リッチテキストからマークダウンへの究極の変換ガイド
壊れたフォーマットにうんざりですか?リッチテキストをマークダウンに完璧に変換する方法を学びましょう。開発者ツール、クリップボードのトリック、ワークフローの自動化をマスターしましょう。

つまり、GoogleドキュメントやウェブページからMarkdownを使うプラットフォームに何かをコピーしようとして、すべてが壊れてしまうという状況です。リストはぐちゃぐちゃになり、太字のテキストは消え、見出しはプレーンテキストのまま。聞き覚えありませんか?
これは、誰もがいつかは経験する典型的な問題です。リッチテキストエディターのビジュアルな世界と、Markdownのクリーンでコードのような世界との間の摩擦なのです。
本質的には、 リッチテキストからMarkdownへの変換 すべてのビジュアルスタイル——太字、斜体、リンク、リスト——をMarkdownが理解するシンプルなプレーンテキスト構文に変換することを意味します。このステップを経なければ、大多数のMarkdownベースシステムが正しく解釈できない隠されたHTMLコードの塊を貼り付けるだけで終わってしまいます。
コンテンツ作成の二つの世界
一方には「見えたままがそのまま」("What You See Is What You Get"、略称WYSIWYG) エディタ。例えば Google Docs, Notion、あるいはメールの作成画面など。直感的なのは、ボタンをクリックするだけでテキストを太字にでき、それがそのまま 見えます 太字になります。すべて視覚的です。
一方、Markdownがあります。これはシンプルさと読みやすさのために構築された軽量マークアップ言語です。隠されたコードの代わりに、例えばアスタリスクのような単純な文字を使って **bold** を、ハッシュタグを使って # Headings開発者ドキュメント、技術ブログ、バージョン管理の標準として定着している理由があります。それは、クリーンで、ポータブルで、予測可能な形式だからです。
この問題が生じるのは、2つのシステムがフォーマットの「考え方」で根本的に異なるためです。これは開発者ツールが主流になるにつれて、より重大な問題になりました。2000年代後半から、Markdownは技術文書の書き手に静かに浸透していきました。 GitHubは2008年にMarkdownサポートを追加し、 2億のリポジトリ 2023年までに—この変換を正しく行うことは、今や私たちの多くにとって日常的な作業となっています。
リッチテキストとMarkdownの主な違い
なぜ単純なコピー&ペーストが頻繁に失敗するのかを本当に理解するには、主な違いを並べて見ることが役立ちます。リッチテキストはその複雑さをビジュアルインターフェースの背後に隠していますが、Markdownはそのシンプルな構文を目に見えるようにし、簡単に制御できるようにしています。
| 属性 | リッチテキスト(HTML/WYSIWYG) | Markdown |
|---|---|---|
| 書式設定 | 非表示のHTMLタグまたは独自コードとして保存されます。 | プレーンテキスト文字として保存されます(例: **bold**, *italic*). |
| 移植性 | 異なるアプリケーション間で移動すると、しばしば破損します。 | 非常に高い移植性を持ち、プラットフォーム全体で一貫して動作します。 |
| 可読性 | 生のコードは非開発者には読みにくい。 | プレーンテキストはクリーンで読みやすい。 |
| コントロール | 視覚的ツールを提供しますが、不要なスタイルが追加される可能性があります。 | すべての要素に対して正確で明示的な制御を提供します。 |
結局のところ、リッチテキストを正しく変換する方法を知ることは、見た目を整えるだけでなく、文書をクリーンに保ち、コンテンツワークフローをスムーズにし、ほぼすべての現代的な技術環境でコラボレーションを効果的に行うために必要なスキルです。
"手軽で簡単"なオンラインコンバーターの隠れたコスト
さて、リッチテキストをMarkdownに変換する必要がありますね。最初の一歩は何でしょうか?私たちのほとんどは、まずは無料のオンラインツールを検索します。シンプルなペースト&ゴーのインターフェースがあるサイトを見つけ、Google Docのコンテンツを貼り付けると—瞧— 見た目 は綺麗なMarkdownになっています。一見成功したように感じられますが、これは信頼に足ります。特に重要なプロジェクトに取り組む際には、この方法は解決するよりも多くの頭痛の種を生むことが多いと断言できます。
私の目には最大の警告サインとして常に映るのは データプライバシーランダムなウェブサイトにテキストを貼り付けると、あなたのコンテンツは第三者のサーバーに渡されます。もしそのテキストが未公開の製品ドキュメント、社内のメモ、あるいは少しでも機密性の高いものであれば、重大なセキュリティリスクを生むことになります。そのデータがどのように保存され、記録され、将来的にどのように使用される可能性があるのか、まったくわからずにおかれます。
プライバシーを気にしないとしても、出力品質がしばしば合否を分ける要因となります。これらの単純なツールは、通常、最基本的な処理のみに焦点を当てて作られています。ネストされたリスト、結合されたセルを含むテーブル、あるいは元のエディタからの特定のフォーマットなど、少し複雑なものを投げかけると、たちまち問題が発生します。結局、ツールを使って「節約」したつもりが、乱雑に崩れたものを修正するためにさらに多くの時間を費やすことになるのです。
修正作業の問題点
よくあるシナリオを一緒に見てみましょう:JekyllやHugoのような静的サイトジェネレーター用のMarkdownファイルに、技術ブログ記事の下書きを共有ドキュメントから移動するケースです。ドキュメントには通常、見出し、太字テキスト、コードブロック、そしていくつかのリストといった典型的な要素が含まれています。
基本的なオンライン変換ツールなら、見出しや太字は正しく処理できるかもしれませんが、細部で失敗します。
- コードブロック: プロパーにバッククォート3つ(```)で囲まれる代わりに、注意深くフォーマットされたコードスニペットがプレーンテキストとして吐き出され、インデントや構文のヒントがすべて失われることがよくあります。
- ネストされたリスト: 多階層のアウトラインが、完全にフラットな単一階層の長いリストに変換され、文書の論理的な流れが台無しにされることがあります。
- 文字エンコーディング: 特殊文字や絵文字が化け、奇妙な記号が最終ドキュメント全体に散らばってしまうことがあります。
これは、多くのオンラインエディターの現状です。綺麗で、ゼロからMarkdownを書くには素晴らしいツールですが、インポートされたリッチテキストのニュアンスを処理するための「貼り付けて変換」のロジックが組み込まれていないのです。
「無料」のコンバーターの本当のコストはお金ではありません。手動での修正作業に費やす時間と、データを扱うリスクです。より多くの作業を生み出すツールは、解決策とは言えません。
結局のところ、これらのブラウザ内ツールは、単純なテキストの簡易・非機密の変換には許容できるかもしれませんが、本格的なワークフローにおいては脆く非効率なステップを導入します。小さなフォーマットミスを修正するために費やす時間は急速に積み重なり、信頼性の高いリッチテキストからMarkdownのプロセスを必要とする人にとって、この一般的な第一歩は悪い選択となります。
コマンドパレットによるスマートなワークフロー
正直に言えば、手動変換は面倒です。タブラウザを行き来し、ランダムなオンラインツールにテキストを貼り付け、それをコピーして戻す――これは気晴らしもつかず、手間のかかる一連の作業であり、集中を妨げます。これを1日 dozen回行えば、失われた時間と集中力は本当に積み重なってきます。
しかし、その Entireなプロセスが、今いるページから離れる必要なく、瞬時に行えるとしたら?
ShiftShift Extensionsコマンドパレットのようなツールを使った、キーボードファーストのアプローチが、完全に状況を変えます。サイトに移動する代わりに、キーボードショートカットでコマンドバーを呼び出すだけです。これは煩雑な雑務を、自然なワークフローにシームレスに統合される、一瞬で終わる作業に変えてくれます。
変換を瞬時に実行
すべてのアイデアはスピードを念頭に作られています。例えば、Googleドキュメントやブログ記事からフォーマットされたテキストの塊をコピーした直後を想像してください。そのリッチテキストがクリップボードに乗っている状態で、コマンドパレットを呼び出すだけです。
Macでは、Cmd+Shift+Pと素早く実行できます。WindowsやLinuxでは、Ctrl+Shift+P.
パレットが開いたらすぐに「markdown」と入力します。「リッチテキストをMarkdownに変換」というコマンドが表示されます。Enterを押すと、バッテン—完璧にフォーマットされたMarkdownがクリップボードにコピーされ、必要な場所に貼り付ける準備ができています。全体でわずか2秒ほど。コンテキストの切り替えも、フォーカスの丧失もありません。
ここで重要なのは単なるスピードではなく、セキュリティです。ShiftShift这样的なツールはすべての処理をブラウザ内でローカルに行います。データがサードパーティのサーバーに送信されることは一切ないため、ほとんどのオンラインコンバーターで発生するプライバシー上のリスクを完全に回避できます。
このフローチャートは、この判断を非常に明確に示しています。
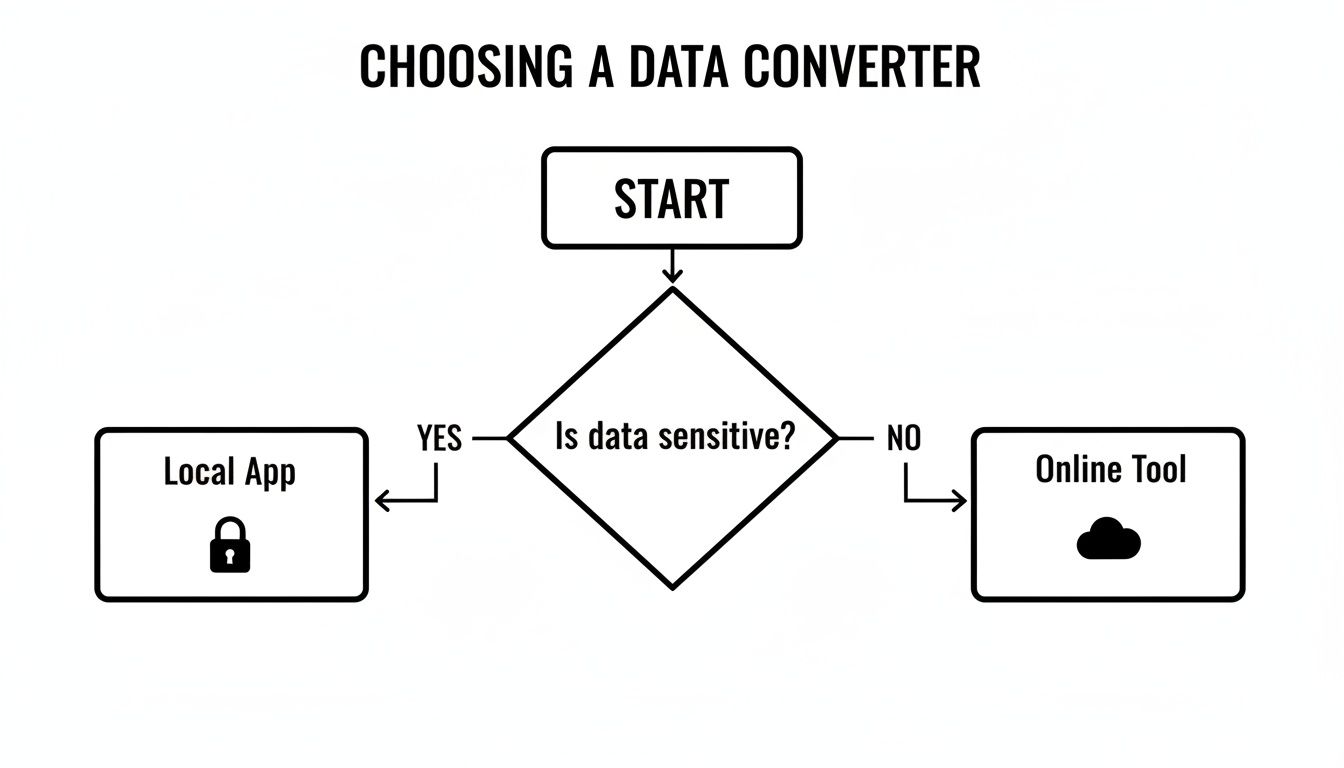
結論はシンプルです。データが少しでも機密性を伴うものであれば、ローカルでオフラインファーストのツールのみが選択肢となります。
インテグレーションツールとオンラインツールの比較
コマンドパレットはスタイリッシュで安全なソリューションを提供しますが、他の方法とどのように比較されるか見てみる価値はあります。例えば、オンラインMarkdown WYSIWYGエディタはビジュアルインターフェースを提供し、フォーマットを即座に確認する際に本当に役立ちます。
しかし、根本的な違いはワークフローにあります。オンラインツールは常にアクセスする別の目的地です。インテグレートされたコマンドパレットは、今いる場所で実行するアクションです。
この違いがまさに、多くの開発者やライター、パワーユーザーが主要な環境の中に存在するツールに惹かれる理由です。ブラウザベースの生産性を本当に向上させたいなら、最高の生産性Chrome拡張機能をhttps://shiftshift.app/blog/best-productivity-chrome-extensionsで確認することで、何が可能かを理解できるでしょう。
最終的に、リッチテキストからMarkdownへの変換といった頻繁なタスクにおいて、統合ツールを選ぶことは、集中力とモメンタムを損なう小さな中断を排除することにほかなりません。
一般的な変換の落とし穴を回避する方法
あらゆるリッチテキストからMarkdownへのコンバーターの真のテストは、単純な太字や斜体テキストをどう処理するかではなく、複雑なコンテンツを投げかけたときにどう対応するかにあります。一瞬では滑らかな変換が行われても、リスト、テーブル、画像などが正しく変換されないために、苛立ちを伴う修正作業に陷入してしまうことがあります。
なぜこれらの要素が壊れるのかを理解することは第一歩です。ほとんどの場合、問題はリッチテキスト(しばしばHTMLベース)とMarkdownの基本的な設計の違いに帰着します。リッチテキストは視覚的な複雑さのために構築されていますが、Markdownは構造的なシンプルさを重視します。この衝突は、高度なフォーマットで明確に現れます。
ネストされたリストとの格闘
ネストされたリストは、最も頻繁に問題になる要素の一つです。元の文書では完璧に構造化されたアウトラインがあっても、変換後には単一の混乱した塊に平坦化されてしまうことがあります。
これは、リッチテキストエディタが複雑なHTML(<ul> や <ol> タグにネストされた <li> アイテムを使用してレベルを作成するため)であり、その構造がMarkdownの単純なインデントルールに常にきれいにマッピングされるとは限らないからです。
- 変換前(リッチテキスト): 親と子のアイテムが明確な、複数レベルのリストが表示されます。
- 不適切な変換後: 注意深く配置されたすべてのサブポイントが突然トップレベルに引き上げられ、階層構造が完全に崩れてしまいます。
修正はほぼ常に手動で行う必要があります。Markdownエディタに戻り、リストアイテムのインデントを調整し、元の構造を復元するためにスペース(通常はレベルごとに2または4スペース)に注意深く配慮する必要があります。
テーブルの問題
テーブルはもう一つの大きな問題です。Markdownのパイプテーブル構文は見事なほどシンプルですが、それが弱点でもあります。リッチテキストエディタで一般的な高度な機能を処理することができないのです。
複雑なテーブルが頻繁に壊れる理由は以下の通りです:
- 結合されたセル: Markdownテーブルには
colspanやrowspanの概念がありません。元のテーブルがセルを結合している場合、コンバーターは混乱する可能性が高いです。 - 複数行コンテンツ: 単一セル内の改行は、変換中にテーブル全体の構造を容易に破壊できます。
- インラインフォーマット: セル内の太字、斜体、リンクが正しく変換されないことがあります。
テーブルが壊れた場合、最善の方法はしばらずっとMarkdown構文を使って書き直すことです。手間はかかりますが効果的です。本当に複雑なデータの場合は、Markdownファイルに直接HTML<table>ブロックを埋め込む方が良いかもしれません。ほとんどのレンダラーはそれを問題なく表示します。
根本的な課題は、リッチテキストとMarkdownが構造情報を根本的に異なる方法で保存しているという点です。これは大規模な移行作業で特に顕著になり、手動での修正は非現実的です。
私は大規模プロジェクトでそれを実際に経験しました。数千のファイルを一括移行すると、破損したテーブルセルの結合、一貫性のない見出しレベル、大量のクリーンアップ作業を要するHTMLフラグメントなど、あらゆる構造的問題が露呈します。変換スクリプティングに関するコミュニティディスカッションで、開発者がどのように这些问题を現実的に解決しているかを深く掘り下げた、素晴らしい議論が見つかるかもしれません。
消える画像とメディア
最後に画像について話しましょう。Webページやドキュメントからリッチテキストをコピーする際、実際の画像ファイルをコピーしているわけではありません。それへの参照をコピーしているだけです。ほとんどの基本的なコンバーターは、その参照をどう処理すればよいかわかりません。
結果としてどうなるか?画像は消えてしまい、壊れたリンクが残るか、最悪の場合は何も残りません。
これを修正するには、Markdownの構文を使って画像を再挿入する必要があります:。つまり、まずパブリックURLでアクセスできる場所に画像をアップロードし、そこにリンクする必要があります。
複数の書式エラーが発生している場合、すべての小さな不一致を見つけるのは困難です。この点では、並べて比較するツールがまさに救命策です。
以下の表は、私が遭遇した最も一般的な問題とその迅速な修正方法をまとめたものです。
一般的な変換エラーのトラブルシューティング
| 問題领域 | 典型的な問題 | 推奨される修正方法 |
|---|---|---|
| ネストされたリスト | すべてのサブアイテムが単一レベルのフラットなリストに変換され、階層構造が失われます。 | 各サブアイテムの前にインデント(通常2~4つのスペース)を手動で追加して、構造を復元します。 |
| テーブル | テーブル構造が崩れる、特に結合セルやセル内の複数行テキストを扱う際に顕著です。 | Markdownのパイプ構文を使ってテーブルを再構築してください。複雑なケースでは、元のHTMLテーブルを埋め込んでください。 |
| 画像 | 画像が変換後に完全に消えたり、リンク切れとして表示されたりします。 | 画像をホスティングサービスにアップロードし、公開URLを取得して、構文で再挿入してください。 |
| 特殊文字 | <, >や&などの文字が誤って解釈され、レイアウトが崩れることがあります。 |
これらの文字をバックスラッシュで手動エスケープするか(例:\<)、HTMLエンティティに置き換えてください。 |
差分チェッカーを使ってソースと出力を比較すると、このプロセスが大幅に楽になります。オンラインユーティリティを使用して、テキストを無料でオンラインで比較できます(https://shiftshift.app/blog/compare-text-online-free)。元のテキストと変換後のテキストを並べて貼り付けるだけで、フォーマットエラーをほぼ瞬時に特定できます。
上級ユーザー向けの自動変換
開発者や技術ライター、または大量のコンテンツを扱う人にとって、手動でのドキュメント変換は持続可能な方法ではありません。大量のファイルに直面している場合や、変換をアプリに組み込む必要がある場合は、プログラムmaticなアプローチを検討する必要があります。ここでは、単純なコピペのテクニックを離れ、ワークフロー全体を自動化します。
これはもはや特殊な問題ではありません。リッチテキストをクリーンなMarkdownに変換する必要性は、数多くのツールにおいて核となる要件となっています。これには現実の挫折体験が大きく寄与しています。私はJoplinのようなコミュニティで実際にそれを目の当たりにし、ユーザーが他のアプリからノートをインポートしても、再読み込み時にフォーマットが消えてしまうのを見てきました。そうした頭痛の種が、開発者にコンバータをソフトウェアに組み込ませるのです。DEVONtechnologiesコミュニティフォーラム.
JavaScriptライブラリを活用する
Web開発の世界にいるなら、JavaScriptライブラリはこのタスクにおいてあなたの最高のパートナーです。私がお勧めするのは turndownです。HTMLを受け取り、美しくクリーンなMarkdownを出力する、信じられないほど強力で設定可能なライブラリです。Node.jsのサーバーサイドスクリプトでも、クライアントサイドアプリケーションでも、同様にうまく機能します。
例えば、ローカルHTMLファイルを処理してMarkdownとして保存するためのNode.jsスクリプトを手軽に作成できます。
const TurndownService = require('turndown');
const fs = require('fs');
const turndownService = new TurndownService();
const htmlContent = fs.readFileSync('source.html', 'utf8');
const markdown = turndownService.turndown(htmlContent);
fs.writeFileSync('output.md', markdown);
console.log('Conversion complete!');
この種のスクリプトは、ファイルが一杯のフォルダを一括処理したり、より大きなコンテンツパイプラインに変換ステップを組み込むのに最適です。
プログラマティックな変換の本当の魔法は一貫性にあります。一度ルールを設定すると、すべての変換が同じロジックに従います。これにより、手作業で生じるヒューマンエラーとランダムな不一致が完全に排除されます。
もう一つの巧妙な技術は、ブラウザ内で貼り付けイベントを直接処理することです。ユーザーが貼り付けたHTMLコンテンツをキャプチャし、即座にMarkdownに変換してから、クリーンなバージョンをテキストエディタに挿入するJavaScriptを書くことができます。これにより、GoogleドキュメントやWordからの雑然としたコンテンツを自動的に整理し、シームレスな体験を生み出します。これは些細な機能のように思えるかもしれませんが、ウェブベースのエディタを構築する人にとっては、ゲームチェンジャーとなるでしょう。
ライブラリとCLIツールの選択
単純なHTMLを超える必要がある場合、強力なツール、コマンドラインインターフェース(CLI)ツールが必要かもしれません。この分野では、 Pandoc が揺るぎないチャンピオンです。それは文書変換のスイスアーミーナイフのような存在です。 turndown のようなライブラリはHTMLからMarkdownへの変換には素晴らしいですが、PandocはDOCXやRTF、LaTeXなど数十の形式を処理し、双方向に変換できます。
では、どちらを選ぶべきでしょうか?これは本当にプロジェクトによります。
- Webアプリケーションを構築している場合、またはNode.js環境で作業している場合は、JSライブラリ(
turndown) )を使用してください。軽量で、焦点が絞られており、タスクを完璧にこなしてくれます。 - CLIツール(Pandoc)を使用してください 様々なファイル形式を扱う際や、コマンドをパイプで繋げて作業できるシェルスクリプト環境で作業する際に役立ちます。
コードを深く掘り下げることなくオートメーションの力を必要とする方には、ShiftShift拡張機能のようなブラウザベースのツールが中間的な道筋として最適です。スクリプト化されたソリューションの速さと信頼性を、使いやすいコマンドパレットの中に完全に統合して提供します。これはほとんどのパワーユーザーにとって理想的なバランスです。
異なるフォーマットがどのように振る舞うかを考えることは、例えばWordからPDFへの変換方法に関するガイドで説明したように、ドキュメントワークフローについてより多くのコンテキストを与えてくれます。さらに広い視野を得るために、PDFからMarkdownへの変換方法に関するリソースを探索すると、ドキュメント変換の世界がどれほど深く広がっているかを示しています。
リッチテキストをMarkdownに変換する際のよくある質問
しっかりしたワークフローがあったとしても、リッチテキストをMarkdownに変換する过程中でいくつかの想定外の問題に遭遇することがあります。特定のファイルでつまずく場合もあれば、より良い方法があるのかどうか疑問に思うこともあります。この変換を行っている方々からよくいただく質問のいくつかについて、詳しく見てみましょう。
これらの詳細を整理することで、一般的な問題を回避し、実際に頼りになるプロセスを構築するのに役立ちます。
オンラインコンバーターは安全に使用できるか?
これはコンテキストによります。オンラインのリッチテキストからMarkdownへのコンバーターの安全性は、結局のところ、変換する内容によって決まります。公開ブログ記事の草稿やその他の非機密情報であれば、おそらく問題ないでしょう。しかし、社内文書、プライベートなメモ、または機密情報を含むものを扱っている場合、ランダムなウェブサイトに貼り付けることは大きなセキュリティリスクとなります。
一般的なルールとして、データが公開できないものである場合、変換プロセスも公開されるべきではありません。機密性の高いコンテンツを第三者のサイトに貼り付けた瞬間、あなたは制御を失います。そのデータがどこに保存され、誰がアクセスできるかを知ることはできません。
WordやGoogleドキュメントからコピー&ペーストしても良いですか?
できますが、注意が必要です。GoogleドキュメントやMicrosoft Wordからコピーすると、テキストだけでなく、書式を記述する複雑なHTMLの詰め合わせもコピーしています。
- シンプルな文書(太字テキスト、イタリック体、基本的なリストのみ)の場合、ほとんどの優れたコンバーターは、クリップボード内のHTMLを問題なく処理できます。
- 複雑な文書(表、脚注、トラックされた変更、または埋め込みチャートを含むもの)の場合、変換はほぼ確実に雑になり、相当量の手動クリーンアップを必要とするでしょう。
助けて!変換後に画像が消えてしまいました。
これはおそらく最も一般的な「落とし穴」です。画像を含むリッチテキストをコピーする際、実際には画像ファイルそのものをコピーしているわけではありません。参照コピーしているだけであり、通常のコンバーターでは元のファイルに遡って追跡する方法がありません。
唯一の本当の解決策は、画像を別ステップとして扱うことです:
- まず、元の文書からすべての画像を保存します。
- 次に、それらをウェブサーバー、CDN、または使用しているアセットホストにアップロードし、各画像の公開URLを取得します。
- 最後に、Markdownファイルに戻り、正しい構文 `` を使って手動で追加します。
では、最も適したツールとは?
「最適な」ツールは、本当に誰が、何のために使いるかによって変わります。
機密性のないものを一度きりの迅速な変換であれば、評判の良いオンラインツールならどれでも可能です。しかし、常に行っているなら、ブラウザに組み込まれ、キーボードショートカットで操作されるツール — ShiftShiftコマンドパレットのように — は、比較にならないほど効率的で安全です。また、ファイルを一括変換したり、プロセスを自動化する必要がある開発者にとっては、turndownライブラリのようなプログラマティックなツールの力や、Pandoc.
面倒なウェブツールや手動のクリーンアップに時間を費やすのをやめたくありませんか? ShiftShift Extensionsは、高速なコマンドパレットを通じて、強力でプライバシー重視のリッチテキストからMarkdownへのコンバーターをブラウザに直接統合しています。ページを離れる必要なく、クリップボードの内容を瞬時に変換します。今すぐShiftShift Extensionsをダウンロードして、ワークフローを変革しましょう。