Cómo Medir la Latencia de Red: Guía Práctica para Desarrolladores
Aprende a medir la latencia de la red con esta guía completa. Cubrimos herramientas esenciales como ping y traceroute, así como técnicas de prueba basadas en el navegador.

Extensiones Recomendadas
¿Quieres medir la latencia de la red? Puedes comenzar con herramientas simples y nativas de línea de comandos como ping y traceroute para obtener una lectura rápida del Tiempo de Ida y Vuelta (RTT). O, puedes abrir las herramientas de desarrollador de tu navegador para ver cómo los retrasos están afectando lo que tus usuarios realmente experimentan.
Estos métodos te brindan una instantánea rápida y útil de cuánto tiempo tarda un paquete de datos en viajar desde una fuente, alcanzar un destino y regresar.
Por Qué Medir la Latencia Es No Negociable
Antes de entrar en el "cómo", hablemos del "por qué". Para los desarrolladores e ingenieros de red, la latencia no es solo un número en una pantalla; es la mano invisible que da forma a toda la experiencia del usuario. En las aplicaciones de hoy, los milisegundos son todo. Incluso un pequeño retraso puede ser la diferencia entre un servicio que se siente instantáneo y uno que se siente roto.
Pensando en las consecuencias del mundo real:
- Responsividad de la API: Una sola llamada a la API lenta puede crear un efecto dominó, retrasando todo, desde cargar el perfil de un usuario hasta procesar un pago crítico.
- Flujos de Datos en Tiempo Real: Para juegos en línea, video en vivo o trading financiero, la latencia baja y consistente es la base absoluta. Sin ella, estas aplicaciones simplemente no funcionan.
- Retención de Usuarios: Hay una línea directa que conecta los sitios web y aplicaciones de carga lenta con tasas de rebote más altas y carritos de compra abandonados. Esto impacta fuertemente en la línea de fondo.
Distinguiendo Conceptos Clave de Latencia
Para medir la latencia de la red con precisión, debes saber qué estás observando. Los dos conceptos más fundamentales son Tiempo de Ida y Vuelta (RTT) y latencia unidireccional.
RTT es el tiempo total que tarda una señal en ir del punto A al punto B y regresar. Es la métrica más común que verás porque es sencilla de medir: solo necesitas acceso a un extremo de la conexión.
Latencia unidireccional, como su nombre indica, mide el tiempo que tarda un dato en viajar en una sola dirección. Esta es una medición mucho más complicada de obtener correctamente porque requiere relojes perfectamente sincronizados en ambos extremos. Sin embargo, es un indicador mucho más preciso para conexiones asimétricas, donde tus rutas de carga y descarga se comportan de manera muy diferente.
La importancia de todo esto se vuelve cristalina cuando estás realizando pruebas serias de rendimiento de carga, que es donde la teoría se encuentra con la realidad y se exponen los cuellos de botella.
Para poner algunos números, los expertos en monitoreo de redes generalmente clasifican la latencia de la siguiente manera:
- Baja latencia: Menos de 50 milisegundos
- Latencia moderada: 50-150 ms
- Alta latencia: Más de 150 ms
Por mi experiencia, una prueba rápida a un servidor cercano podría mostrar un 20-40 ms perfectamente aceptable. Pero ese número puede fácilmente aumentar a más de 200 ms para el tráfico que tiene que cruzar un océano, lo que puede ser un cambio radical para el rendimiento de tu aplicación.
Para entender la jerga que encontrarás, aquí tienes una referencia rápida.
Conceptos Clave de Latencia de un Vistazo
| Concepto | Qué Mide | Por Qué Es Importante |
|---|---|---|
| Latencia (Ping) | El tiempo que tarda un solo paquete de datos en viajar desde una fuente a un destino y regresar. Medido en milisegundos (ms). | Esta es la medida cruda del retraso. La baja latencia es crucial para aplicaciones en tiempo real como juegos, VoIP y videoconferencias. |
| Tiempo de Ida y Vuelta (RTT) | Esencialmente lo mismo que la latencia, esta es la duración total para que una señal sea enviada más el tiempo para recibir un acuse de recibo. | RTT es la forma más común y práctica de medir la latencia desde un solo punto, lo que la convierte en la métrica preferida para herramientas como ping. |
| Latencia Unidireccional | El tiempo que tarda un paquete en viajar desde la fuente hasta el destino en una sola dirección. | Proporciona una vista más granular, especialmente para redes asimétricas donde las rutas de carga y descarga tienen diferentes latencias. |
| Jitter | La variación en la latencia a lo largo del tiempo. Mide la inconsistencia de los tiempos de llegada de los paquetes. | Un alto jitter es tan malo como una alta latencia para medios en streaming y llamadas en línea, causando tartamudeos, buffering y fallos. |
| Ancho de Banda | La cantidad máxima de datos que se puede transmitir a través de una conexión de red en un tiempo determinado. Medido en Mbps o Gbps. | A menudo se confunde con la velocidad, el ancho de banda se refiere a la capacidad. Puedes tener un alto ancho de banda pero aún sufrir de alta latencia. |
Estos conceptos son los bloques de construcción para entender cualquier problema de rendimiento de red.
Aquí es donde tener herramientas accesibles e integradas se vuelve tan importante. En lugar de ejecutar suites de diagnóstico complejas, las extensiones modernas del navegador y las herramientas de desarrollo pueden brindarte la información que necesitas sin salir de tu flujo de trabajo. Se trata de hacer que la medición de la latencia sea una parte rutinaria y sin esfuerzo de la construcción y mantenimiento de un gran software.
Poniéndote a Trabajar con Herramientas de Latencia de Línea de Comandos
Para realmente sentir el rendimiento de tu red, debes abrir la terminal. La línea de comandos es donde encontrarás las herramientas fundamentales que te brindan datos crudos y sin filtrar sobre tu conexión. Se trata de ver lo que está realmente sucediendo con los paquetes que se mueven entre tú y un destino, y es el primer paso esencial para cualquier desarrollador serio sobre la medición de la latencia.
La utilidad clásica y de referencia es ping. Es maravillosamente simple: envía un pequeño paquete de datos (una solicitud de eco ICMP) a un servidor y solo espera a que regrese. Ese simple viaje de ida y vuelta es la base para calcular el Tiempo de Ida y Vuelta (RTT) y te da un chequeo instantáneo de la salud de una conexión.
Tu Primer Chequeo de Latencia con Ping
Ejecutar una prueba de ping no podría ser más fácil. Abre tu terminal o símbolo del sistema, escribe ping y síguelo con el dominio que deseas probar.
Por defecto, ping seguirá funcionando indefinidamente en macOS y Linux, mientras que Windows envía solo cuatro paquetes y se detiene. Para cualquier análisis real, querrás controlar esto. Enviar diez o veinte paquetes te dará una imagen mucho más confiable de la estabilidad de la conexión que solo un par.
Una vez que haya terminado, obtendrás un resumen ordenado con los números cruciales:
- Paquetes Transmitidos/Recibidos: Esto te dice si se perdió algún dato en el camino. Incluso una pequeña cantidad de pérdida de paquetes es una gran señal de alerta para problemas de red.
- Ida y vuelta min/prom/max/mdev: Estas son tus estadísticas de latencia centrales. Obtienes el tiempo en el mejor de los casos (
min), el promedio (avg) y el peor de los casos (max). Elmdev(desviación media) es tu medida de jitter: cuánto varía la latencia de un paquete a otro.
P presta atención al espacio entre tu RTT mínimo y máximo. Si es amplio, tu conexión es inestable, incluso si el promedio parece estar bien. Este jitter puede ser mucho más disruptivo para aplicaciones en tiempo real como videollamadas o juegos que una conexión que es consistentemente un poco lenta.
Un error común es solo echar un vistazo al RTT promedio. Un promedio de 50ms puede parecer bien, pero si tu mínimo es 20ms y tu máximo es 250ms, la experiencia del usuario se sentirá entrecortada e inestable. Siempre mira el rango completo para entender el jitter.
Siguiendo la Ruta con Traceroute y MTR
Entonces, ¿qué haces cuando ping revela alta latencia o pérdida de paquetes? Tu siguiente tarea es averiguar dónde está el problema. Para eso está traceroute (o tracert en Windows). Mapea toda la ruta que toman tus paquetes, mostrándote cada "salto"—cada enrutador—entre tu máquina y el destino final.
Cada línea en la salida de traceroute es un salto, y generalmente muestra tres mediciones de latencia separadas hasta ese punto. Esto te permite identificar si un enrutador específico a lo largo de la ruta está causando una desaceleración importante o perdiendo paquetes.
Pero traceroute es una instantánea de una sola vez. Para una vista más dinámica y continua, la mayoría de los profesionales de redes que conozco juran por MTR (My Traceroute). MTR es como una herramienta supercargada que combina ping y traceroute. Envía constantemente paquetes a cada salto en la ruta, dándote una vista en vivo y actualizada de la latencia y la pérdida de paquetes en cada punto. Esto lo hace increíblemente efectivo para detectar problemas intermitentes que un solo traceroute probablemente pasaría por alto.
Por Qué Tu Elección de Herramienta Importa
La herramienta que elijas y cómo la configures puede cambiar drásticamente tus resultados. Esto es especialmente cierto en entornos de ultra alta velocidad y baja latencia como los centros de datos en la nube.
Es realmente sorprendente cuán diferentes pueden ser los números. En un experimento detallado realizado por Google Cloud, una prueba estándar de ping reportó un RTT promedio de 146 microsegundos. Pero cuando utilizaron otra herramienta que envía transacciones una tras otra sin pausa, el RTT cayó a solo 66.59 microsegundos—¡más del doble de rápido!
Este es un ejemplo perfecto de por qué ping a veces puede sobreestimar la latencia. Muestra que entender cómo funciona una herramienta es crítico para obtener mediciones en las que puedes confiar.
Encontrando la Velocidad Máxima de Tu Conexión con iperf
La latencia no siempre es toda la historia. A veces necesitas saber la cantidad máxima de datos que tu conexión puede realmente transmitir—su ancho de banda. Para esa tarea, la herramienta que deseas es iperf.
Mientras que ping mide el retraso, iperf se centra en el rendimiento. Funciona configurando una conexión cliente-servidor y luego enviando la mayor cantidad de datos posible entre ellos durante un tiempo determinado.
Para usar iperf, necesitarás dos máquinas:
- En una máquina, ejecutas
iperfen modo servidor. Simplemente se quedará ahí y escuchará una conexión. - En la otra máquina, ejecutas
iperfen modo cliente, apuntándolo a la dirección del servidor.
El cliente se conectará y la prueba comenzará. La salida te dirá el total de datos transferidos y, lo más importante, el bitrate (tu ancho de banda) en megabits o gigabits por segundo. Es la forma perfecta de poner a prueba un enlace de red y descubrir de qué es realmente capaz.
Midiendo la Latencia desde la Perspectiva del Usuario
Mientras que las herramientas de línea de comandos te dan una mirada cruda y sin filtrar de tu red, la única latencia que realmente importa para una aplicación web es la que el usuario final realmente experimenta. Aquí es donde cambiamos nuestro enfoque de la terminal al navegador mismo. Lo que sucede dentro del navegador cuenta una historia mucho más rica y relevante sobre el rendimiento.
No se trata solo de un viaje de ida y vuelta de un solo paquete. La latencia que un usuario siente es un cóctel complejo de búsquedas DNS, handshakes TCP, negociaciones TLS, tiempo de procesamiento del servidor y, por supuesto, el tiempo que toma renderizar realmente el contenido en pantalla. Afortunadamente, los navegadores modernos vienen equipados con potentes herramientas integradas para ayudarnos a diseccionar todo este proceso.
Sumergiéndonos en las Herramientas de Desarrollador del Navegador
Cada navegador importante—Chrome, Firefox, Edge, Safari—viene equipado con un conjunto de herramientas de desarrollador. La pestaña "Red" dentro de estas herramientas es tu centro de comando para entender cómo se carga tu sitio. Presenta todo en un gráfico de cascada, que es un desglose visual de cada solicitud que el navegador realiza para renderizar una página.
Esta vista de cascada es invaluable. Puedes ver con precisión cuánto tiempo tomó cada recurso para descargarse, desde el documento HTML inicial y las hojas de estilo CSS hasta imágenes y llamadas a la API. Más importante aún, desglosa el ciclo de vida de cada solicitud en fases distintas:
- Búsqueda DNS: El tiempo que tarda en resolver un nombre de dominio a una dirección IP.
- Conexión Inicial: El tiempo gastado estableciendo una conexión TCP con el servidor.
- Handshake SSL/TLS: La sobrecarga requerida para establecer una conexión segura.
- Tiempo hasta el Primer Byte (TTFB): Este es un gran indicador. Mide cuánto tiempo esperó el navegador antes de recibir el primer byte de datos del servidor.
- Descarga de Contenido: El tiempo gastado realmente descargando el recurso en sí.
Un alto TTFB, por ejemplo, es un signo clásico de un backend lento o un problema de procesamiento del lado del servidor—algo que una simple prueba de ping nunca descubriría. Al analizar esta cascada, puedes identificar rápidamente qué recursos están bloqueando el renderizado o simplemente tardando demasiado en cargar.
Una lección clave de mi experiencia es no solo mirar el tiempo total de carga, sino buscar las barras más largas en la cascada. Una sola imagen no optimizada o una API de terceros lenta pueden mantener a toda la página como rehén, creando una mala experiencia de usuario incluso si el resto del sitio es ultrarrápido.
Medición Programática con APIs de Tiempo
Para mediciones más automatizadas y precisas, puedes aprovechar las APIs de JavaScript integradas en el navegador. La API de Tiempo de Navegación y la API de Tiempo de Recursos te dan acceso programático a los mismos datos de rendimiento detallados que ves en las herramientas de desarrollador. Esto es perfecto para recopilar datos de monitoreo de usuarios reales (RUM) para entender cómo se desempeña tu sitio para los visitantes reales en todo el mundo.
Puedes obtener estas métricas con solo unas pocas líneas de JavaScript, directamente en la consola del navegador. Para obtener los tiempos de rendimiento centrales para la carga de la página principal, por ejemplo, puedes usar performance.getEntriesByType('navigation'). Esto devuelve un objeto lleno de valiosos timestamps.
Con esos datos, puedes calcular métricas vitales:
- Tiempo de Búsqueda DNS:
domainLookupEnd - domainLookupStart - Tiempo de Handshake TCP:
connectEnd - connectStart - Tiempo hasta el Primer Byte (TTFB):
responseStart - requestStart - Tiempo Total de Carga de la Página:
loadEventEnd - startTime
Este enfoque te permite construir paneles personalizados o enviar datos de rendimiento a tus herramientas de análisis, dándote un pulso continuo sobre el rendimiento real de tu aplicación. En el desarrollo web, optimizar imágenes es una forma común de mejorar estas métricas; para aquellos interesados, tenemos una guía útil sobre cómo elegir el mejor formato de imagen para tu sitio web.
Agilizando las Verificaciones con Herramientas Integradas
Pasar de la terminal, a las herramientas de desarrollo del navegador y a scripts personalizados puede volverse tedioso rápidamente. Aquí es donde las extensiones de navegador integradas pueden suavizar tu flujo de trabajo al unificar estas verificaciones. Por ejemplo, el conjunto de ShiftShift Extensions incluye una herramienta de Prueba de Velocidad integrada que puedes abrir instantáneamente desde cualquier pestaña.
Esto te brinda una forma rápida y centrada en la privacidad de medir la velocidad de descarga, la velocidad de carga y la latencia de tu conexión sin tener que navegar a un sitio web separado o abrir una terminal. Dado que es parte de un conjunto de herramientas más grande, puedes realizar una verificación de velocidad, formatear una respuesta JSON y verificar una cookie todo desde la misma paleta de comandos unificada. Este tipo de integración hace que las verificaciones de rendimiento sean una parte natural y sin fricciones de la rutina diaria de desarrollo.
Cómo Diseñar una Prueba de Latencia que Realmente Te Diga Algo
Cualquiera puede ejecutar un comando ping y obtener un número de vuelta. Pero si quieres datos en los que realmente puedas confiar—datos que te ayuden a tomar decisiones reales—necesitas ser más deliberado. Una única medición aislada es solo una instantánea en el tiempo. Para entender verdaderamente el comportamiento de tu red, debes pensar como un detective, considerando desde dónde pruebas, con qué frecuencia pruebas y qué es lo que realmente estás buscando.
Una prueba bien diseñada convierte números en bruto en información procesable. ¿Una mal diseñada? Es solo ruido.
El diagrama a continuación desglosa todos los pequeños retrasos que se suman a lo que un usuario siente al cargar una página web. Es un gran recordatorio de que un simple ping de red ni siquiera comienza a contar toda la historia.
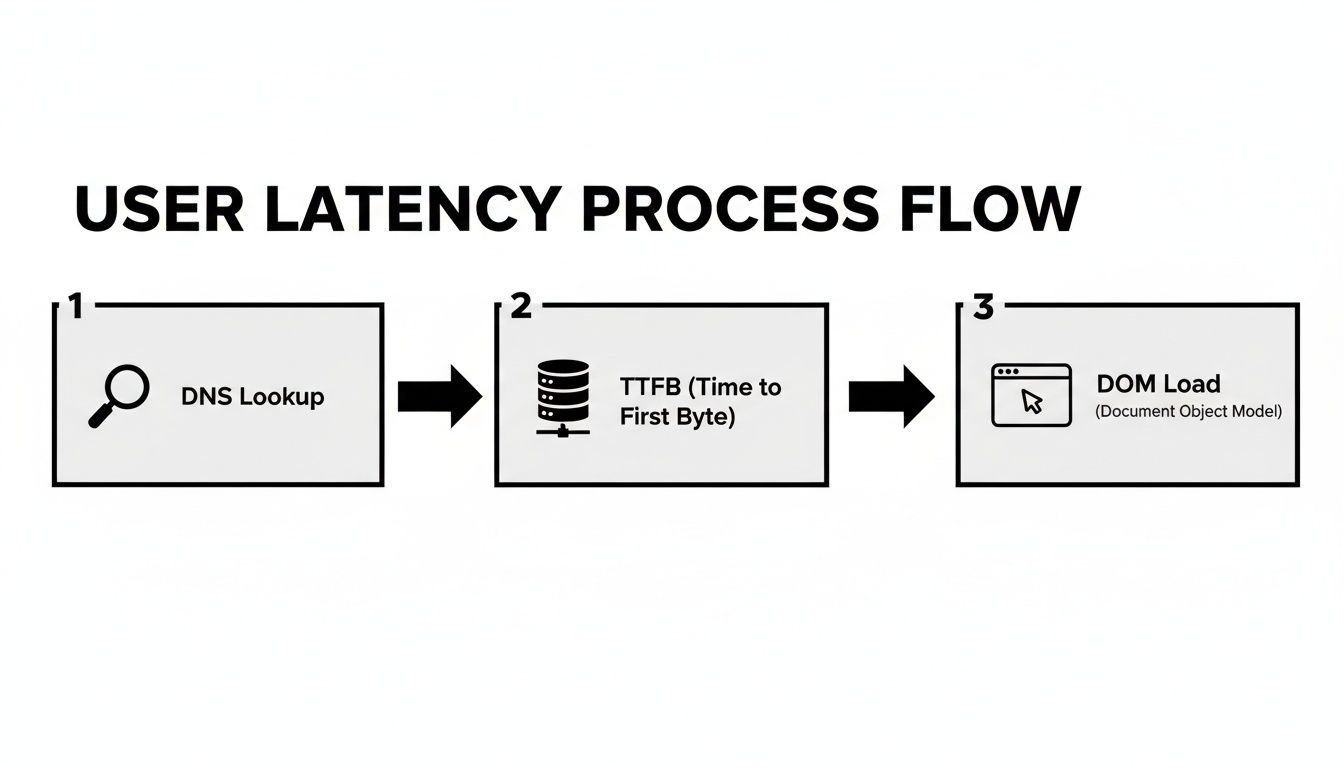
Como puedes ver, desde la búsqueda DNS inicial hasta el renderizado final, múltiples pasos contribuyen al tiempo total de espera.
Eligiendo tus Puntos de Prueba
La primera regla de las pruebas confiables es que la geografía importa. Una prueba desde tu oficina en Nueva York a un servidor cerca en Nueva Jersey no te dice absolutamente nada sobre la experiencia de tus clientes en Tokio. Para obtener una imagen realista, debes probar desde ubicaciones diversas que realmente reflejen tu base de usuarios.
Tu lista de puntos finales debe cubrir algunas áreas clave:
- Tus Principales Centros de Usuarios: ¿Dónde vive la mayoría de tus clientes? Prueba desde allí.
- Caminos Transcontinentales: Observa qué sucede cuando los datos tienen que cruzar un océano. Prueba entre Europa y América del Norte, o Asia y EE. UU., para entender el rendimiento a larga distancia.
- Tus Regiones en la Nube: Si estás en AWS, Azure o GCP, prueba la conectividad hacia y entre las regiones específicas de centros de datos en las que confías.
Distribuir tus pruebas de esta manera crea un mapa mucho más preciso del rendimiento global. Te ayuda a detectar cuellos de botella específicos de la región que de otro modo podrías pasar por alto. Este también es un buen momento para verificar la configuración de tu dominio; puedes encontrar consejos útiles sobre cómo verificar la disponibilidad del dominio y configuraciones relacionadas para asegurarte de que todo esté en orden.
Encontrando el Ritmo de Pruebas Adecuado
Las condiciones de la red están en constante cambio. Varían a lo largo del día, la semana e incluso el minuto. Una prueba realizada a las 3 AM un martes puede parecer fantástica, pero ese resultado es inútil si tu tráfico máximo ocurre a las 2 PM un viernes cuando todos están en línea.
Para obtener una línea base verdadera, necesitas probar de manera consistente a lo largo del tiempo. Varía:
- Realiza pruebas durante las horas pico de negocio.
- Programa algunas para ventanas de mantenimiento nocturnas.
- No olvides los fines de semana, cuando los patrones de tráfico pueden ser completamente diferentes.
Al muestrear datos repetidamente, puedes suavizar los picos y caídas aleatorias. Así es como detectas problemas recurrentes, como la congestión de la red cada tarde de lunes a viernes justo después del almuerzo.
No Olvides el Jitter
La latencia promedio es un buen punto de partida, pero a menudo oculta un problema más siniestro: jitter. El jitter es simplemente la variación en tu latencia a lo largo del tiempo. Piénsalo: una conexión estable con un retraso predecible de 80ms es a menudo mucho mejor para aplicaciones en tiempo real que una que promedia 50ms pero fluctúa salvajemente entre 10ms y 200ms.
El jitter es el asesino silencioso de la experiencia del usuario para cualquier cosa en tiempo real, como llamadas VoIP, videoconferencias o juegos en línea. Un alto jitter es lo que causa audio entrecortado, video congelado y picos de retraso frustrantes que hacen que una aplicación se sienta completamente rota, incluso cuando la latencia promedio se ve bien en papel.
Entender el jitter significa mirar más allá del promedio. Es el villano no reconocido porque revela por qué los promedios por sí solos pueden ser tan engañosos. Por ejemplo, datos de Pandora FMS muestran que un jitter superior a 30ms puede aumentar las tasas de pérdida de paquetes en juegos a 15%, suficiente para hacer que un juego sea injugable. Medir la desviación estándar de tus resultados de latencia es el primer paso para poner un número a esa inestabilidad.
Lista de Verificación para el Diseño de Pruebas de Latencia
Para reunir todo esto, aquí tienes una lista de verificación rápida para guiarte. Seguir estos pasos ayudará a garantizar que los datos que recolectes sean tanto precisos como genuinamente útiles.
| Elemento de la Lista de Verificación | Por Qué Es Importante | Consejo Accionable |
|---|---|---|
| Definir Objetivos Claros | No puedes medir lo que no defines. ¿Estás solucionando un problema específico o estableciendo una línea base? | Escribe tu objetivo antes de comenzar. "Diagnosticar el retraso para usuarios en el sudeste asiático" es un mejor objetivo que "verificar la latencia." |
| Seleccionar Puntos Finales Diversos | Un solo camino no representa tu experiencia global de usuario. | Elige de 3 a 5 ubicaciones: una local, una en otro continente y algunas en tus mercados clave de usuarios. |
| Establecer una Cadencia | Las pruebas únicas pierden patrones basados en el tiempo, como la congestión en horas pico. | Programa pruebas para que se ejecuten automáticamente cada hora durante una semana para capturar un ciclo completo del comportamiento de la red. |
| Medir el Jitter | Los promedios ocultan el rendimiento errático que arruina las aplicaciones en tiempo real. | No solo mires el RTT promedio. Calcula la desviación estándar o utiliza una herramienta como mtr que muestre la latencia mínima/máxima/promedio. |
| Usar las Herramientas Adecuadas | ping es bueno para una verificación rápida, pero herramientas como mtr o iperf proporcionan información más profunda. |
Para el rendimiento web, utiliza herramientas de desarrollo del navegador. Para caminos de red en bruto, mtr es una excelente opción. |
| Documentar Todo | Olvidarás el "por qué" detrás de tu prueba dentro de seis meses. | Mantén un registro simple: fecha, hora, puntos finales, herramienta utilizada y una breve nota sobre lo que observaste. |
Al ser metódico, pasas de simplemente medir la latencia a realmente entenderla. Este enfoque reflexivo es lo que separa un número aleatorio de un indicador de rendimiento confiable.
Dando Sentido a los Números (y Qué Evitar)
Bien, has realizado tus pruebas y tienes un montón de datos. Aquí es donde comienza el verdadero trabajo: traducir esos números en bruto en algo que realmente signifique algo. Los datos te están contando una historia sobre la salud de tu red; solo necesitas aprender a leerla.
Por ejemplo, un repentino aumento en el Tiempo de Ida y Vuelta (RTT) en un traceroute es una pista clásica. Si la latencia salta en el tercer salto y se mantiene alta hasta el final, probablemente has encontrado tu problema: es ese tercer enrutador o el enlace justo después de él. Pero ten cuidado. Si solo ese único salto muestra alta latencia y el destino final sigue siendo rápido, podría ser solo un enrutador configurado para de-priorizar el tipo exacto de tráfico que utiliza tu prueba. Es una falsa alarma común que puede llevarte por un camino equivocado.
Decodificando el Jitter y la Pérdida de Paquetes
Mirar más allá del simple RTT es donde encontrarás las ideas más críticas. Un alto jitter, que es solo una palabra elegante para latencia inconsistente, puede ser mucho más disruptivo que una latencia que es consistentemente alta. Esto es especialmente cierto para cualquier cosa en tiempo real.
Si tus resultados muestran un RTT promedio de 40ms, pero el mínimo fue 10ms y el máximo fue 150ms, tu conexión es inestable. Esa enorme variación es exactamente lo que causa molestos titubeos en las videollamadas y picos de retraso que inducen rabia en los juegos en línea.
La pérdida de paquetes es una bandera roja aún más grande. Incluso una pérdida del 1% de paquetes puede paralizar absolutamente aplicaciones basadas en TCP, obligándolas a reenviar datos constantemente y ralentizando todo a un ritmo de tortuga. Cuando mires tus resultados de prueba, cualquier diferencia real entre paquetes enviados y paquetes recibidos necesita ser investigada de inmediato.
Uno de los mayores errores que veo que cometen las personas es asumir que una sola prueba cuenta toda la historia. Las condiciones de la red están en constante cambio. Una prueba realizada a las 3 AM se verá completamente diferente de una a las 3 PM durante las horas pico de negocio. La única forma de obtener una línea base de rendimiento verdadera es a través de pruebas consistentes y repetidas.
Para adelantarte a los problemas, vale la pena investigar herramientas dedicadas para monitoreo del rendimiento de la red. Esto cambia tu enfoque de arreglar cosas frenéticamente cuando se rompen a mantener proactivamente tu red saludable.
Los Errores de Medición Más Comunes
Aún con las mejores herramientas del mundo, algunos errores simples pueden hacer que tus resultados sean completamente inútiles. Evitar estos errores comunes es innegociable si quieres datos en los que realmente puedas confiar.
- Probar a través de Wi-Fi: En serio, simplemente no lo hagas. Las conexiones inalámbricas son notoriamente caprichosas, propensas a interferencias de todo, desde microondas hasta el enrutador de tu vecino. Para cualquier prueba seria de latencia, conéctate con un cable Ethernet. Es la única forma de obtener una línea base estable y confiable.
- Olvidar la Sobrecarga del VPN: Los VPN son excelentes para la seguridad, pero añaden una parada adicional y cifrado al viaje de tu tráfico. Esto siempre aumentará la latencia. Si estás tratando de diagnosticar la conexión lenta de un usuario, una de tus primeras preguntas debería ser: "¿Estás en el VPN?" Probar con y sin él te mostrará exactamente cuánto retraso está añadiendo.
- Ignorar la Congestión de la Red Local: Tus resultados de prueba estarán sesgados si alguien más en tu red está acaparando todo el ancho de banda. Si un colega está transmitiendo video en 4K o descargando archivos masivos mientras pruebas, tus números de latencia estarán inflados, y terminarás persiguiendo un problema que no existe.
Otro factor sutil pero crítico es la herramienta que elijas. Como hemos cubierto, diferentes utilidades miden la latencia de diferentes maneras. Siempre sé consistente con las herramientas que usas para comparación, y asegúrate de entender qué es lo que cada una está realmente midiendo—ya sea un simple eco ICMP o una solicitud compleja a nivel de aplicación. Y recuerda, el rendimiento puede verse afectado por muchas capas; por ejemplo, si estás indagando en el rendimiento web, nuestra guía sobre una Extensión de Editor de Cookies para Chrome puede mostrar cómo los elementos del lado del cliente juegan un papel.
Al interpretar tus resultados con el contexto adecuado y evitar estos errores comunes, irás más allá de simplemente recolectar números. Comenzarás a entender el por qué detrás del rendimiento de tu red, y esa es la clave para construir sistemas más rápidos y confiables.
Preguntas Comunes Sobre la Latencia de la Red
Aún con las herramientas adecuadas, algunas preguntas comunes siempre parecen surgir cuando comienzas a indagar en la latencia de la red. Vamos a repasar algunas de las más frecuentes que escucho para ayudarte a dar sentido a tus resultados.
¿Cuál es un Número de Latencia “Bueno”?
Esta es la clásica pregunta de "depende", pero definitivamente podemos establecer algunos puntos de referencia sólidos. Una latencia "buena" es completamente relativa a lo que estás tratando de lograr.
- Navegación Web Casual: Para la mayoría de nosotros, cualquier cosa por debajo de 100ms de RTT se sentirá perfectamente bien. Las páginas cargan rápidamente y no notarás ningún retraso real.
- Juegos en Línea Competitivos: Aquí es donde cada milisegundo cuenta. Los jugadores serios y los traders de alta frecuencia buscan latencias muy por debajo de 20ms. Es la diferencia entre ganar y perder.
- Videollamadas y VoIP: Aquí, la consistencia es clave. Necesitas una latencia estable por debajo de 150ms y bajo jitter (menos de 30ms) para evitar esa sensación entrecortada y fuera de sincronización o, peor aún, llamadas caídas.
Como regla general, la mayoría de los profesionales de redes que conozco clasificarían cualquier cosa por debajo de 50ms como baja latencia. De 50-150ms es moderada, y una vez que superas 150ms, comenzarás a sentir la lentitud en la mayoría de las aplicaciones interactivas.
¿Por Qué Mis Resultados de Ping y Prueba de Velocidad del Navegador Nunca Coinciden?
Esta es una pregunta fantástica y un punto de confusión muy común. Ocurre porque un ping de línea de comandos y una prueba de velocidad basada en navegador son herramientas fundamentalmente diferentes que miden cosas diferentes.
Para empezar, casi con certeza están hablando con diferentes servidores. Cuando ping un dominio, estás golpeando un objetivo específico. Una prueba de velocidad web, por otro lado, está diseñada para encontrar un servidor geográficamente cercano desde su propia red para darte el mejor resultado posible.
Los protocolos también son completamente diferentes. Ping utiliza un protocolo muy ligero llamado ICMP. La mayoría de las pruebas de navegador funcionan sobre TCP, que requiere todo un proceso de configuración (el "apretón de manos de tres vías") solo para establecer una conexión. Ese intercambio inicial añade un poco de tiempo antes de que comience la prueba real.
Finalmente, las pruebas de navegador a menudo incluyen más que solo el tiempo de viaje de red puro. Su número de "latencia" podría incluir el tiempo de procesamiento del servidor o incluso pequeños retrasos dentro de tu propio navegador, lo que puede inflar la cifra final en comparación con un ping ICMP en bruto.
¿Cómo Puedo Reducir Realmente Mi Latencia de Red?
Reducir la latencia se trata de cazar y eliminar cuellos de botella, ya sea en tu oficina o a través de internet.
El primer lugar para buscar es tu entorno inmediato. El cambio más efectivo que puedes hacer es pasar de Wi-Fi a una conexión Ethernet por cable. Es un cambio radical para la estabilidad y la velocidad. Si tienes que usar Wi-Fi, acércate a tu enrutador y conéctate a la banda de 5GHz si puedes; generalmente está menos congestionada.
Mirando más allá de tu red local, a veces un cambio de DNS puede ayudar. Usar un servidor DNS más rápido puede reducir milisegundos del tiempo de conexión inicial al buscar un sitio web.
Si estás tratando de mejorar el acceso a un servicio que controlas, una Red de Entrega de Contenido (CDN) es la respuesta. Funciona colocando copias de tu contenido físicamente más cerca de tus usuarios. Y si estás usando una VPN, intenta desactivarla. Ese salto adicional y la capa de cifrado casi siempre añaden latencia.
He visto que las VPN corporativas añaden hasta 70ms al tiempo de ida y vuelta. Puede convertir una gran conexión en una frustrantemente lenta. Siempre prueba con y sin tu VPN para ver qué tipo de impacto en el rendimiento estás realmente experimentando.
¿Cuál es la verdadera diferencia entre latencia y ancho de banda?
Entender esto es fundamental para comprender el rendimiento de la red. Es fácil confundirlos, pero miden dos cosas muy diferentes.
Aquí está la analogía que siempre uso: piénsalo como una carretera.
- El ancho de banda es cuántos carriles tiene la carretera. Más carriles significan que más autos (datos) pueden viajar al mismo tiempo.
- La latencia es el límite de velocidad. Dicta qué tan rápido puede llegar un solo auto (un paquete de datos) de A a B.
Podrías tener una carretera masiva de diez carriles (ancho de banda enorme) con un límite de velocidad de 20 mph (alta latencia). Podrías mover una gran cantidad de datos eventualmente, pero cosas en tiempo real como una videollamada serían dolorosamente lentas. Por otro lado, una conexión con muy baja latencia se siente increíblemente ágil y receptiva, incluso si su ancho de banda no es enorme. Realmente necesitas un buen equilibrio de ambos para una gran experiencia.
¿Listo para hacer que las pruebas de rendimiento sean una parte fluida de tu flujo de trabajo diario? La suite de ShiftShift Extensions pone una poderosa prueba de velocidad, un formateador de JSON y docenas de otras herramientas para desarrolladores directamente en tu navegador, accesibles con un solo comando. Deja de malabarear pestañas y comienza a trabajar de manera más inteligente. Descarga ShiftShift Extensions gratis y potencia tu productividad hoy.