Webleistung verwenden Sie die Entwicklertools des Browsers. Für rohe Netzwerkpfade ist mtr eine großartige Wahl. |
| Alles dokumentieren | Sie werden das "Warum" hinter Ihrem Test in sechs Monaten vergessen. | Führen Sie ein einfaches Protokoll: Datum, Uhrzeit, Endpunkte, verwendetes Tool und eine kurze Notiz zu Ihren Beobachtungen. |
Indem Sie methodisch vorgehen, bewegen Sie sich von der bloßen Messung der Latenz hin zu einem echten Verständnis dafür. Dieser durchdachte Ansatz trennt eine zufällige Zahl von einem zuverlässigen Leistungsindikator.
Die Zahlen verstehen (und was zu vermeiden ist)
Okay, Sie haben Ihre Tests durchgeführt und einen Haufen Daten. Hier beginnt die eigentliche Arbeit – diese rohen Zahlen in etwas zu übersetzen, das tatsächlich Bedeutung hat. Die Daten erzählen Ihnen eine Geschichte über die Gesundheit Ihres Netzwerks; Sie müssen nur lernen, sie zu lesen.
Ein plötzlicher Anstieg der Round-Trip-Zeit (RTT) bei einem traceroute ist beispielsweise ein klassischer Hinweis. Wenn die Latenz bei Sprung Nummer drei ansteigt und bis zum Ende hoch bleibt, haben Sie wahrscheinlich Ihr Problem gefunden: Es ist der dritte Router oder die Verbindung direkt danach. Aber seien Sie vorsichtig. Wenn nur dieser einzelne Sprung eine hohe Latenz zeigt und das endgültige Ziel immer noch schnell ist, könnte es sich nur um einen Router handeln, der so konfiguriert ist, dass er genau die Art von Verkehr, die Ihr Test verwendet, herabpriorisiert. Es ist ein häufiger Fehlalarm, der Sie in ein Kaninchenloch führen kann.
Jitter und Paketverlust entschlüsseln
Über die einfache RTT hinauszuschauen, ist der Ort, an dem Sie die kritischsten Erkenntnisse finden. Hoher Jitter, was einfach ein schickes Wort für inkonsistente Latenz ist, kann viel disruptiver sein als eine konstant hohe Latenz. Dies gilt insbesondere für alles, was in Echtzeit geschieht.
Wenn Ihre Ergebnisse eine durchschnittliche RTT von 40ms zeigen, aber das Minimum 10ms und das Maximum 150ms betrug, ist Ihre Verbindung instabil. Diese massive Varianz ist genau das, was störende Ruckler bei Videoanrufen und frustrierende Verzögerungsspitzen in Online-Spielen verursacht.
Paketverlust ist ein noch größerer Alarm. Selbst 1% Paketverlust kann TCP-basierte Anwendungen völlig lahmlegen, indem sie gezwungen werden, ständig Daten erneut zu senden und alles zum Stillstand zu bringen. Wenn Sie Ihre Testergebnisse betrachten, muss jeder echte Unterschied zwischen gesendeten und empfangenen Paketen sofort untersucht werden.
Einer der größten Fehler, den ich bei Menschen sehe, ist die Annahme, dass ein einzelner Test die ganze Geschichte erzählt. Die Netzwerkbedingungen ändern sich ständig. Ein Test, der um 3 Uhr morgens durchgeführt wird, sieht völlig anders aus als einer um 15 Uhr während der Hauptgeschäftszeiten. Der einzige Weg, um eine echte Leistungsbasislinie zu erhalten, ist durch konsistentes, wiederholtes Testen.
Um Problemen zuvorzukommen, lohnt es sich, in spezielle Tools für Netzwerkleistungsüberwachung zu investieren. Dies verschiebt Ihren Ansatz von hektischem Reparieren, wenn etwas kaputt geht, zu proaktivem Halten Ihres Netzwerks gesund.
Die häufigsten Messfehler
Selbst mit den besten Tools der Welt können einige einfache Fehler Ihre Ergebnisse völlig nutzlos machen. Diese häufigen Fallstricke zu vermeiden, ist unverzichtbar, wenn Sie Daten wollen, denen Sie tatsächlich vertrauen können.
- Über Wi-Fi testen: Ernsthaft, tun Sie es einfach nicht. Drahtlose Verbindungen sind notorisch launisch und anfällig für Störungen durch alles, von Mikrowellen bis zum Router Ihres Nachbarn. Für ernsthafte Latenztests sollten Sie mit einem Ethernet-Kabel anschließen. Es ist der einzige Weg, um eine stabile, zuverlässige Basislinie zu erhalten.
- VPN-Overhead vergessen: VPNs sind großartig für die Sicherheit, aber sie fügen Ihrer Verbindung einen zusätzlichen Halt und eine Verschlüsselung hinzu. Dies wird immer die Latenz erhöhen. Wenn Sie versuchen, eine langsame Verbindung eines Benutzers zu diagnostizieren, sollte eine Ihrer ersten Fragen sein: "Sind Sie im VPN?" Tests mit und ohne VPN zeigen Ihnen genau, wie viel Verzögerung es hinzufügt.
- Lokale Netzwerküberlastung ignorieren: Ihre Testergebnisse werden verzerrt, wenn jemand anderes in Ihrem Netzwerk die gesamte Bandbreite beansprucht. Wenn ein Kollege 4K-Video streamt oder massive Dateien herunterlädt, während Sie testen, werden Ihre Latenzzahlen aufgebläht, und Sie werden ein Problem verfolgen, das nicht existiert.
Ein weiterer subtiler, aber kritischer Faktor ist das Tool, das Sie wählen. Wie wir behandelt haben, messen verschiedene Tools die Latenz auf unterschiedliche Weise. Seien Sie immer konsistent mit den Tools, die Sie für den Vergleich verwenden, und stellen Sie sicher, dass Sie verstehen, was jedes Tool tatsächlich misst – ob es sich um ein einfaches ICMP-Echo oder eine komplexe, anwendungsspezifische Anfrage handelt. Und denken Sie daran, dass die Leistung von vielen Schichten beeinflusst werden kann; wenn Sie beispielsweise die Webleistung untersuchen, kann unser Leitfaden zu einer Cookie Editor Chrome Extension zeigen, wie clientseitige Elemente eine Rolle spielen.
Indem Sie Ihre Ergebnisse im richtigen Kontext interpretieren und diese häufigen Fehler vermeiden, werden Sie über das bloße Sammeln von Zahlen hinausgehen. Sie werden beginnen, das Warum hinter der Leistung Ihres Netzwerks zu verstehen, und das ist der Schlüssel zum Aufbau schnellerer, zuverlässigerer Systeme.
Häufige Fragen zur Netzwerk-Latenz
Selbst mit den richtigen Tools tauchen beim Eintauchen in die Netzwerk-Latenz immer wieder einige häufige Fragen auf. Lassen Sie uns einige der häufigsten durchgehen, die ich höre, um Ihnen zu helfen, Ihre Ergebnisse zu verstehen.
Was ist tatsächlich eine „gute“ Latenzzahl?
Dies ist die klassische Frage "es kommt darauf an", aber wir können definitiv einige solide Benchmarks festlegen. Eine "gute" Latenz ist völlig relativ zu dem, was Sie erreichen möchten.
- Gelegentliches Surfen im Web: Für die meisten von uns fühlt sich alles unter 100ms RTT vollkommen in Ordnung an. Seiten laden schnell, und Sie werden keine echte Verzögerung bemerken.
- Wettbewerbsspiele online: Hier zählt jede Millisekunde. Ernsthafte Gamer und Hochfrequenzhändler suchen nach Latenzen, die weit unter 20ms liegen. Es ist der Unterschied zwischen Gewinnen und Verlieren.
- Videoanrufe & VoIP: Hier ist Konsistenz entscheidend. Sie benötigen eine stabile Latenz unter 150ms und niedrigen Jitter (weniger als 30ms), um dieses ruckelige, unsynchronisierte Gefühl oder, schlimmer noch, abgebrochene Anrufe zu vermeiden.
Als Faustregel würden die meisten Netzwerkprofis, die ich kenne, alles unter 50ms als niedrige Latenz klassifizieren. Von 50-150ms ist moderat, und sobald Sie über 150ms hinausgehen, werden Sie die Verzögerung bei den meisten interaktiven Anwendungen spüren.
Warum stimmen meine Ping- und Browser-Geschwindigkeitstest-Ergebnisse nie überein?
Das ist eine fantastische Frage und ein sehr häufiger Punkt der Verwirrung. Es passiert, weil ein Kommandozeilen-ping und ein browserbasierter Geschwindigkeitstest grundlegend unterschiedliche Tools sind, die unterschiedliche Dinge messen.
Zum einen sprechen sie fast sicher mit unterschiedlichen Servern. Wenn Sie eine Domain pingen, treffen Sie ein bestimmtes Ziel. Ein Webgeschwindigkeitstest hingegen ist darauf ausgelegt, einen geografisch nahen Server aus seinem eigenen Netzwerk zu finden, um Ihnen das bestmögliche Ergebnis zu liefern.
Die Protokolle sind ebenfalls völlig unterschiedlich. Ping verwendet ein sehr leichtgewichtiges Protokoll namens ICMP. Die meisten Browser-Tests laufen über TCP, was einen ganzen Einrichtungsprozess (den "Three-Way Handshake") erfordert, nur um eine Verbindung herzustellen. Dieses anfängliche Hin und Her fügt etwas Zeit hinzu, bevor der eigentliche Test überhaupt beginnt.
Schließlich integrieren Browser-Tests oft mehr als nur die reine Netzwerkreisezeit. Ihre "Latenz"-Zahl könnte die Serververarbeitungszeit oder sogar kleine Verzögerungen innerhalb Ihres Browsers selbst umfassen, was die endgültige Zahl im Vergleich zu einem rohen ICMP-Ping aufblähen kann.
Wie kann ich meine Netzwerk-Latenz tatsächlich senken?
Die Reduzierung der Latenz dreht sich alles darum, Engpässe zu finden und zu beseitigen, egal ob sie in Ihrem Büro oder im Internet liegen.
Der erste Ort, an dem Sie suchen sollten, ist Ihre unmittelbare Umgebung. Die effektivste Änderung, die Sie vornehmen können, ist der Wechsel von Wi-Fi zu einer kabelgebundenen Ethernet-Verbindung. Es ist ein Wendepunkt für Stabilität und Geschwindigkeit. Wenn Sie Wi-Fi verwenden müssen, kommen Sie näher an Ihren Router heran und nutzen Sie, wenn möglich, das 5GHz-Band – es ist normalerweise weniger überfüllt.
Wenn Sie über Ihr lokales Netzwerk hinausblicken, kann manchmal ein DNS-Wechsel helfen. Die Verwendung eines schnelleren DNS-Servers kann Millisekunden von der initialen Verbindungszeit abziehen, wenn Sie eine Website aufrufen.
Wenn Sie versuchen, den Zugriff auf einen Dienst, den Sie kontrollieren, zu verbessern, ist ein Content Delivery Network (CDN) die Antwort. Es funktioniert, indem es Kopien Ihrer Inhalte physisch näher zu Ihren Nutzern bringt. Und wenn Sie ein VPN verwenden, versuchen Sie, es auszuschalten. Dieser zusätzliche Sprung und die Verschlüsselungsschicht fügen fast immer Latenz hinzu.
Ich habe gesehen, dass Unternehmens-VPNs bis zu 70 ms zur Rundreisezeit hinzufügen. Es kann eine großartige Verbindung in eine frustrierend langsame verwandeln. Testen Sie immer mit und ohne Ihr VPN, um zu sehen, welche Art von Leistungsabfall Sie tatsächlich haben.
Was ist der wirkliche Unterschied zwischen Latenz und Bandbreite?
Das richtig zu verstehen, ist grundlegend für das Verständnis der Netzwerkleistung. Es ist leicht, sie zu verwechseln, aber sie messen zwei sehr unterschiedliche Dinge.
Hier ist die Analogie, die ich immer verwende: Denken Sie daran wie an eine Autobahn.
- Bandbreite ist, wie viele Fahrstreifen die Autobahn hat. Mehr Fahrstreifen bedeuten, dass mehr Autos (Daten) gleichzeitig fahren können.
- Latenz ist das Geschwindigkeitslimit. Es bestimmt, wie schnell ein einzelnes Auto (ein Datenpaket) von A nach B gelangen kann.
Sie könnten eine massive, zehnspurige Autobahn (riesige Bandbreite) mit einem Geschwindigkeitslimit von 20 mph (hohe Latenz) haben. Sie könnten eine Menge Daten letztendlich bewegen, aber Echtzeitsachen wie ein Videoanruf wären schmerzhaft langsam. Umgekehrt fühlt sich eine Verbindung mit sehr niedriger Latenz unglaublich schnell und reaktionsschnell an, selbst wenn ihre Bandbreite nicht enorm ist. Sie benötigen wirklich eine gute Balance aus beidem für ein großartiges Erlebnis.
Bereit, Leistungstests zu einem nahtlosen Teil Ihres täglichen Workflows zu machen? Die ShiftShift Extensions-Suite bietet einen leistungsstarken Speed Test, einen JSON-Formatter und Dutzende anderer Entwickler-Tools direkt in Ihrem Browser, zugänglich mit einem einzigen Befehl. Hören Sie auf, mit Tabs zu jonglieren, und beginnen Sie, intelligenter zu arbeiten. Laden Sie die ShiftShift Extensions kostenlos herunter und steigern Sie noch heute Ihre Produktivität.