Come Misurare la Latency di Rete: Guida Pratica per Sviluppatori
Scopri come misurare la latenza di rete con questa guida completa. Trattiamo strumenti essenziali come ping e traceroute e tecniche di test basate sul browser.

Estensioni Consigliate
Vuoi misurare la latenza di rete? Puoi iniziare con semplici strumenti da riga di comando integrati come ping e traceroute per avere una lettura rapida del Round-Trip Time (RTT). Oppure, puoi aprire gli strumenti per sviluppatori del tuo browser per vedere come i ritardi stanno influenzando ciò che i tuoi utenti stanno realmente vivendo.
Questi metodi ti offrono un'istantanea veloce e utile di quanto tempo impiega un pacchetto di dati a viaggiare da una sorgente, raggiungere una destinazione e tornare indietro.
Perché Misurare la Latenza È Non Negoziale
Prima di entrare nel "come", parliamo del "perché". Per sviluppatori e ingegneri di rete, la latenza non è solo un numero su uno schermo; è la mano invisibile che plasma l'intera esperienza utente. Nelle applicazioni di oggi, i millisecondi sono tutto. Anche un piccolo ritardo può fare la differenza tra un servizio che sembra istantaneo e uno che sembra rotto.
Pensa alle conseguenze nel mondo reale:
- Reattività dell'API: Una singola chiamata API lenta può creare un effetto domino, bloccando tutto, dal caricamento del profilo di un utente all'elaborazione di un pagamento critico.
- Flussi di Dati in Tempo Reale: Per i giochi online, video in diretta o trading finanziario, una latenza bassa e costante è la base assoluta. Senza di essa, queste applicazioni semplicemente non funzionano.
- Retention degli Utenti: C'è una linea diretta che collega siti web e app a caricamento lento a tassi di abbandono più elevati e carrelli abbandonati. Queste cose colpiscono duramente il bilancio.
Distingui i Concetti Chiave della Latenza
Per misurare accuratamente la latenza di rete, devi sapere cosa stai osservando. I due concetti più fondamentali sono Round-Trip Time (RTT) e latenza unidirezionale.
RTT è il tempo totale che impiega un segnale per andare dal punto A al punto B e tornare indietro. È la metrica più comune che vedrai perché è semplice da misurare: hai solo bisogno di accesso a un'estremità della connessione.
Latenza unidirezionale, come suggerisce il nome, misura il tempo che impiega un dato a viaggiare in una sola direzione. Questa è una misurazione molto più difficile da ottenere correttamente perché richiede orologi perfettamente sincronizzati a entrambe le estremità. Tuttavia, è un indicatore molto più preciso per connessioni asimmetriche, dove i percorsi di upload e download si comportano in modo molto diverso.
L'importanza di tutto ciò diventa cristallina quando stai facendo seri test di performance di carico, dove la teoria incontra la realtà e i colli di bottiglia vengono esposti.
Per mettere alcuni numeri su questo, gli esperti di monitoraggio della rete generalmente classificano la latenza in questo modo:
- Bassa latenza: Sotto 50 millisecondi
- Latenza moderata: 50-150 ms
- Alta latenza: Oltre 150 ms
Per la mia esperienza, un test rapido verso un server vicino potrebbe mostrare un 20-40 ms perfettamente accettabile. Ma quel numero può facilmente gonfiarsi a oltre 200 ms per il traffico che deve attraversare un oceano, il che può essere un cambiamento radicale per le prestazioni della tua applicazione.
Per comprendere il gergo che incontrerai, ecco un rapido riferimento.
Concetti Chiave della Latenza a Colpo d'Occhio
| Concetto | Cosa Misura | Perché È Importante |
|---|---|---|
| Latenza (Ping) | Il tempo che impiega un singolo pacchetto di dati a viaggiare da una sorgente a una destinazione e tornare. Misurato in millisecondi (ms). | Questa è la misura grezza del ritardo. Una bassa latenza è cruciale per applicazioni in tempo reale come giochi, VoIP e videoconferenze. |
| Round-Trip Time (RTT) | Essenzialmente la stessa cosa della latenza, questa è la durata totale per inviare un segnale più il tempo necessario per ricevere un riconoscimento. | L'RTT è il modo più comune e pratico per misurare la latenza da un singolo punto, rendendolo la metrica di riferimento per strumenti come ping. |
| Latenza Unidirezionale | Il tempo che impiega un pacchetto a viaggiare dalla sorgente alla destinazione in una sola direzione. | Fornisce una visione più granulare, specialmente per reti asimmetriche dove i percorsi di upload e download hanno latenze diverse. |
| Jitter | La variazione della latenza nel tempo. Misura l'incoerenza dei tempi di arrivo dei pacchetti. | Un alto jitter è altrettanto dannoso quanto un'alta latenza per lo streaming di media e le chiamate online, causando balbuzie, buffering e glitch. |
| Bandwidth | La massima quantità di dati che può essere trasmessa su una connessione di rete in un dato intervallo di tempo. Misurato in Mbps o Gbps. | Spesso confuso con la velocità, la bandwidth riguarda la capacità. Puoi avere un'alta bandwidth ma soffrire comunque di alta latenza. |
Questi concetti sono i mattoni fondamentali per comprendere qualsiasi problema di performance di rete.
È qui che avere strumenti integrati e accessibili diventa così importante. Invece di eseguire suite diagnostiche complesse, le moderne estensioni del browser e gli strumenti di sviluppo possono darti le informazioni di cui hai bisogno senza mai lasciare il tuo flusso di lavoro. Si tratta di rendere la misurazione della latenza una parte semplice e routinaria della creazione e manutenzione di un ottimo software.
Mettere le Mani in Pasta con Strumenti di Latenza da Riga di Comando
Per avere davvero un'idea delle prestazioni della tua rete, devi aprire il terminale. La riga di comando è dove troverai gli strumenti fondamentali che ti danno dati grezzi e non filtrati sulla tua connessione. Si tratta di vedere cosa sta realmente accadendo con i pacchetti che si muovono tra te e una destinazione, ed è il primo passo essenziale per qualsiasi sviluppatore serio riguardo alla misurazione della latenza.
Lo strumento classico e di riferimento è ping. È splendidamente semplice: invia un piccolo pacchetto di dati (una richiesta di eco ICMP) a un server e aspetta semplicemente che torni indietro. Quel semplice viaggio di andata e ritorno è la base per calcolare il Round-Trip Time (RTT) e ti fornisce un controllo immediato sulla salute di una connessione.
Il Tuo Primo Controllo della Latenza con Ping
Eseguire un test ping non potrebbe essere più semplice. Apri il tuo terminale o prompt dei comandi, digita ping e seguilo con il dominio che vuoi testare.
Per impostazione predefinita, ping continuerà a funzionare all'infinito su macOS e Linux, mentre Windows invia solo quattro pacchetti e si ferma. Per qualsiasi analisi reale, vorrai controllare questo. Inviare dieci o venti pacchetti ti dà un quadro molto più affidabile della stabilità della connessione rispetto a solo un paio.
Una volta completato, riceverai un riepilogo ordinato con i numeri cruciali:
- Pacchetti Trasmetti/Ricevuti: Questo ti dice se sono stati persi dati lungo il percorso. Anche una piccola quantità di perdita di pacchetti è un grande campanello d'allarme per problemi di rete.
- Round-trip min/avg/max/mdev: Queste sono le tue statistiche di latenza fondamentali. Ottieni il tempo migliore (
min), la media (avg) e il tempo peggiore (max). Ilmdev(deviazione media) è la tua misura di jitter—quanto varia la latenza da un pacchetto all'altro.
Fai attenzione al divario tra il tuo RTT minimo e massimo. Se è ampio, la tua connessione è instabile, anche se la media sembra a posto. Questo jitter può essere molto più dirompente per app in tempo reale come videochiamate o giochi rispetto a una connessione che è costantemente un po' lenta.
Un errore comune è dare solo un'occhiata all'RTT medio. Una media di 50ms potrebbe sembrare accettabile, ma se il tuo minimo è 20ms e il tuo massimo è 250ms, l'esperienza utente sembrerà a scatti e inaffidabile. Guarda sempre l'intero intervallo per comprendere il jitter.
Seguire il Percorso con Traceroute e MTR
Quindi, cosa fai quando ping rivela alta latenza o perdita di pacchetti? Il tuo prossimo compito è capire dove si trova il problema. Questo è ciò per cui serve traceroute (o tracert su Windows). Mappa l'intero percorso che i tuoi pacchetti seguono, mostrandoti ogni singolo "salto"—ogni router—tra la tua macchina e la destinazione finale.
Ogni riga nell'output di traceroute è un salto, e di solito mostra tre misurazioni di latenza separate fino a quel punto. Questo ti consente di individuare se un router specifico lungo il percorso sta causando un rallentamento significativo o perdendo pacchetti.
Ma traceroute è un'istantanea una tantum. Per uno sguardo più dinamico e continuo, la maggior parte dei professionisti di rete che conosco giura su MTR (My Traceroute). MTR è come uno strumento potenziato che combina ping e traceroute. Invia costantemente pacchetti a ogni salto sul percorso, fornendoti una vista dal vivo e in aggiornamento della latenza e della perdita di pacchetti in ogni singolo punto. Questo lo rende incredibilmente efficace nel catturare problemi intermittenti che un singolo traceroute probabilmente perderebbe.
Perché la Scelta dello Strumento È Importante
Lo strumento che scegli e come lo configuri possono cambiare drasticamente i tuoi risultati. Questo è particolarmente vero in ambienti ultra-veloci e a bassa latenza come i data center cloud.
È davvero sorprendente quanto possano essere diversi i numeri. In un esperimento dettagliato condotto da Google Cloud, un test ping standard ha riportato un RTT medio di 146 microsecondi. Ma quando hanno utilizzato un altro strumento che invia transazioni una dopo l'altra senza pause, l'RTT è sceso a soli 66.59 microsecondi—più del doppio della velocità!
Questo è un esempio perfetto di perché ping a volte può sovrastimare la latenza. Dimostra che comprendere come funziona uno strumento è fondamentale per ottenere misurazioni di cui puoi fidarti.
Trovare la Velocità Massima della Tua Connessione con iperf
La latenza non è sempre l'intero quadro. A volte hai bisogno di sapere la massima quantità di dati che la tua connessione può effettivamente gestire—la sua bandwidth. Per quel lavoro, lo strumento che desideri è iperf.
Mentre ping misura il ritardo, iperf si concentra sul throughput. Funziona impostando una connessione client-server e poi inviando il maggior numero possibile di dati tra di loro per un periodo di tempo stabilito.
Per utilizzare iperf, avrai bisogno di due macchine:
- Su una macchina, esegui
iperfin modalità server. Rimarrà semplicemente in attesa di una connessione. - Sull'altra macchina, esegui
iperfin modalità client, puntandolo all'indirizzo del server.
Il client si connetterà e il test inizierà. L'output ti dirà il totale dei dati trasferiti e, cosa più importante, il bitrate (la tua bandwidth) in megabit o gigabit al secondo. È il modo perfetto per stressare un collegamento di rete e scoprire di cosa è realmente capace.
Misurare la Latenza dalla Prospettiva dell'Utente
Mentre gli strumenti da riga di comando ti danno uno sguardo grezzo e non filtrato sulla tua rete, l'unica latenza che conta davvero per un'applicazione web è quella che l'utente finale vive realmente. Qui spostiamo il nostro focus dal terminale al browser stesso. Ciò che accade all'interno del browser racconta una storia molto più ricca e pertinente sulle prestazioni.
Non si tratta mai solo di un singolo viaggio di andata e ritorno di un pacchetto. La latenza che un utente sente è un cocktail complesso di ricerche DNS, handshake TCP, negoziazioni TLS, tempo di elaborazione del server e, naturalmente, il tempo necessario per rendere effettivamente il contenuto sullo schermo. Fortunatamente, i browser moderni sono dotati di potenti strumenti integrati per aiutarci a dissezionare l'intero processo.
Esplorando gli Strumenti per Sviluppatori del Browser
Ogni browser principale—Chrome, Firefox, Edge, Safari—è dotato di una suite di strumenti per sviluppatori. La scheda "Network" all'interno di questi strumenti è il tuo centro di comando per comprendere come il tuo sito si carica. Mostra tutto in un grafico a cascata, che è una suddivisione visiva di ogni singola richiesta che il browser fa per rendere una pagina.
Questa vista a cascata è inestimabile. Puoi vedere esattamente quanto tempo ha impiegato ogni risorsa a scaricarsi, dal documento HTML iniziale e dai fogli di stile CSS alle immagini e alle chiamate API. Più importante, suddivide il ciclo di vita di ogni richiesta in fasi distinte:
- Ricerca DNS: Il tempo necessario per risolvere un nome di dominio in un indirizzo IP.
- Connessione Iniziale: Il tempo speso per stabilire una connessione TCP con il server.
- Handshake SSL/TLS: Il sovraccarico necessario per impostare una connessione sicura.
- Tempo fino al Primo Byte (TTFB): Questo è un aspetto fondamentale. Misura quanto tempo ha atteso il browser prima di ricevere il primo byte di dati dal server.
- Download del Contenuto: Il tempo speso per scaricare effettivamente la risorsa stessa.
Un alto TTFB, ad esempio, è un segnale classico di un backend lento o di un problema di elaborazione lato server—qualcosa che un semplice test ping non scoprirebbe mai. Analizzando questa cascata, puoi rapidamente individuare quali risorse stanno bloccando il rendering o impiegano troppo tempo a caricarsi.
Un insegnamento chiave dalla mia esperienza è non limitarsi a guardare il tempo totale di caricamento, ma cercare le barre più lunghe nella cascata. Un'unica immagine non ottimizzata o una lenta API di terze parti possono tenere in ostaggio l'intera pagina, creando una cattiva esperienza utente anche se il resto del sito è fulmineo.
Misurazione Programmatica con le API di Timing
Per misurazioni più automatizzate e precise, puoi attingere alle API JavaScript integrate del browser. Le Navigation Timing API e Resource Timing API ti danno accesso programmatico agli stessi dati dettagliati sulle prestazioni che vedi negli strumenti per sviluppatori. Questo è perfetto per raccogliere dati di monitoraggio degli utenti reali (RUM) per comprendere come il tuo sito si comporta per i visitatori reali in tutto il mondo.
Puoi ottenere queste metriche con solo poche righe di JavaScript, direttamente nella console del browser. Per ottenere i tempi di prestazione fondamentali per il caricamento della pagina principale, ad esempio, puoi usare performance.getEntriesByType('navigation'). Questo restituisce un oggetto pieno di timestamp preziosi.
Da quei dati, puoi calcolare metriche vitali:
- Tempo di Ricerca DNS:
domainLookupEnd - domainLookupStart - Tempo di Handshake TCP:
connectEnd - connectStart - Tempo fino al Primo Byte (TTFB):
responseStart - requestStart - Tempo Totale di Caricamento della Pagina:
loadEventEnd - startTime
Questo approccio ti consente di costruire dashboard personalizzate o inviare dati sulle prestazioni ai tuoi strumenti di analisi, offrendoti un monitoraggio continuo delle prestazioni reali della tua applicazione. Nello sviluppo web, ottimizzare le immagini è un modo comune per migliorare queste metriche; per chi è interessato, abbiamo una guida utile su come scegliere il miglior formato immagine per il tuo sito web.
Ottimizzare i Controlli con Strumenti Integrati
Passare tra terminale, strumenti di sviluppo del browser e script personalizzati può diventare rapidamente noioso. Qui è dove le estensioni integrate del browser possono davvero semplificare il tuo flusso di lavoro unificando questi controlli. Ad esempio, il pacchetto di ShiftShift Extensions include uno strumento Speed Test integrato che puoi aprire istantaneamente da qualsiasi scheda.
Questo ti offre un modo rapido e incentrato sulla privacy per misurare la velocità di download, la velocità di upload e la latenza della tua connessione senza dover navigare su un sito web separato o aprire un terminale. Poiché fa parte di un toolkit più ampio, puoi eseguire un controllo della velocità, formattare una risposta JSON e controllare un cookie tutto dalla stessa palette di comandi unificata. Questo tipo di integrazione rende i controlli delle prestazioni una parte naturale e senza attriti della routine quotidiana di sviluppo.
Come Progettare un Test di Latenza che Ti Dica Qualcosa di Utile
Chiunque può lanciare un comando ping e ricevere un numero. Ma se desideri dati di cui puoi davvero fidarti—dati che ti aiutano a prendere decisioni reali—devi essere più deliberato. Una singola misurazione isolata è solo un'istantanea nel tempo. Per comprendere veramente il comportamento della tua rete, devi pensare come un detective, considerando da dove testi, quanto spesso testi e cosa stai realmente cercando.
Un test ben progettato trasforma numeri grezzi in intuizioni azionabili. Uno mal progettato? È solo rumore.
Il diagramma qui sotto scompone tutti i piccoli ritardi che si sommano a ciò che un utente percepisce quando carica una pagina web. È un ottimo promemoria che un semplice ping di rete non inizia nemmeno a raccontare l'intera storia.
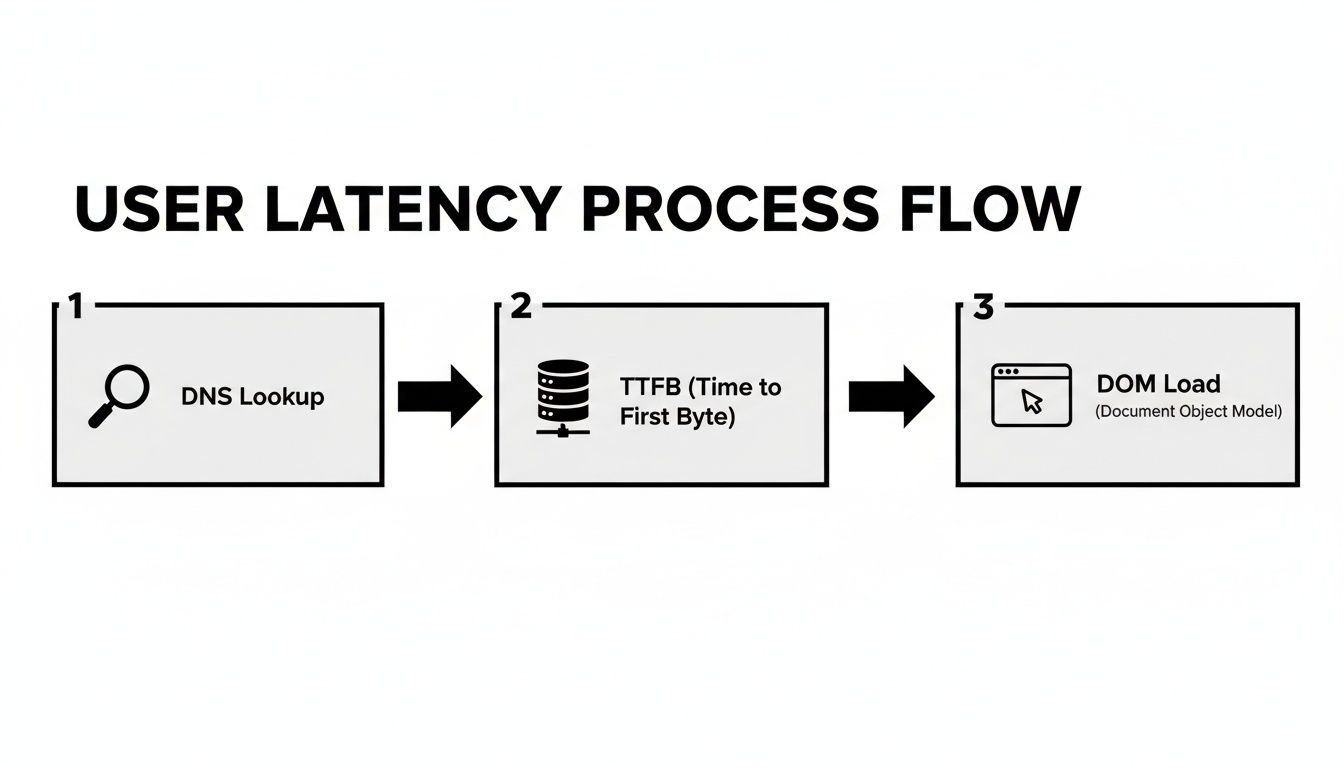
Come puoi vedere, dalla ricerca DNS iniziale al rendering finale, più passaggi contribuiscono al tempo totale di attesa.
Scegliere i Tuoi Endpoint di Test
La prima regola per test affidabili è che la geografia conta. Un test dal tuo ufficio a New York a un server a pochi passi in New Jersey non ti dice assolutamente nulla sull'esperienza dei tuoi clienti a Tokyo. Per ottenere un quadro realistico, devi testare da diverse posizioni che rispecchiano effettivamente la tua base utenti.
La tua lista di endpoint dovrebbe coprire alcune aree chiave:
- I Tuoi Maggiori Hub Utente: Dove vivono la maggior parte dei tuoi clienti? Testa da lì.
- Percorsi Transcontinentali: Scopri cosa succede quando i dati devono attraversare un oceano. Testa tra Europa e Nord America, o Asia e Stati Uniti, per comprendere le prestazioni a lungo raggio.
- Le Tue Regioni Cloud: Se sei su AWS, Azure o GCP, testa la connettività verso e tra le specifiche regioni dei data center su cui fai affidamento.
Distribuire i tuoi test in questo modo crea una mappa delle prestazioni globali molto più accurata. Ti aiuta a individuare colli di bottiglia specifici per regione che altrimenti potresti completamente trascurare. Questo è anche un buon momento per ricontrollare la configurazione del tuo dominio; puoi trovare suggerimenti utili su come controllare la disponibilità del dominio e configurazioni correlate per assicurarti che tutto sia in ordine.
Trovare il Giusto Ritmo di Test
Le condizioni di rete sono costantemente in cambiamento. Cambiano durante il giorno, la settimana e persino il minuto. Un test eseguito alle 3 del mattino di un martedì potrebbe sembrare fantastico, ma quel risultato è inutile se il tuo traffico di punta si verifica alle 14:00 di un venerdì quando tutti sono online.
Per ottenere una vera base di riferimento, devi testare in modo coerente nel tempo. Varia:
- Esegui test durante le ore di punta lavorative.
- Pianifica alcuni per le finestre di manutenzione notturna.
- Non dimenticare i fine settimana, quando i modelli di traffico possono essere completamente diversi.
Campionando i dati ripetutamente, puoi smussare i picchi e i cali casuali. Questo è il modo in cui individui problemi ricorrenti, come la congestione della rete ogni pomeriggio nei giorni feriali subito dopo pranzo.
Non Dimenticare il Jitter
La latenza media è un buon punto di partenza, ma spesso nasconde un problema più insidioso: il jitter. Il jitter è semplicemente la variazione della tua latenza nel tempo. Pensaci: una connessione stabile con un ritardo prevedibile di 80ms è spesso molto migliore per le app in tempo reale rispetto a una che ha una media di 50ms ma oscilla selvaggiamente tra 10ms e 200ms.
Il jitter è il killer silenzioso dell'esperienza utente per qualsiasi cosa in tempo reale, come le chiamate VoIP, le videoconferenze o i giochi online. Un alto jitter è ciò che causa audio a scatti, video bloccati e fastidiosi picchi di latenza che fanno sembrare un'applicazione completamente rotta, anche quando la latenza media sembra buona sulla carta.
Comprendere il jitter significa guardare oltre la media. È il villain non celebrato perché rivela perché le medie da sole possono essere così fuorvianti. Ad esempio, i dati di Pandora FMS mostrano che un jitter superiore a 30ms può aumentare i tassi di perdita di pacchetti nei giochi fino al 15%—sufficiente per rendere un gioco ingiocabile. Misurare la deviazione standard dei tuoi risultati di latenza è il primo passo per quantificare quella instabilità.
Checklist per la Progettazione di un Test di Latenza
Per mettere tutto insieme, ecco una checklist rapida per guidarti. Seguire questi passaggi aiuterà a garantire che i dati che raccogli siano sia accurati che realmente utili.
| Elemento della Checklist | Perché è Importante | Suggerimento Azionabile |
|---|---|---|
| Definire Obiettivi Chiari | Non puoi misurare ciò che non definisci. Stai risolvendo un problema specifico o stabilendo una base di riferimento? | Scrivi il tuo obiettivo prima di iniziare. "Diagnosticare il ritardo per gli utenti nel Sud-est asiatico" è un obiettivo migliore di "controllare la latenza." |
| Selezionare Endpoint Diversificati | Un singolo percorso non rappresenta la tua esperienza utente globale. | Scegli 3-5 posizioni: una locale, una su un altro continente e alcune nei tuoi mercati chiave. |
| Stabilire una Cadenza | Test unici mancano di modelli basati sul tempo come la congestione durante le ore di punta. | Pianifica test per essere eseguiti automaticamente ogni ora per una settimana per catturare un intero ciclo di comportamento della rete. |
| Misurare il Jitter | Le medie nascondono le prestazioni erratiche che rovinano le applicazioni in tempo reale. | Non guardare solo la latenza media. Calcola la deviazione standard o utilizza uno strumento come mtr che mostra latenza min/max/media. |
| Utilizzare gli Strumenti Giusti | ping è buono per un controllo rapido, ma strumenti come mtr o iperf forniscono approfondimenti più dettagliati. |
Per le prestazioni web, utilizza gli strumenti di sviluppo del browser. Per i percorsi di rete grezzi, mtr è una scelta eccellente. |
| Documentare Tutto | Dimenticherai il "perché" dietro il tuo test sei mesi da ora. | Tieni un semplice registro: data, ora, endpoint, strumento utilizzato e una breve nota su ciò che hai osservato. |
Essere metodici ti porta a passare dal semplice misurare la latenza a comprenderla veramente. Questo approccio riflessivo è ciò che separa un numero casuale da un indicatore di prestazioni affidabile.
Comprendere i Numeri (e Cosa Evitare)
Va bene, hai eseguito i tuoi test e hai un mucchio di dati. Qui inizia il vero lavoro: tradurre quei numeri grezzi in qualcosa che significhi realmente qualcosa. I dati ti stanno raccontando una storia sulla salute della tua rete; devi solo imparare a leggerla.
Ad esempio, un improvviso picco nel Tempo di Andata e Ritorno (RTT) su un traceroute è un indizio classico. Se la latenza salta al terzo hop e rimane alta fino alla fine, hai probabilmente trovato il tuo problema: è quel terzo router o il link subito dopo. Ma fai attenzione. Se solo quel singolo hop mostra alta latenza e la destinazione finale è ancora veloce, potrebbe essere solo un router configurato per de-prioritizzare il tipo esatto di traffico che il tuo test utilizza. È un falso allarme comune che può portarti a inseguire un problema inesistente.
Decodificare Jitter e Perdita di Pacchetti
Guardare oltre il semplice RTT è dove troverai le intuizioni più critiche. Un alto jitter, che è solo una parola elegante per latenza incoerente, può essere molto più dirompente di una latenza costantemente alta. Questo è particolarmente vero per qualsiasi cosa in tempo reale.
Se i tuoi risultati mostrano un RTT medio di 40ms, ma il minimo era 10ms e il massimo era 150ms, la tua connessione è instabile. Quella enorme variazione è esattamente ciò che causa fastidiosi scatti nelle videochiamate e picchi di latenza che fanno infuriare nei giochi online.
La perdita di pacchetti è un segnale di allerta ancora più grande. Anche una perdita dell'1% di pacchetti può assolutamente paralizzare le applicazioni basate su TCP, costringendole a reinviare costantemente i dati e rallentando tutto a un passo da lumaca. Quando guardi i risultati del tuo test, qualsiasi reale differenza tra pacchetti inviati e pacchetti ricevuti deve essere indagata immediatamente.
Uno dei più grandi errori che vedo fare alle persone è assumere che un singolo test racconti l'intera storia. Le condizioni di rete cambiano costantemente. Un test eseguito alle 3 del mattino apparirà completamente diverso da uno alle 3 del pomeriggio durante le ore di punta. L'unico modo per ottenere una vera base di riferimento delle prestazioni è attraverso test coerenti e ripetuti.
Per anticipare i problemi, vale la pena esplorare strumenti dedicati per il monitoraggio delle prestazioni di rete. Questo sposta il tuo approccio da una frenetica riparazione delle cose quando si rompono a un mantenimento proattivo della salute della tua rete.
Gli Errori di Misurazione più Comuni
Anche con i migliori strumenti del mondo, alcuni semplici errori possono rendere i tuoi risultati completamente inutili. Evitare queste trappole comuni è non negoziabile se desideri dati di cui puoi davvero fidarti.
- Testare tramite Wi-Fi: Seriamente, non farlo. Le connessioni wireless sono notoriamente capricciose, soggette a interferenze da tutto, dai microonde al router del tuo vicino. Per qualsiasi test di latenza serio, collegati con un cavo Ethernet. È l'unico modo per ottenere una base di riferimento stabile e affidabile.
- Dimenticare l'Overhead del VPN: I VPN sono ottimi per la sicurezza, ma aggiungono una fermata extra e crittografia al viaggio del tuo traffico. Questo aumenterà sempre la latenza. Se stai cercando di diagnosticare una connessione lenta di un utente, una delle tue prime domande dovrebbe essere: "Sei con il VPN?" Testare con e senza di esso ti mostrerà esattamente quanto ritardo sta aggiungendo.
- Ignorare la Congestione della Rete Locale: I tuoi risultati di test saranno distorti se qualcun altro sulla tua rete sta occupando tutta la larghezza di banda. Se un collega sta trasmettendo video in 4K o scaricando file enormi mentre stai testando, i tuoi numeri di latenza saranno gonfiati e finirai per inseguire un problema che non esiste.
Un altro fattore sottile ma critico è lo strumento che scegli. Come abbiamo coperto, diversi strumenti misurano la latenza in modi diversi. Sii sempre coerente con gli strumenti che usi per il confronto e assicurati di capire cosa misura realmente ciascuno di essi—che si tratti di un semplice echo ICMP o di una richiesta complessa a livello di applicazione. E ricorda, le prestazioni possono essere influenzate da molti strati; ad esempio, se stai approfondendo le prestazioni web, la nostra guida su un Cookie Editor Chrome Extension può mostrare come gli elementi lato client giochino un ruolo.
Interpretando i tuoi risultati con il giusto contesto e evitando questi errori comuni, passerai oltre la semplice raccolta di numeri. Inizierai a comprendere il perché dietro le prestazioni della tua rete, e questo è la chiave per costruire sistemi più veloci e affidabili.
Domande Comuni sulla Latenza di Rete
Anche con gli strumenti giusti, alcune domande comuni sembrano sempre emergere quando inizi a scavare nella latenza di rete. Esploriamo alcune delle più frequenti che sento per aiutarti a dare senso ai tuoi risultati.
Qual è un Numero di Latenza “Buono”?
Questa è la classica domanda "dipende", ma possiamo sicuramente stabilire alcuni benchmark solidi. Una latenza "buona" è completamente relativa a ciò che stai cercando di realizzare.
- Navigazione Web Casuale: Per la maggior parte di noi, qualsiasi cosa sotto 100ms di RTT sembrerà perfettamente accettabile. Le pagine si caricano rapidamente e non noterai alcun ritardo reale.
- Gioco Online Competitivo: Qui ogni millisecondo conta. I giocatori seri e i trader ad alta frequenza cercano latenza ben al di sotto di 20ms. È la differenza tra vincere e perdere.
- Videochiamate & VoIP: Qui, la coerenza è fondamentale. Hai bisogno di una latenza stabile sotto 150ms e basso jitter (meno di 30ms) per evitare quella sensazione di scatti e fuori sincrono o, peggio, chiamate interrotte.
Come regola generale, la maggior parte dei professionisti di rete che conosco classificherebbe qualsiasi cosa sotto 50ms come bassa latenza. Da 50-150ms è moderata, e una volta che superi 150ms, inizierai a sentire il rallentamento nella maggior parte delle applicazioni interattive.
Perché i Risultati del Mio Ping e del Test di Velocità del Browser Non Corrispondono Mai?
Questa è una domanda fantastica e un punto di confusione molto comune. Accade perché un ping da riga di comando e un test di velocità basato su browser sono strumenti fondamentalmente diversi che misurano cose diverse.
Per cominciare, stanno quasi certamente comunicando con server diversi. Quando pinghi un dominio, stai colpendo un obiettivo specifico. Un test di velocità web, d'altra parte, è progettato per trovare un server geograficamente vicino dalla propria rete per darti il miglior risultato possibile.
I protocolli sono anche completamente diversi. Ping utilizza un protocollo molto leggero chiamato ICMP. La maggior parte dei test del browser funziona su TCP, che richiede un intero processo di configurazione (il "three-way handshake") solo per stabilire una connessione. Quella iniziale andata e ritorno aggiunge un po' di tempo prima che il vero test inizi.
Infine, i test del browser spesso includono più del semplice tempo di viaggio della rete. Il loro numero di "latenza" potrebbe includere il tempo di elaborazione del server o persino piccoli ritardi all'interno del tuo browser stesso, il che può gonfiare la cifra finale rispetto a un ping ICMP grezzo.
Come Posso Effettivamente Ridurre la Mia Latenza di Rete?
Ridurre la latenza significa individuare ed eliminare i colli di bottiglia, che si trovino nel tuo ufficio o attraverso internet.
Il primo posto da controllare è il tuo ambiente immediato. Il cambiamento più efficace che puoi fare è passare da una connessione Wi-Fi a una connessione Ethernet cablata. È un cambiamento radicale per stabilità e velocità. Se devi usare il Wi-Fi, avvicinati al tuo router e passa alla banda 5GHz se puoi: di solito è meno affollata.
Guardando oltre la tua rete locale, a volte uno scambio di DNS può aiutare. Utilizzare un server DNS più veloce può ridurre di millisecondi il tempo di connessione iniziale quando cerchi un sito web.
Se stai cercando di migliorare l'accesso a un servizio che controlli, una Content Delivery Network (CDN) è la risposta. Funziona posizionando copie dei tuoi contenuti fisicamente più vicine ai tuoi utenti. E se stai usando una VPN, prova a disattivarla. Quella ulteriore connessione e il livello di crittografia aggiungono quasi sempre latenza.
Ho visto VPN aziendali aggiungere fino a 70ms a un tempo di andata e ritorno. Può trasformare una grande connessione in una frustrante connessione lenta. Testa sempre con e senza la tua VPN per vedere quale tipo di impatto sulle prestazioni stai effettivamente subendo.
Qual è la vera differenza tra latenza e larghezza di banda?
Capire questo è fondamentale per comprendere le prestazioni della rete. È facile confonderli, ma misurano due cose molto diverse.
Ecco l'analogia che uso sempre: pensala come un'autostrada.
- Larghezza di banda è quanti corsie ha l'autostrada. Più corsie significano che più auto (dati) possono viaggiare contemporaneamente.
- Latente è il limite di velocità. Determina quanto velocemente una singola auto (un pacchetto di dati) può andare da A a B.
Potresti avere un'enorme autostrada a dieci corsie (larghezza di banda enorme) con un limite di velocità di 20 mph (alta latenza). Potresti trasferire un sacco di dati alla fine, ma cose in tempo reale come una videochiamata sarebbero dolorosamente lente. D'altra parte, una connessione con latenza molto bassa si sente incredibilmente reattiva e veloce, anche se la sua larghezza di banda non è enorme. Hai davvero bisogno di un buon equilibrio tra entrambi per un'ottima esperienza.
Pronto a rendere il testing delle prestazioni una parte fluida del tuo flusso di lavoro quotidiano? La suite ShiftShift Extensions offre un potente Speed Test, un formattatore JSON e dozzine di altri strumenti per sviluppatori direttamente nel tuo browser, accessibili con un solo comando. Smetti di destreggiarti tra le schede e inizia a lavorare in modo più intelligente. Scarica ShiftShift Extensions gratuitamente e potenzia la tua produttività oggi stesso.