Hoe Netwerk Latentie te Meten: Een Praktische Gids voor Ontwikkelaars
Leer hoe u netwerklatentie kunt meten met deze uitgebreide gids. We behandelen essentiële tools zoals ping en traceroute en browsergebaseerde testtechnieken.

Aanbevolen extensies
Wil je de netwerklatentie meten? Je kunt beginnen met eenvoudige, ingebouwde opdrachtregelhulpmiddelen zoals ping en traceroute om een snelle meting van de Round-Trip Time (RTT) te krijgen. Of je kunt de ontwikkelaarstools van je browser openen om te zien hoe vertragingen de ervaring van je gebruikers beïnvloeden.
Deze methoden geven je een snelle, nuttige momentopname van hoe lang het duurt voordat een datapakket van een bron naar een bestemming reist en weer terug.
Waarom het meten van latentie niet onderhandelbaar is
Voordat we ingaan op het "hoe", laten we het hebben over het "waarom". Voor ontwikkelaars en netwerkingenieurs is latentie niet zomaar een getal op een scherm; het is de onzichtbare hand die de hele gebruikerservaring vormgeeft. In de applicaties van vandaag zijn milliseconden alles. Zelfs een kleine vertraging kan het verschil maken tussen een service die onmiddellijk aanvoelt en een die gebroken aanvoelt.
Denk aan de gevolgen in de echte wereld:
- API-responsiviteit: Een enkele trage API-aanroep kan een domino-effect creëren, waardoor alles van het laden van een gebruikersprofiel tot het verwerken van een kritieke betaling wordt vertraagd.
- Real-time gegevensstromen: Voor online gaming, live video of financiële handel is lage en consistente latentie de absolute basis. Zonder dit werken deze applicaties gewoon niet.
- Gebruikersbehoud: Er is een directe lijn die trage websites en apps verbindt met hogere bouncepercentages en verlaten winkelwagentjes. Dit heeft een grote impact op de winst.
Belangrijke latentieconcepten onderscheiden
Om netwerklatentie nauwkeurig te meten, moet je weten waar je naar kijkt. De twee meest fundamentele concepten zijn Round-Trip Time (RTT) en eenrichtingslatentie.
RTT is de totale tijd die het kost voor een signaal om van punt A naar punt B en weer terug te gaan. Het is de meest voorkomende maatstaf die je zult zien omdat het eenvoudig te meten is—je hebt alleen toegang nodig tot één uiteinde van de verbinding.
Eenrichtingslatentie, zoals de naam al aangeeft, meet de tijd die het kost voor gegevens om in slechts één richting te reizen. Dit is een veel moeilijker te meten waarde omdat het perfect gesynchroniseerde klokken aan beide uiteinden vereist. Het is echter een veel preciezere indicator voor asymmetrische verbindingen, waar je upload- en downloadpaden heel anders functioneren.
Het belang van dit alles wordt kristalhelder wanneer je serieuze belastingprestatietests uitvoert, waar theorie de realiteit ontmoet en knelpunten worden blootgelegd.
Om wat cijfers te geven, classificeren netwerkmonitoringexperts latentie doorgaans als volgt:
- Lage latentie: Onder 50 milliseconden
- Gematigde latentie: 50-150 ms
- Hoge latentie: Boven 150 ms
Uit mijn ervaring kan een snelle test naar een nabijgelegen server een volkomen acceptabele 20-40 ms laten zien. Maar dat getal kan gemakkelijk oplopen tot meer dan 200 ms voor verkeer dat een oceaan moet oversteken, wat een game-changer kan zijn voor de prestaties van je applicatie.
Om de jargon die je tegenkomt te begrijpen, hier is een snelle referentie.
Belangrijke latentieconcepten in een oogopslag
| Concept | Wat het meet | Waarom het belangrijk is |
|---|---|---|
| Latentie (Ping) | De tijd die het kost voor een enkel datapakket om van een bron naar een bestemming en weer terug te reizen. Gemeten in milliseconden (ms). | Dit is de ruwe maat voor vertraging. Lage latentie is cruciaal voor real-time applicaties zoals gaming, VoIP en videoconferenties. |
| Round-Trip Time (RTT) | In wezen hetzelfde als latentie, dit is de totale duur voor een signaal om te worden verzonden plus de tijd die nodig is om een bevestiging te ontvangen. | RTT is de meest gebruikelijke en praktische manier om latentie vanaf één punt te meten, waardoor het de standaardmaatstaf is voor tools zoals ping. |
| Eenrichtingslatentie | De tijd die het kost voor een pakket om van de bron naar de bestemming in één richting te reizen. | Biedt een meer gedetailleerd overzicht, vooral voor asymmetrische netwerken waar upload- en downloadpaden verschillende latenties hebben. |
| Jitter | De variatie in latentie in de tijd. Het meet de inconsistentie van de aankomsttijden van pakketten. | Hoge jitter is net zo slecht als hoge latentie voor streamingmedia en online gesprekken, wat leidt tot haperingen, buffering en glitches. |
| Bandbreedte | De maximale hoeveelheid gegevens die in een bepaalde tijd over een netwerkverbinding kan worden verzonden. Gemeten in Mbps of Gbps. | Vaak verward met snelheid, bandbreedte gaat over capaciteit. Je kunt een hoge bandbreedte hebben maar toch lijden onder hoge latentie. |
Deze concepten zijn de bouwstenen voor het begrijpen van elk netwerkprestatieprobleem.
Dit is waar het hebben van toegankelijke, geïntegreerde tools zo belangrijk wordt. In plaats van complexe diagnostische suites uit te voeren, kunnen moderne browserextensies en ontwikkeltools je de inzichten geven die je nodig hebt zonder je workflow te verlaten. Het gaat erom dat het meten van latentie een moeiteloos, routinematig onderdeel wordt van het bouwen en onderhouden van geweldige software.
Je handen vuil maken met opdrachtregel-latentiehulpmiddelen
Om echt een gevoel te krijgen voor de prestaties van je netwerk, moet je de terminal openen. De opdrachtregel is waar je de fundamentele tools vindt die je ruwe, ongefilterde gegevens over je verbinding geven. Het gaat erom te zien wat er echt gebeurt met de pakketten die tussen jou en een bestemming bewegen, en het is de essentiële eerste stap voor elke ontwikkelaar die serieus is over het meten van latentie.
De klassieke, go-to utility is ping. Het is prachtig eenvoudig: het stuurt een klein datapakket (een ICMP echo-aanroep) naar een server en wacht gewoon tot het terugkomt. Die eenvoudige rondreis is de basis voor het berekenen van Round-Trip Time (RTT) en geeft je een directe gezondheidscheck van een verbinding.
Je eerste latentiecontrole met Ping
Een ping test uitvoeren kan niet eenvoudiger. Start je terminal of opdrachtprompt, typ ping, en volg dit met het domein dat je wilt testen.
Standaard blijft ping voor altijd doorgaan op macOS en Linux, terwijl Windows slechts vier pakketten verzendt en stopt. Voor enige echte analyse wil je dit controleren. Tien of twintig pakketten verzenden geeft je een veel betrouwbaarder beeld van de stabiliteit van de verbinding dan slechts een paar.
Als het klaar is, krijg je een net overzicht met de cruciale cijfers:
- Verzonden/Gekregen pakketten: Dit vertelt je of er gegevens onderweg zijn verloren. Zelfs een kleine hoeveelheid pakketverlies is een grote rode vlag voor netwerkproblemen.
- Round-trip min/avg/max/mdev: Dit zijn je kernlatentiestatistieken. Je krijgt de beste tijd (
min), het gemiddelde (avg), en de slechtste tijd (max). Demdev(gemiddelde afwijking) is je maat voor jitter—hoeveel de latentie varieert van het ene pakket naar het andere.
Let goed op de kloof tussen je minimum en maximum RTT. Als deze breed is, is je verbinding onstabiel, zelfs als het gemiddelde er goed uitziet. Deze jitter kan veel disruptiever zijn voor real-time apps zoals videogesprekken of gaming dan een verbinding die consistent een beetje traag is.
Een veelgemaakte fout is alleen maar naar de gemiddelde RTT te kijken. Een gemiddelde van 50ms lijkt misschien prima, maar als je minimum 20ms is en je maximum 250ms, zal de gebruikerservaring haperig en onbetrouwbaar aanvoelen. Kijk altijd naar het volledige bereik om jitter te begrijpen.
De sporen volgen met Traceroute en MTR
Dus, wat doe je als ping hoge latentie of pakketverlies onthult? Je volgende taak is om te achterhalen waar het probleem zich bevindt. Dat is waar traceroute (of tracert op Windows) voor is. Het brengt het hele pad in kaart dat je pakketten afleggen, en toont je elke enkele "hop"—elke router—tussen jouw machine en de uiteindelijke bestemming.
Elke regel in de traceroute output is een hop, en het toont meestal drie afzonderlijke latentiemetingen tot dat punt. Dit stelt je in staat om te pinpointen of een specifieke router langs het pad een grote vertraging veroorzaakt of pakketten verliest.
Maar traceroute is een eenmalige momentopname. Voor een meer dynamische, continue kijk, zweren de meeste netwerkprofessionals die ik ken bij MTR (My Traceroute). MTR is als een supercharged tool die ping en traceroute combineert. Het stuurt constant pakketten naar elke hop op de route, waardoor je een live, actuele weergave van latentie en pakketverlies op elk punt krijgt. Dit maakt het ongelooflijk effectief in het opvangen van intermitterende problemen die een enkele traceroute waarschijnlijk zou missen.
Waarom je keuze van tool belangrijk is
De tool die je kiest en hoe je deze configureert, kan je resultaten drastisch veranderen. Dit is vooral waar in ultra-snelle, laag-latente omgevingen zoals cloud-datacenters.
Het is eigenlijk behoorlijk onthullend hoe verschillend de cijfers kunnen zijn. In een gedetailleerd experiment uitgevoerd door Google Cloud, rapporteerde een standaard ping test een gemiddelde RTT van 146 microseconden. Maar toen ze een andere tool gebruikten die transacties achtereenvolgens zonder pauze verzond, daalde de RTT tot slechts 66,59 microseconden—meer dan twee keer zo snel!
Dit is een perfect voorbeeld van waarom ping soms de latentie kan overschatten. Het toont aan dat het begrijpen van hoe een tool werkt cruciaal is voor het verkrijgen van metingen die je kunt vertrouwen.
De maximale snelheid van je verbinding vinden met iperf
Latentie is niet altijd het hele plaatje. Soms moet je weten hoeveel gegevens je verbinding daadwerkelijk kan doorgeven—de bandbreedte. Voor die taak is de tool die je wilt iperf.
Terwijl ping vertraging meet, draait iperf helemaal om doorvoer. Het werkt door een client-serververbinding op te zetten en vervolgens zoveel mogelijk gegevens tussen hen te versturen voor een bepaalde tijd.
Om iperf te gebruiken, heb je twee machines nodig:
- Op één machine voer je
iperfuit in servermodus. Het zal gewoon daar zitten en luisteren naar een verbinding. - Op de andere machine voer je
iperfuit in clientmodus, waarbij je het naar het adres van de server wijst.
De client zal verbinding maken en de test zal beginnen. De output vertelt je de totale hoeveelheid overgedragen gegevens en, het belangrijkste, de bitrate (je bandbreedte) in megabits of gigabits per seconde. Het is de perfecte manier om een netwerkverbinding onder druk te testen en te ontdekken wat het werkelijk kan.
Latentie meten vanuit het perspectief van de gebruiker
Hoewel opdrachtregelhulpmiddelen je een ruwe, ongefilterde kijk op je netwerk geven, is de enige latentie die echt telt voor een webapplicatie wat de eindgebruiker daadwerkelijk ervaart. Dit is waar we onze focus verschuiven van de terminal naar de browser zelf. Wat er binnen de browser gebeurt, vertelt een veel rijker, relevanter verhaal over prestaties.
Het gaat nooit alleen om de rondreis van een enkel pakket. De latentie die een gebruiker voelt is een complexe cocktail van DNS-zoekopdrachten, TCP-handshakes, TLS-onderhandelingen, serververwerkingstijd en natuurlijk de tijd die nodig is om de inhoud daadwerkelijk op het scherm weer te geven. Gelukkig zijn moderne browsers uitgerust met krachtige ingebouwde tools om ons te helpen dit hele proces te ontleden.
Duiken in de ontwikkelaarstools van de browser
Elke grote browser—Chrome, Firefox, Edge, Safari—wordt geleverd met een suite van ontwikkelaarstools. Het tabblad "Netwerk" binnen deze tools is je commandocentrum voor het begrijpen van hoe je site laadt. Het legt alles uit in een watervaldiagram, wat een visuele weergave is van elke enkele aanvraag die de browser doet om een pagina weer te geven.
Deze watervalweergave is van onschatbare waarde. Je kunt precies zien hoe lang elk onderdeel heeft geduurd om te downloaden, van het initiële HTML-document en CSS-stylesheets tot afbeeldingen en API-aanroepen. Belangrijker nog, het breekt de levenscyclus van elke aanvraag op in verschillende fasen:
- DNS-zoekopdracht: De tijd die nodig is om een domeinnaam naar een IP-adres te vertalen.
- Initiële verbinding: De tijd die besteed wordt aan het tot stand brengen van een TCP-verbinding met de server.
- SSL/TLS-handshake: De overhead die nodig is om een veilige verbinding op te zetten.
- Tijd tot eerste byte (TTFB): Dit is een grote. Het meet hoe lang de browser wachtte voordat hij de aller eerste byte gegevens van de server ontving.
- Inhoudsdownload: De tijd die besteed wordt aan het daadwerkelijk downloaden van de bron zelf.
Een hoge TTFB, bijvoorbeeld, is een klassiek teken van een trage backend of server-side verwerkingsprobleem—iets dat een eenvoudige ping test nooit zou onthullen. Door deze waterval te analyseren, kun je snel zien welke bronnen de weergave blokkeren of gewoon veel te lang duren om te laden.
Een belangrijke les uit mijn ervaring is om niet alleen naar de totale laadtijd te kijken, maar om te zoeken naar de langste balken in de waterval. Een enkele niet-geoptimaliseerde afbeelding of een trage derde partij API kan de hele pagina gijzelen, wat een slechte gebruikerservaring creëert, zelfs als de rest van de site razendsnel is.
Programma-matige meting met Timing API's
Voor meer geautomatiseerde en nauwkeurige metingen kun je gebruikmaken van de ingebouwde JavaScript API's van de browser. De Navigation Timing API en Resource Timing API geven je programmatic toegang tot dezelfde gedetailleerde prestatiegegevens die je in de ontwikkelaarstools ziet. Dit is perfect voor het verzamelen van gegevens voor real user monitoring (RUM) om te begrijpen hoe je site presteert voor daadwerkelijke bezoekers over de hele wereld.
Je kunt deze metrics ophalen met slechts een paar regels JavaScript, direct in de browserconsole. Om de kernprestatie-timings voor de hoofdpagina-lading te krijgen, kun je bijvoorbeeld performance.getEntriesByType('navigation') gebruiken. Dit retourneert een object vol waardevolle tijdstempels.
Van die gegevens kun je vitale metrics berekenen:
- DNS-zoekopdracht tijd:
domainLookupEnd - domainLookupStart - TCP-handshake tijd:
connectEnd - connectStart - Tijd tot eerste byte (TTFB):
responseStart - requestStart - Totaal pagina laadtijd:
loadEventEnd - startTime
Deze aanpak stelt je in staat om aangepaste dashboards te bouwen of prestatiegegevens naar je analysetools te sturen, waardoor je een continue vinger aan de pols houdt van de werkelijke prestaties van je applicatie. In webontwikkeling is het optimaliseren van afbeeldingen een veelvoorkomende manier om deze statistieken te verbeteren; voor degenen die geïnteresseerd zijn, hebben we een handige gids over het kiezen van het beste afbeeldingsformaat voor je website.
Checks Stroomlijnen met Geïntegreerde Tools
Tussen de terminal, browserontwikkeltools en aangepaste scripts springen kan snel vervelend worden. Dit is waar geïntegreerde browserextensies je workflow echt kunnen verbeteren door deze controles te verenigen. De ShiftShift Extensions suite bevat bijvoorbeeld een ingebouwde Speed Test tool die je direct vanuit elk tabblad kunt openen.
Dit biedt je een snelle, privacygerichte manier om de downloadsnelheid, uploadsnelheid en latentie van je verbinding te meten zonder dat je naar een aparte website hoeft te navigeren of een terminal hoeft te openen. Omdat het deel uitmaakt van een grotere toolkit, kun je een snelheidstest uitvoeren, een JSON-respons formatteren en een cookie controleren, allemaal vanuit dezelfde verenigde opdrachtpalet. Dit soort integratie maakt prestatiecontroles een natuurlijke, probleemloze onderdeel van de dagelijkse ontwikkelingsroutine.
Hoe Ontwerp je een Latentietest die Echt Iets Zegt
Iemand kan een ping commando uitvoeren en een getal terugkrijgen. Maar als je gegevens wilt die je echt kunt vertrouwen—gegevens die je helpen om echte beslissingen te nemen—moet je meer doordacht zijn. Een enkele, geïsoleerde meting is slechts een momentopname in de tijd. Om het gedrag van je netwerk echt te begrijpen, moet je denken als een detective, rekening houdend met waar je test, hoe vaak je test en waar je echt naar op zoek bent.
Een goed ontworpen test verandert ruwe cijfers in bruikbare inzichten. Een slecht ontworpen test? Het is gewoon ruis.
Het diagram hieronder breekt alle kleine vertragingen af die samenkomen in wat een gebruiker voelt wanneer ze een webpagina laden. Het is een geweldige herinnering dat een eenvoudige netwerkping niet eens begint te vertellen wat het hele verhaal is.
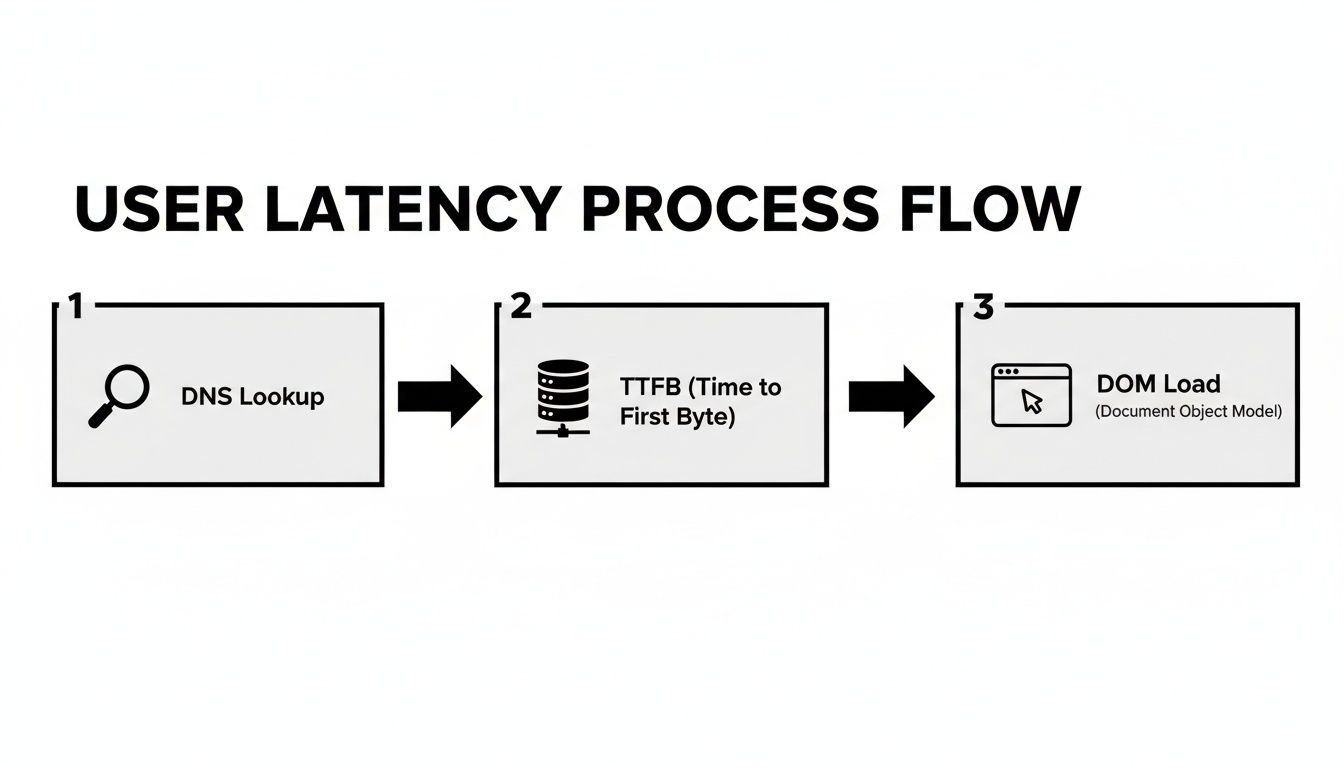
Zoals je kunt zien, dragen meerdere stappen bij aan de totale wachttijd, van de initiële DNS-opzoeking tot de uiteindelijke weergave.
Je Test Eindpunten Kiezen
De eerste regel van betrouwbaar testen is dat geografie belangrijk is. Een test vanuit je kantoor in New York naar een server verderop in New Jersey vertelt je absoluut niets over de ervaring van je klanten in Tokio. Om een realistisch beeld te krijgen, moet je testen vanuit diverse locaties die daadwerkelijk je gebruikersbasis weerspiegelen.
Je lijst met eindpunten moet een paar belangrijke gebieden dekken:
- Je Grootste Gebruikershubs: Waar wonen de meeste van je klanten? Test daar.
- Cross-Continentaal Verkeer: Kijk wat er gebeurt wanneer gegevens een oceaan moeten oversteken. Test tussen Europa en Noord-Amerika, of Azië en de VS, om de prestaties op lange afstand te begrijpen.
- Je Cloudregio's: Als je op AWS, Azure of GCP zit, test dan de connectiviteit naar en tussen de specifieke datacenterregio's waarop je vertrouwt.
Door je tests op deze manier te spreiden, creëer je een veel nauwkeuriger kaart van wereldwijde prestaties. Het helpt je om regio-specifieke knelpunten te spotten die je anders volledig zou missen. Dit is ook een goed moment om je domeininstellingen te dubbelchecken; je kunt nuttige tips vinden over hoe je de beschikbaarheid van een domein kunt controleren en gerelateerde configuraties om ervoor te zorgen dat alles in orde is.
De Juiste Testritme Vinden
Netwerkcondities zijn voortdurend in beweging. Ze veranderen gedurende de dag, de week en zelfs per minuut. Een test die om 3 uur 's nachts op een dinsdag wordt uitgevoerd, kan er fantastisch uitzien, maar dat resultaat is nutteloos als je piekverkeer om 14.00 uur op een vrijdag hebt wanneer iedereen online is.
Om een echte basislijn te krijgen, moet je consistent over de tijd testen. Varieer:
- Voer tests uit tijdens de piekuren van het bedrijf.
- Plan enkele voor onderhoudsvensters 's nachts.
- Vergeet de weekenden niet, wanneer verkeerspatronen volledig anders kunnen zijn.
Door gegevens herhaaldelijk te bemonsteren, kun je de willekeurige pieken en dalen gladstrijken. Dit is hoe je terugkerende problemen spot, zoals het netwerk dat elke werkdag in de namiddag congestie vertoont, direct na de lunch.
Vergeet de Jitter Niet
Gemiddelde latentie is een solide startpunt, maar het verbergt vaak een meer sinister probleem: jitter. Jitter is simpelweg de variatie in je latentie in de loop van de tijd. Denk er eens over na—een stabiele verbinding met een voorspelbare 80ms vertraging is vaak veel beter voor realtime-apps dan eentje die gemiddeld 50ms is, maar wild fluctueert tussen 10ms en 200ms.
Jitter is de stille moordenaar van de gebruikerservaring voor alles wat realtime is, zoals VoIP-gesprekken, videovergaderingen of online gaming. Hoge jitter veroorzaakt schokkerig geluid, bevroren video en frustrerende vertragingen die een applicatie volledig gebroken laten aanvoelen, zelfs wanneer de gemiddelde latentie er op papier goed uitziet.
Jitter begrijpen betekent verder kijken dan het gemiddelde. Het is de onopgemerkte schurk omdat het onthult waarom gemiddelden alleen zo misleidend kunnen zijn. Gegevens van Pandora FMS tonen aan dat jitter boven de 30ms de pakketverliespercentages in gaming kan verhogen tot 15%—genoeg om een spel on speelbaar te maken. Het meten van de standaarddeviatie van je latentie-resultaten is de eerste stap om een getal op die instabiliteit te plakken.
Checklist voor Latentietestontwerp
Om dit allemaal samen te brengen, hier is een snelle checklist om je te begeleiden. Het volgen van deze stappen helpt ervoor te zorgen dat de gegevens die je verzamelt zowel nauwkeurig als echt nuttig zijn.
| Checklist Item | Waarom het Belangrijk is | Actiegerichte Tip |
|---|---|---|
| Definieer Duidelijke Doelen | Je kunt niet meten wat je niet definieert. Ben je een specifiek probleem aan het oplossen of een basislijn aan het vaststellen? | Schrijf je doel op voordat je begint. "Diagnoseer vertraging voor gebruikers in Zuidoost-Azië" is een beter doel dan "controleer latentie." |
| Kies Diverse Eindpunten | Een enkel pad vertegenwoordigt je wereldwijde gebruikerservaring niet. | Kies 3-5 locaties: één lokaal, één op een ander continent en een paar in je belangrijkste gebruikersmarkten. |
| Stel een Cadans Vast | Eenmalige tests missen tijdgebonden patronen zoals congestie tijdens piekuren. | Plan tests om automatisch elk uur gedurende een week uit te voeren om een volledige cyclus van netwerkgedrag vast te leggen. |
| Meet Jitter | Gemiddelden verbergen de onvoorspelbare prestaties die realtime-applicaties ruïneren. | Kijk niet alleen naar de gemiddelde RTT. Bereken de standaarddeviatie of gebruik een tool zoals mtr die min/max/gemiddelde latentie toont. |
| Gebruik de Juiste Tools | ping is goed voor een snelle controle, maar tools zoals mtr of iperf bieden diepere inzichten. |
Voor webprestaties, gebruik browserontwikkeltools. Voor ruwe netwerkpaden is mtr een geweldige keuze. |
| Documenteer Alles | Je zult de "waarom" achter je test over zes maanden vergeten. | Houd een eenvoudig logboek bij: datum, tijd, eindpunten, gebruikte tool en een korte opmerking over wat je hebt waargenomen. |
Door methodisch te zijn, ga je van het simpelweg meten van latentie naar het echt begrijpen ervan. Deze doordachte aanpak is wat een willekeurig getal scheidt van een betrouwbare prestatie-indicator.
De Cijfers Begrijpen (en Wat te Vermijden)
Oké, je hebt je tests uitgevoerd en hebt een stapel gegevens. Dit is waar het echte werk begint—het vertalen van die ruwe cijfers naar iets dat echt betekenisvol is. De gegevens vertellen je een verhaal over de gezondheid van je netwerk; je moet alleen leren hoe je het moet lezen.
Bijvoorbeeld, een plotselinge piek in de Round-Trip Time (RTT) op een traceroute is een klassieke aanwijzing. Als de latentie stijgt bij hop nummer drie en hoog blijft tot het einde, heb je waarschijnlijk je probleem gevonden: het is die derde router of de link er direct na. Maar wees voorzichtig. Als alleen die enkele hop hoge latentie vertoont en de uiteindelijke bestemming nog steeds snel is, kan het gewoon een router zijn die is geconfigureerd om het exacte soort verkeer dat je test gebruikt, te de-prioriteren. Het is een veelvoorkomende valse alarm die je in een doolhof kan sturen.
Jitter en Pakketverlies Decoderen
Voorbij de eenvoudige RTT kijken is waar je de meest kritische inzichten zult vinden. Hoge jitter, wat gewoon een chique woord is voor inconsistente latentie, kan veel disruptiever zijn dan latentie die consistent hoog is. Dit is vooral waar voor alles wat realtime is.
Als je resultaten een gemiddelde RTT van 40ms tonen, maar de minimum was 10ms en de maximum was 150ms, is je verbinding onbetrouwbaar. Die enorme variatie is precies wat vervelende haperingen in video-oproepen en frustrerende vertragingen in online games veroorzaakt.
Pakketverlies is een nog grotere rode vlag. Zelfs 1% pakketverlies kan TCP-gebaseerde applicaties volledig verlammen, waardoor ze voortdurend gegevens opnieuw moeten verzenden en alles tot stilstand komt. Wanneer je naar je testresultaten kijkt, moet elk echt verschil tussen verzonden en ontvangen pakketten onmiddellijk worden onderzocht.
Een van de grootste fouten die ik mensen zie maken, is aannemen dat een enkele test het hele verhaal vertelt. Netwerkcondities veranderen voortdurend. Een test die om 3 uur 's nachts wordt uitgevoerd, zal er compleet anders uitzien dan een om 15.00 uur tijdens de piekuren. De enige manier om een echte prestatiebasislijn te krijgen, is door consistente, herhaalde tests uit te voeren.
Om problemen voor te zijn, is het de moeite waard om te kijken naar speciale tools voor netwerkprestaties monitoring. Dit verschuift je aanpak van het wanhopig repareren van dingen wanneer ze kapot gaan naar proactief je netwerk gezond houden.
De Meest Voorkomende Meetfouten
Zelfs met de beste tools ter wereld kunnen een paar eenvoudige fouten je resultaten volledig nutteloos maken. Het vermijden van deze veelvoorkomende valkuilen is niet onderhandelbaar als je gegevens wilt die je echt kunt vertrouwen.
- Testen via Wi-Fi: Neem het serieus, doe het gewoon niet. Draadloze verbindingen zijn berucht onbetrouwbaar, gevoelig voor interferentie van alles, van magnetrons tot de router van je buurman. Voor serieuze latentie-tests, sluit aan met een Ethernet-kabel. Het is de enige manier om een stabiele, betrouwbare basislijn te krijgen.
- Vergeten VPN-overhead: VPN's zijn geweldig voor beveiliging, maar ze voegen een extra stop en encryptie toe aan de reis van je verkeer. Dit zal altijd de latentie verhogen. Als je probeert de trage verbinding van een gebruiker te diagnosticeren, moet een van je eerste vragen zijn: "Ben je op de VPN?" Testen met en zonder zal je precies laten zien hoeveel vertraging het toevoegt.
- Lokale Netwerkcongestie Negeren: Je testresultaten zullen vertekend zijn als iemand anders op je netwerk al het bandbreedte in beslag neemt. Als een collega 4K-video streamt of enorme bestanden downloadt terwijl jij aan het testen bent, zullen je latentiegetallen opgeblazen zijn, en zul je eindigen met het achtervolgen van een probleem dat niet bestaat.
Een andere subtiele maar kritische factor is de tool die je kiest. Zoals we hebben behandeld, meten verschillende hulpmiddelen latentie op verschillende manieren. Wees altijd consistent met de tools die je gebruikt voor vergelijking, en zorg ervoor dat je begrijpt wat elk van hen eigenlijk meet—of het nu een eenvoudige ICMP echo is of een complexe aanvraag op applicatieniveau. En onthoud, prestaties kunnen door veel lagen worden beïnvloed; bijvoorbeeld, als je je verdiept in webprestaties, kan onze gids over een Cookie Editor Chrome Extension laten zien hoe client-side elementen een rol spelen.
Door je resultaten te interpreteren met de juiste context en deze veelvoorkomende fouten te vermijden, ga je verder dan alleen het verzamelen van cijfers. Je begint te begrijpen waarom de prestaties van je netwerk zijn zoals ze zijn, en dat is de sleutel tot het bouwen van snellere, betrouwbaardere systemen.
Veelgestelde Vragen over Netwerk Latentie
Zelfs met de juiste tools lijken een paar veelvoorkomende vragen altijd op te duiken wanneer je begint te graven in netwerklatentie. Laten we enkele van de meest voorkomende die ik hoor doornemen om je te helpen je resultaten te begrijpen.
Wat is Eigenlijk een “Goed” Latentienummer?
Dit is de klassieke "het hangt ervan af" vraag, maar we kunnen zeker enkele solide benchmarks vaststellen. Een "goede" latentie is volledig relatief aan wat je probeert te bereiken.
- Casual Web Browsen: Voor de meesten van ons voelt alles onder 100ms RTT perfect aan. Pagina's laden snel, en je zult geen echte vertraging opmerken.
- Competitief Online Gaming: Dit is waar elke milliseconde telt. Serieuze gamers en high-frequency traders zoeken latentie ver onder 20ms. Het is het verschil tussen winnen en verliezen.
- Video-oproepen & VoIP: Hier is consistentie koning. Je hebt een stabiele latentie onder 150ms en lage jitter (minder dan 30ms) nodig om dat schokkerige, niet-synchrone gevoel te vermijden of, erger nog, verbroken oproepen.
Als vuistregel zouden de meeste netwerkprofessionals die ik ken alles onder 50ms als lage latentie classificeren. Van 50-150ms is gematigd, en zodra je boven de 150ms komt, zul je de vertraging beginnen te voelen op de meeste interactieve applicaties.
Waarom Stemmen Mijn Ping en Browser Snelheidstestresultaten Nooit Overeen?
Dit is een fantastische vraag en een super veelvoorkomend punt van verwarring. Het gebeurt omdat een command-line ping en een browser-gebaseerde snelheidstest fundamenteel verschillende tools zijn die verschillende dingen meten.
Om te beginnen, praten ze bijna zeker met verschillende servers. Wanneer je een ping naar een domein uitvoert, raak je een specifiek doel. Een web snelheidstest is daarentegen ontworpen om een geografisch dichtbijzijnde server vanuit zijn eigen netwerk te vinden om je het beste resultaat te geven.
De protocollen zijn ook volledig verschillend. Ping gebruikt een zeer licht protocol genaamd ICMP. De meeste browser tests draaien over TCP, wat een hele setup-procedure vereist (de "drie-weg handdruk") alleen al om een verbinding tot stand te brengen. Die initiële heen-en-weer voegt een beetje tijd toe voordat de echte test zelfs maar begint.
Ten slotte bevatten browser tests vaak meer dan alleen de pure netwerktijd. Hun "latentie" getal kan serververwerkingstijd of zelfs kleine vertragingen binnen je browser zelf omvatten, wat het uiteindelijke cijfer kan opblazen in vergelijking met een ruwe ICMP ping.
Hoe Kan Ik Mijn Netwerk Latentie Eigenlijk Verlagen?
Het verminderen van latentie draait allemaal om het opsporen en elimineren van knelpunten, of ze nu in uw kantoor of op het internet zijn.
De eerste plek om te kijken is uw directe omgeving. De meest effectieve verandering die u kunt maken, is overstappen van Wi-Fi naar een bekabelde Ethernet-verbinding. Het is een game-changer voor stabiliteit en snelheid. Als u Wi-Fi moet gebruiken, ga dan dichter bij uw router staan en maak gebruik van de 5GHz-band als dat mogelijk is—die is meestal minder druk.
Als we verder kijken dan uw lokale netwerk, kan soms een DNS-wissel helpen. Het gebruik van een snellere DNS-server kan milliseconden besparen op de initiële verbindingstijd wanneer u een website opzoekt.
Als u probeert de toegang tot een service die u beheert te verbeteren, is een Content Delivery Network (CDN) de oplossing. Het werkt door kopieën van uw inhoud fysiek dichter bij uw gebruikers te plaatsen. En als u een VPN gebruikt, probeer deze dan uit te schakelen. Die extra sprongetje en encryptielaag voegt bijna altijd latentie toe.
Ik heb gezien dat bedrijfs-VPN's tot wel 70 ms aan de rondreis tijd kunnen toevoegen. Het kan een geweldige verbinding omtoveren in een frustrerend trage. Test altijd met en zonder uw VPN om te zien welke prestatie-impact u daadwerkelijk ondervindt.
Wat is het werkelijke verschil tussen latentie en bandbreedte?
Dit goed begrijpen is fundamenteel voor het begrijpen van netwerkprestaties. Het is gemakkelijk om ze door elkaar te halen, maar ze meten twee heel verschillende dingen.
Hier is de analogie die ik altijd gebruik: beschouw het als een snelweg.
- Bandbreedte is hoeveel rijstroken de snelweg heeft. Meer rijstroken betekent dat er meer auto's (data) tegelijkertijd kunnen rijden.
- Latentie is de snelheidslimiet. Het bepaalt hoe snel een enkele auto (een datapakket) van A naar B kan komen.
U zou een enorme snelweg met tien rijstroken (enorme bandbreedte) kunnen hebben met een snelheidslimiet van 20 mph (hoge latentie). U zou uiteindelijk een hoop data kunnen verplaatsen, maar real-time dingen zoals een videogesprek zouden pijnlijk traag zijn. Aan de andere kant voelt een verbinding met zeer lage latentie ongelooflijk snel en responsief aan, zelfs als de bandbreedte niet enorm is. U heeft echt een goede balans van beide nodig voor een geweldige ervaring.
Klaar om prestatie testen een naadloos onderdeel van uw dagelijkse workflow te maken? De ShiftShift Extensions suite biedt een krachtige Speed Test, JSON formatter en tientallen andere ontwikkelaarstools direct in uw browser, toegankelijk met een enkele opdracht. Stop met het jongleren met tabbladen en begin slimmer te werken. Download ShiftShift Extensions gratis en geef uw productiviteit vandaag een boost.