Hvordan måle nettverkslatens: En praktisk guide for utviklere
Lær hvordan du måler nettverkslatens med denne omfattende guiden. Vi dekker essensielle verktøy som ping og traceroute samt nettleserbaserte testteknikker.

Anbefalte utvidelser
Vil du måle nettverkslatens? Du kan starte med enkle, innebygde kommandolinjeverktøy som ping og traceroute for å få en rask oversikt over Round-Trip Time (RTT). Eller du kan åpne utviklerverktøyene i nettleseren din for å se hvordan forsinkelser påvirker hva brukerne dine faktisk opplever.
Dessa metodene gir deg et raskt, nyttig øyeblikksbilde av hvor lang tid det tar for en datapakke å reise fra en kilde, nå en destinasjon, og gjøre turen tilbake.
Hvorfor Måling av Latens Er Uunnværlig
Før vi går inn på "hvordan", la oss snakke om "hvorfor". For utviklere og nettverksingeniører er latens ikke bare et tall på en skjerm; det er den usynlige hånden som former hele brukeropplevelsen. I dagens applikasjoner er millisekunder alt. Selv en liten forsinkelse kan være forskjellen mellom en tjeneste som føles umiddelbar og en som føles ødelagt.
Tenk på de virkelige konsekvensene:
- API Responsivitet: Et enkelt sakte API-anrop kan skape en dominoeffekt, som holder opp alt fra å laste en brukers profil til å behandle en kritisk betaling.
- Sanntidsdatastreams: For online spill, direktesendt video eller finanshandel, er lav og konsistent latens den absolutte grunnmuren. Uten det fungerer disse applikasjonene rett og slett ikke.
- Brukerretensjon: Det er en direkte linje som forbinder sakte lastende nettsteder og apper med høyere avvisningsrater og forlatte handlekurver. Dette påvirker bunnlinjen, hardt.
Skille Nøkkelkonsepter for Latens
For å måle nettverkslatens nøyaktig, må du vite hva du ser på. De to mest grunnleggende konseptene er Round-Trip Time (RTT) og enveis latens.
RTT er den totale tiden det tar for et signal å gå fra punkt A til punkt B og tilbake igjen. Det er den mest vanlige metrikken du vil se fordi den er enkel å måle—du trenger bare tilgang til den ene enden av forbindelsen.
Enveis latens, som navnet antyder, måler tiden det tar for data å reise i bare én retning. Dette er en mye vanskeligere måling å få riktig fordi det krever perfekt synkroniserte klokker på begge endepunkter. Imidlertid er det en mye mer presis indikator for asymmetriske forbindelser, der opplastings- og nedlastingsveiene oppfører seg veldig forskjellig.
Betydningen av alt dette blir krystallklar når du gjør seriøs lastytelsestesting, som er der teori møter virkelighet og flaskehalser blir avdekket.
For å sette noen tall på det, klassifiserer nettverksmonitoreringseksperter vanligvis latens slik:
- Lav latens: Under 50 millisekunder
- Moderat latens: 50-150 ms
- Høy latens: Over 150 ms
Fra min erfaring kan en rask test til en nærliggende server vise en helt akseptabel 20-40 ms. Men det tallet kan lett blåse opp til over 200 ms for trafikk som må krysse et hav, noe som kan være en game-changer for ytelsen til applikasjonen din.
For å forstå sjargongen du vil møte, her er en rask referanse.
Nøkkelkonsepter for Latens i Et Blikk
| Konsept | Hva Det Måler | Hvorfor Det Betyr Noe |
|---|---|---|
| Latens (Ping) | Tiden det tar for en enkelt datapakke å reise fra en kilde til en destinasjon og tilbake. Målt i millisekunder (ms). | Dette er den rå målingen av forsinkelse. Lav latens er avgjørende for sanntidsapplikasjoner som spill, VoIP og videokonferanser. |
| Round-Trip Time (RTT) | I hovedsak det samme som latens, dette er den totale varigheten for at et signal skal sendes pluss tiden for at en bekreftelse skal mottas. | RTT er den mest vanlige og praktiske måten å måle latens fra et enkelt punkt, noe som gjør det til den foretrukne metrikken for verktøy som ping. |
| Enveis Latens | Tiden det tar for en pakke å reise fra kilde til destinasjon i én retning. | Gir en mer detaljert oversikt, spesielt for asymmetriske nettverk der opplastings- og nedlastingsveiene har forskjellige latenser. |
| Jitter | Variasjonen i latens over tid. Det måler inkonsistensen i pakkeankomsttider. | Høy jitter er like ille som høy latens for streaming av media og online samtaler, og forårsaker hakking, buffering og glitches. |
| Båndbredde | Den maksimale mengden data som kan overføres over en nettverksforbindelse i en gitt tidsperiode. Målt i Mbps eller Gbps. | Ofte forvekslet med hastighet, båndbredde handler om kapasitet. Du kan ha høy båndbredde, men fortsatt lide av høy latens. |
Dessa konseptene er byggesteinene for å forstå ethvert nettverksytelsesproblem.
Dette er hvor det å ha tilgjengelige, integrerte verktøy blir så viktig. I stedet for å kjøre komplekse diagnostiske pakker, kan moderne nettleserutvidelser og utviklerverktøy gi deg innsiktene du trenger uten å forlate arbeidsflyten din. Det handler om å gjøre latensmåling til en enkel, rutinemessig del av å bygge og vedlikeholde flott programvare.
Få Hender i Det Med Kommandolinje Latensverktøy
For virkelig å få en følelse av ytelsen til nettverket ditt, må du åpne terminalen. Kommandolinjen er hvor du finner de grunnleggende verktøyene som gir deg rå, ufiltrert data om forbindelsen din. Det handler om å se hva som virkelig skjer med pakkene som beveger seg mellom deg og en destinasjon, og det er det essensielle første steget for enhver utvikler som er seriøs om å måle latens.
Det klassiske, foretrukne verktøyet er ping. Det er vakkert enkelt: det sender en liten datapakke (en ICMP ekkoforespørsel) til en server og venter bare på at den skal komme tilbake. Den enkle rundreisen er grunnlaget for å beregne Round-Trip Time (RTT) og gir deg en umiddelbar helsesjekk på en forbindelse.
Din Første Latenssjekk med Ping
Å kjøre en ping-test kunne ikke vært enklere. Start terminalen eller kommandoprompten, skriv ping, og følg det med domenet du vil teste.
Som standard vil ping fortsette for alltid på macOS og Linux, mens Windows sender bare fire pakker og stopper. For enhver reell analyse vil du kontrollere dette. Å sende ti eller tjue pakker gir deg et mye mer pålitelig bilde av stabiliteten til forbindelsen enn bare et par.
Når det er ferdig, får du et pent sammendrag med de avgjørende tallene:
- Pakker Sendt/Mottatt: Dette forteller deg om noen data ble tapt underveis. Selv en liten mengde pakkeforringelse er et stort rødt flagg for nettverksproblemer.
- Round-trip min/avg/max/mdev: Dette er dine kjerne latensstatistikker. Du får beste tilfelle tid (
min), gjennomsnittet (avg), og worst-case (max).mdev(gjennomsnittlig avvik) er ditt mål for jitter—hvor mye latensen varierer fra en pakke til den neste.
Vær oppmerksom på gapet mellom din minimum og maksimum RTT. Hvis det er bredt, er forbindelsen din ustabil, selv om gjennomsnittet ser greit ut. Denne jitteren kan være mye mer forstyrrende for sanntidsapper som videokonferanser eller spill enn en forbindelse som konsekvent er litt treg.
En vanlig feil er å bare kaste et blikk på gjennomsnittlig RTT. Et gjennomsnitt på 50ms kan virke greit, men hvis minimumet ditt er 20ms og maksimumet er 250ms, vil brukeropplevelsen føles hakkete og upålitelig. Se alltid på hele spekteret for å forstå jitter.
Følge Sporet med Traceroute og MTR
Så, hva gjør du når ping avslører høy latens eller pakkeforringelse? Din neste oppgave er å finne ut hvor problemet er. Det er det traceroute (eller tracert på Windows) er til. Det kartlegger hele stien pakkene dine tar, og viser deg hver eneste "hopp"—hver ruter—mellom maskinen din og den endelige destinasjonen.
Hver linje i traceroute-utdataene er et hopp, og det viser vanligvis tre separate latensmålinger til det punktet. Dette lar deg finne ut om en spesifikk ruter langs stien forårsaker en stor nedgang eller mister pakker.
Men traceroute er et engangsøyeblikksbilde. For en mer dynamisk, kontinuerlig oversikt, sverger de fleste nettverksproffene jeg kjenner til MTR (My Traceroute). MTR er som et superladet verktøy som kombinerer ping og traceroute. Det sender kontinuerlig pakker til hvert hopp på ruten, og gir deg en live, oppdatert oversikt over latens og pakkeforringelse på hvert eneste punkt. Dette gjør det utrolig effektivt til å fange intermitterende problemer som en enkelt traceroute sannsynligvis ville gått glipp av.
Hvorfor Valget av Verktøy Betyr Noe
Verktøyet du velger og hvordan du konfigurerer det kan drastisk endre resultatene dine. Dette er spesielt sant i ultra-hurtige, lav-latens miljøer som skydata sentre.
Det er faktisk ganske opplysende hvor forskjellige tallene kan være. I et detaljert eksperiment utført av Google Cloud, rapporterte en standard ping-test et gjennomsnittlig RTT på 146 mikrosekunder. Men når de brukte et annet verktøy som sender transaksjoner tilbake-til-bak uten pause, falt RTT til bare 66.59 mikrosekunder—mer enn dobbelt så raskt!
Dette er et perfekt eksempel på hvorfor ping noen ganger kan overvurdere latens. Det viser at det å forstå hvordan et verktøy fungerer er kritisk for å få målinger du kan stole på.
Finne Din Forbindelses Topp Hastighet med iperf
Latens er ikke alltid hele bildet. Noen ganger må du vite den maksimale mengden data forbindelsen din faktisk kan presse gjennom—dens båndbredde. For den jobben, er verktøyet du vil ha iperf.
Mens ping måler forsinkelse, handler iperf om gjennomstrømning. Det fungerer ved å sette opp en klient-server-forbindelse og deretter sende så mye data som mulig mellom dem i en bestemt tidsperiode.
For å bruke iperf, trenger du to maskiner:
- På én maskin kjører du
iperfi servermodus. Den vil bare sitte der og lytte etter en forbindelse. - På den andre maskinen kjører du
iperfi klientmodus, og peker den mot serverens adresse.
Klienten vil koble til og testen vil starte. Utdataene forteller deg den totale dataoverføringen og, viktigst av alt, bitraten (din båndbredde) i megabiter eller gigabiter per sekund. Det er den perfekte måten å stresse teste en nettverksforbindelse og finne ut hva den virkelig er i stand til.
Måling av Latens Fra en Brukers Perspektiv
Mens kommandolinjeverktøy gir deg et rått, ufiltrert blikk på nettverket ditt, er den eneste latensen som virkelig betyr noe for en webapplikasjon hva sluttbrukeren faktisk opplever. Dette er hvor vi skifter fokus fra terminalen til nettleseren selv. Hva som skjer inne i nettleseren forteller en mye rikere, mer relevant historie om ytelse.
Det handler aldri bare om en enkelt pakkes rundreise. Latensen en bruker føler er en kompleks cocktail av DNS-oppslag, TCP-håndtrykk, TLS-forhandlinger, serverbehandlingstid, og selvfølgelig, tiden det tar å faktisk gjengi innholdet på skjermen. Heldigvis kommer moderne nettlesere pakket med kraftige innebygde verktøy for å hjelpe oss med å dissekere hele denne prosessen.
Dykke Inn i Nettleserens Utviklerverktøy
Hver større nettleser—Chrome, Firefox, Edge, Safari—kommer utstyrt med en suite av utviklerverktøy. "Nettverk"-fanen i disse verktøyene er kommandosenteret ditt for å forstå hvordan nettstedet ditt lastes. Den legger alt ut i et fossefall-diagram, som er en visuell oppdeling av hver enkelt forespørsel nettleseren gjør for å gjengi en side.
Denne fossefallsvisningen er uvurderlig. Du kan se nøyaktig hvor lang tid hver ressurs tok å laste ned, fra det innledende HTML-dokumentet og CSS-stilarkene til bilder og API-anrop. Mer viktig, den bryter ned livssyklusen til hver forespørsel i distinkte faser:
- DNS-oppslag: Tiden det tar å løse et domenenavn til en IP-adresse.
- Innledende Forbindelse: Tiden brukt på å etablere en TCP-forbindelse med serveren.
- SSL/TLS Håndtrykk: Overheaden som kreves for å sette opp en sikker forbindelse.
- Tid til Første Byte (TTFB): Dette er en stor en. Det måler hvor lenge nettleseren ventet før den mottok den første byte av data fra serveren.
- Innholdsnedlasting: Tiden brukt på å faktisk laste ned ressursen selv.
En høy TTFB, for eksempel, er et klassisk tegn på en treg backend eller server-side behandlingsproblem—noe en enkel ping-test aldri ville avdekket. Ved å analysere dette fossefallet kan du raskt oppdage hvilke ressurser som blokkerer gjengivelse eller bare tar altfor lang tid å laste.
En viktig lærdom fra min erfaring er å ikke bare se på den totale lastetiden, men å lete etter de lengste stolpene i fossefallet. Et enkelt uoptimalisert bilde eller et tregt tredjeparts API kan holde hele siden som gissel, og skape en dårlig brukeropplevelse selv om resten av nettstedet er lynraskt.
Programmatisk Måling med Timing-APIer
For mer automatiserte og presise målinger kan du bruke nettleserens innebygde JavaScript-APIer. Navigation Timing API og Resource Timing API gir deg programmatisk tilgang til de samme detaljerte ytelsesdataene du ser i utviklerverktøyene. Dette er perfekt for å samle inn data for reell brukerovervåking (RUM) for å forstå hvordan nettstedet ditt presterer for faktiske besøkende over hele verden.
Du kan hente disse målingene med bare noen få linjer JavaScript, rett i nettleserkonsollen. For å få de kjerne ytelsestidene for hovedsideinnlastingen, for eksempel, kan du bruke performance.getEntriesByType('navigation'). Dette returnerer et objekt pakket med verdifulle tidsstempler.
Fra de dataene kan du beregne viktige målinger:
- DNS-oppslagstid:
domainLookupEnd - domainLookupStart - TCP-håndtrykkstid:
connectEnd - connectStart - Tid til Første Byte (TTFB):
responseStart - requestStart - Total Sideinnlastningstid:
loadEventEnd - startTime
Denne tilnærmingen lar deg bygge tilpassede dashbord eller sende ytelsesdata til analyseverktøyene dine, noe som gir deg en kontinuerlig oversikt over applikasjonens ytelse i den virkelige verden. I webutvikling er optimalisering av bilder en vanlig måte å forbedre disse målingene på; for de som er interessert, har vi en nyttig guide om hvordan du velger det beste bildeformatet for nettstedet ditt.
Strømlinjeforme kontroller med integrerte verktøy
Å hoppe mellom terminalen, nettleserens utviklerverktøy og tilpassede skript kan bli kjedelig raskt. Dette er hvor integrerte nettleserutvidelser virkelig kan jevne ut arbeidsflyten din ved å forene disse kontrollene. For eksempel inkluderer ShiftShift Extensions-pakken et innebygd Speed Test-verktøy som du kan åpne umiddelbart fra hvilken som helst fane.
Dette gir deg en rask, personvernsfokusert måte å måle nedlastingshastigheten, opplastingshastigheten og latensen til tilkoblingen din uten å måtte navigere til et eget nettsted eller åpne en terminal. Fordi det er en del av et større verktøysett, kan du kjøre en hastighetskontroll, formatere et JSON-svar og sjekke en informasjonskapsel, alt fra den samme enhetlige kommandopaletten. Denne typen integrasjon gjør ytelseskontroller til en naturlig, friksjonsfri del av den daglige utviklingsprosessen.
Hvordan designe en latensetest som faktisk gir deg informasjon
Alle kan sende en ping-kommando og få et tall tilbake. Men hvis du vil ha data du faktisk kan stole på—data som hjelper deg med å ta reelle beslutninger—må du være mer bevisst. En enkelt, isolert måling er bare et øyeblikksbilde i tid. For virkelig å forstå nettverkets oppførsel, må du tenke som en detektiv, vurdere hvor du tester fra, hvor ofte du tester, og hva du egentlig ser etter.
En godt utformet test omdanner rå tall til handlingsrettede innsikter. En dårlig utformet test? Den er bare støy.
Diagrammet nedenfor bryter ned alle de små forsinkelsene som legger seg opp til hva en bruker føler når de laster inn en nettside. Det er en god påminnelse om at en enkel nettverks-ping ikke engang begynner å fortelle hele historien.
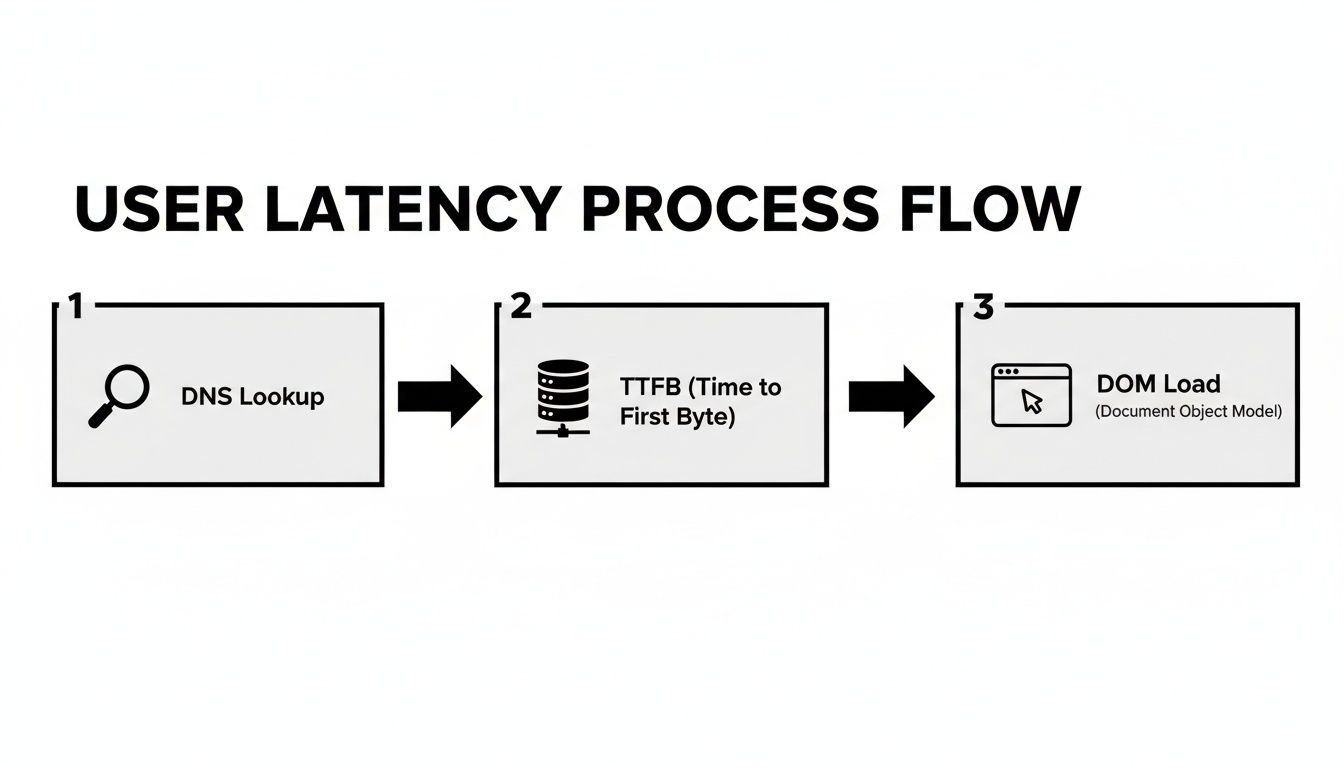
Som du kan se, fra det første DNS-oppslaget til den endelige gjengivelsen, bidrar flere trinn til den totale ventetiden.
Velge testendepunkter
Den første regelen for pålitelig testing er at geografi betyr noe. En test fra kontoret ditt i New York til en server nede i New Jersey forteller deg absolutt ingenting om opplevelsen for kundene dine i Tokyo. For å få et realistisk bilde, må du teste fra forskjellige steder som faktisk speiler brukerbasen din.
Listen din over endepunkter bør dekke noen nøkkelområder:
- Dine største brukerhuber: Hvor bor de fleste av kundene dine? Test derfra.
- Kontinentale stier: Se hva som skjer når data må krysse et hav. Test mellom Europa og Nord-Amerika, eller Asia og USA, for å forstå langdistanseytelse.
- Dine skyregioner: Hvis du er på AWS, Azure eller GCP, test tilkobling til og mellom de spesifikke datasenterregionene du er avhengig av.
Å spre testene dine på denne måten skaper et mye mer nøyaktig kart over global ytelse. Det hjelper deg å oppdage regionspesifikke flaskehalser som du ellers ville gått glipp av. Dette er også et godt øyeblikk for å dobbeltsjekke domenet ditt; du kan finne nyttige tips om hvordan du sjekker domenetilgjengelighet og relaterte konfigurasjoner for å sikre at alt er i orden.
Finne riktig testrytme
Nettverksforhold er konstant i endring. De endrer seg gjennom dagen, uken, og til og med minuttet. En test som kjøres kl. 03.00 på en tirsdag kan se fantastisk ut, men det resultatet er ubrukelig hvis topptrafikken din treffer kl. 14.00 på en fredag når alle er på nett.
For å få en sann baseline, må du teste konsekvent over tid. Variér:
- Kjør tester i løpet av peak forretningstimer.
- Planlegg noen for nattevakt vedlikeholdsvinduer.
- Ikke glem helgene, når trafikkmønstre kan være helt forskjellige.
Ved å ta prøver av data gjentatte ganger, kan du jevne ut de tilfeldige toppene og bunnene. Slik oppdager du gjentakende problemer, som at nettverket blir overbelastet hver ukedag ettermiddag rett etter lunsj.
Ikke glem jitter
Gjennomsnittlig latens er et solid utgangspunkt, men det skjuler ofte et mer sinister problem: jitter. Jitter er rett og slett variasjonen i latensen din over tid. Tenk på det—en stabil tilkobling med en forutsigbar 80ms forsinkelse er ofte mye bedre for sanntidsapper enn en som i gjennomsnitt har 50ms men svinger vilt mellom 10ms og 200ms.
Jitter er den stille morderen av brukeropplevelsen for alt som er sanntid, som VoIP-samtaler, videokonferanser eller online spill. Høy jitter er det som forårsaker hakkete lyd, frosne videoer og frustrerende forsinkelsestopper som får en applikasjon til å føles helt ødelagt, selv når den gjennomsnittlige latensen ser bra ut på papiret.
Å forstå jitter betyr å se utover gjennomsnittet. Det er den usungne skurken fordi det avslører hvorfor gjennomsnitt alene kan være så misvisende. For eksempel viser data fra Pandora FMS at jitter over 30ms kan øke pakkeforringelsesratene i spill til 15%—nok til å gjøre et spill uspillbart. Å måle standardavviket av latensresultatene dine er det første steget for å sette et tall på den ustabiliteten.
Latensetest design sjekkliste
For å samle alt dette, her er en rask sjekkliste for å veilede deg. Å følge disse trinnene vil hjelpe deg med å sikre at dataene du samler inn er både nøyaktige og virkelig nyttige.
| Sjekklisteelement | Hvorfor det er viktig | Handlingsrettet tips |
|---|---|---|
| Definer klare mål | Du kan ikke måle det du ikke definerer. Feilsøker du et spesifikt problem eller etablerer en baseline? | Skriv ned målet ditt før du begynner. "Diagnostisere forsinkelse for brukere i Sørøst-Asia" er et bedre mål enn "sjekke latens." |
| Velg forskjellige endepunkter | En enkelt sti representerer ikke den globale brukeropplevelsen din. | Velg 3-5 steder: ett lokalt, ett på et annet kontinent, og noen i dine nøkkelbrukermarkeder. |
| Etabler en rytme | Engangstester går glipp av tidsbaserte mønstre som overbelastning i peak-timer. | Planlegg tester til å kjøre automatisk hver time i en uke for å fange opp en full syklus av nettverksoppførsel. |
| Mål jitter | Gjennomsnitt skjuler den uregelmessige ytelsen som ødelegger sanntidsapplikasjoner. | Ikke bare se på gjennomsnittlig RTT. Beregn standardavviket eller bruk et verktøy som mtr som viser min/maks/gjennomsnittlig latens. |
| Bruk de riktige verktøyene | ping er bra for en rask sjekk, men verktøy som mtr eller iperf gir dypere innsikter. |
For webytelse, bruk nettleserens utviklerverktøy. For rå nettverksstier, er mtr et flott valg. |
| Dokumenter alt | Du vil glemme "hvorfor" bak testen din seks måneder fra nå. | Hold en enkel logg: dato, tid, endepunkter, verktøy brukt, og en kort notat om hva du observerte. |
Ved å være metodisk, går du fra å bare måle latens til å virkelig forstå den. Denne gjennomtenkte tilnærmingen er det som skiller et tilfeldig tall fra en pålitelig ytelsesindikator.
Gi mening til tallene (og hva du bør unngå)
Greit, du har kjørt testene dine og har en haug med data. Dette er hvor det virkelige arbeidet begynner—å oversette de rå tallene til noe som faktisk betyr noe. Dataene forteller deg en historie om nettverkets helse; du må bare lære å lese den.
For eksempel, en plutselig topp i Round-Trip Time (RTT) på en traceroute er et klassisk ledetråd. Hvis latensen hopper ved hopp nummer tre og forblir høy hele veien til slutten, har du sannsynligvis funnet problemet ditt: det er den tredje ruteren eller lenken rett etter den. Men vær forsiktig. Hvis bare det enkelt hoppet viser høy latens og den endelige destinasjonen fortsatt er rask, kan det bare være en ruter konfigurert til å nedprioritere den eksakte typen trafikk testen din bruker. Det er et vanlig falskt alarm som kan sende deg ned i en kaninhull.
Avkode jitter og pakkeforringelse
Å se forbi enkel RTT er hvor du finner de mest kritiske innsiktene. Høy jitter, som bare er et fancy ord for inkonsekvent latens, kan være langt mer forstyrrende enn latens som er konsekvent høy. Dette er spesielt sant for alt som er sanntid.
Hvis resultatene dine viser en gjennomsnittlig RTT på 40ms, men minimum var 10ms og maksimum var 150ms, er tilkoblingen din ustabil. Den massive variasjonen er akkurat det som forårsaker irriterende hakking i videosamtaler og rasende forsinkelsestopper i online spill.
Pakkeforringelse er et enda større rødt flagg. Selv 1% pakkeforringelse kan absolutt lamme TCP-baserte applikasjoner, og tvinge dem til stadig å sende data på nytt og bremse alt til en krabbe. Når du ser på testresultatene dine, må enhver reell forskjell mellom sendte pakker og mottatte pakker undersøkes umiddelbart.
En av de største feilene jeg ser folk gjøre, er å anta at en enkelt test forteller hele historien. Nettverksforhold endrer seg konstant. En test som kjøres kl. 03.00 vil se helt annerledes ut enn en kl. 15.00 i peak forretningstimer. Den eneste måten å få en sann ytelsesbaseline på er gjennom konsekvent, gjentatt testing.
For å komme foran problemer, er det verdt å se på dedikerte verktøy for nettverksytelsesovervåking. Dette skifter tilnærmingen din fra å panisk fikse ting når de går i stykker, til proaktivt å holde nettverket ditt sunt.
De vanligste målefeilene
Selv med de beste verktøyene i verden, kan noen få enkle feil gjøre resultatene dine helt ubrukelige. Å unngå disse vanlige fallgruvene er ikke forhandlingsbart hvis du vil ha data du faktisk kan stole på.
- Testing over Wi-Fi: Seriøst, bare ikke. Trådløse tilkoblinger er notorisk ustabile, utsatt for forstyrrelser fra alt fra mikrobølgeovner til naboens ruter. For seriøs latens testing, koble til med en Ethernet-kabel. Det er den eneste måten å få en stabil, pålitelig baseline.
- Glemme VPN-overhead: VPN-er er flotte for sikkerhet, men de legger til et ekstra stopp og kryptering til trafikkens reise. Dette vil alltid øke latensen. Hvis du prøver å diagnostisere en brukers langsomme tilkobling, bør et av de første spørsmålene dine være, "Er du på VPN?" Testing med og uten det vil vise deg nøyaktig hvor mye forsinkelse det legger til.
- Ignorere lokal nettverksbelastning: Testresultatene dine vil være skjeve hvis noen andre på nettverket ditt tar all båndbredden. Hvis en kollega strømmer 4K-video eller laster ned massive filer mens du tester, vil latensnumrene dine bli oppblåst, og du vil ende opp med å forfølge et problem som ikke eksisterer.
En annen subtil, men kritisk faktor er verktøyet du velger. Som vi har dekket, måler forskjellige verktøy latens på forskjellige måter. Vær alltid konsekvent med verktøyene du bruker for sammenligning, og sørg for at du forstår hva hver enkelt faktisk måler—enten det er en enkel ICMP-echo eller en kompleks, applikasjonsnivå forespørsel. Og husk, ytelse kan påvirkes av mange lag; for eksempel, hvis du graver inn i webytelse, kan vår guide om en Cookie Editor Chrome Extension vise hvordan klient-side elementer spiller en rolle.
Ved å tolke resultatene dine med riktig kontekst og unngå disse vanlige feilene, vil du gå utover bare å samle tall. Du vil begynne å forstå hvorfor bak nettverkets ytelse, og det er nøkkelen til å bygge raskere, mer pålitelige systemer.
Vanlige spørsmål om nettverkslatens
Selv med de riktige verktøyene, ser det ut til at noen få vanlige spørsmål alltid dukker opp når du begynner å grave i nettverkslatens. La oss gå gjennom noen av de mest hyppige spørsmålene jeg hører for å hjelpe deg med å forstå resultatene dine.
Hva er egentlig et "bra" latenstall?
Dette er det klassiske "det avhenger" spørsmålet, men vi kan definitivt sette noen solide referanser. En "bra" latens er helt relativ til hva du prøver å oppnå.
- Uformell nettlesing: For de fleste av oss vil alt under 100ms RTT føles helt greit. Sider lastes raskt, og du vil ikke merke noen reell forsinkelse.
- Konkurransedyktig online spilling: Dette er hvor hver millisekund teller. Seriøse spillere og høyfrekvente tradere ser etter latens godt under 20ms. Det er forskjellen mellom å vinne og tape.
- Videokall & VoIP: Her er konsistens konge. Du trenger en stabil latens under 150ms og lav jitter (mindre enn 30ms) for å unngå den hakkete, usynkroniserte følelsen eller, verre, tapte samtaler.
Som en tommelfingerregel ville de fleste nettverksproffene jeg kjenner klassifisere alt under 50ms som lav latens. Fra 50-150ms er moderat, og når du kryper over 150ms, vil du begynne å føle draget på de fleste interaktive applikasjoner.
Hvorfor samsvarer aldri ping- og nettleserhastighetstestresultatene mine?
Dette er et fantastisk spørsmål og et super vanlig forvirringspunkt. Det skjer fordi en kommandolinje ping og en nettleserbasert hastighetstest er fundamentalt forskjellige verktøy som måler forskjellige ting.
For det første snakker de nesten helt sikkert med forskjellige servere. Når du pinger et domene, treffer du et spesifikt mål. En webhastighetstest, derimot, er designet for å finne en geografisk nær server fra sitt eget nettverk for å gi deg det beste resultatet.
Protokollene er også helt forskjellige. Ping bruker en veldig lett protokoll kalt ICMP. De fleste nettlesertester kjører over TCP, som krever en hel oppsettprosess (den "treveis håndtrykk") bare for å etablere en tilkobling. Den innledende frem og tilbake legger til litt tid før den virkelige testen i det hele tatt begynner.
Til slutt inkluderer nettlesertester ofte mer enn bare ren nettverks reisetid. Deres "latens" tall kan inkludere serverbehandlingstid eller til og med små forsinkelser innen nettleseren din selv, noe som kan oppblåse det endelige tallet sammenlignet med en rå ICMP-ping.
Hvordan kan jeg faktisk senke nettverkslatensen min?
Å redusere latens handler om å finne og eliminere flaskehalser, enten de er på kontoret ditt eller over internett.
Det første stedet å se er ditt umiddelbare miljø. Den mest effektive endringen du kan gjøre er å bytte fra Wi-Fi til en kablet Ethernet-tilkobling. Det er en game-changer for stabilitet og hastighet. Hvis du må bruke Wi-Fi, kom nærmere ruteren din og hopp på 5GHz-båndet hvis du kan – det er vanligvis mindre overfylt.
Ser man utover ditt lokale nettverk, kan noen ganger et DNS-bytt hjelpe. Å bruke en raskere DNS-server kan kutte millisekunder fra den innledende tilkoblingstiden når du ser opp et nettsted.
Hvis du prøver å forbedre tilgangen til en tjeneste du kontrollerer, er et Content Delivery Network (CDN) svaret. Det fungerer ved å plassere kopier av innholdet ditt fysisk nærmere brukerne dine. Og hvis du bruker en VPN, prøv å slå den av. Det ekstra hoppet og krypteringslaget legger nesten alltid til latens.
Jeg har sett bedrifts-VPN-er legge til så mye som 70ms til en rundturstid. Det kan gjøre en flott tilkobling til en frustrerende treg en. Test alltid med og uten VPN-en din for å se hvilken type ytelsestap du faktisk opplever.
Hva er den virkelige forskjellen mellom latens og båndbredde?
Å få dette riktig er grunnleggende for å forstå nettverksytelse. Det er lett å blande dem sammen, men de måler to veldig forskjellige ting.
Her er analogien jeg alltid bruker: tenk på det som en motorvei.
- Båndbredde er hvor mange felt motorveien har. Flere felt betyr at flere biler (data) kan reise samtidig.
- Latens er fartsgrensen. Den dikterer hvor raskt en enkelt bil (et datapakke) kan komme fra A til B.
Du kan ha en massiv, ti-felts motorvei (enorm båndbredde) med en fartsgrense på 20 mph (høy latens). Du kan flytte en mengde data til slutt, men sanntidsting som en videosamtale ville vært smertefullt treg. På den annen side føles en tilkobling med veldig lav latens utrolig responsiv og kvikk, selv om båndbredden ikke er enorm. Du trenger virkelig en god balanse mellom begge for en flott opplevelse.
Klar til å gjøre ytelsestesting til en sømløs del av din daglige arbeidsflyt? ShiftShift Extensions-pakken gir deg en kraftig hastighetstest, JSON-formatør og dusinvis av andre utviklerverktøy rett i nettleseren din, tilgjengelig med en enkelt kommando. Slutt å jonglere med faner og begynn å jobbe smartere. Last ned ShiftShift Extensions gratis og superlad produktiviteten din i dag.