Cum să măsori latența rețelei: Ghid practic pentru dezvoltatori
Învățați cum să măsurați latența rețelei cu acest ghid cuprinzător. Acoperim instrumente esențiale precum ping și traceroute, precum și tehnici de testare bazate pe browser.

Extensii Recomandate
Vrei să măsori latența rețelei? Poți începe cu instrumente simple, integrate în linia de comandă, cum ar fi ping și traceroute, pentru a obține o citire rapidă a Timpului de Răspuns (RTT). Sau poți deschide instrumentele de dezvoltare ale browserului tău pentru a vedea cum întârzierile afectează ceea ce experimentează efectiv utilizatorii tăi.
Aceste metode îți oferă o imagine rapidă și utilă despre cât timp durează ca un pachet de date să călătorească de la o sursă, să ajungă la o destinație și să facă drumul înapoi.
De ce Măsurarea Latenței Este Non-Negociabilă
Înainte să intrăm în „cum”, să discutăm despre „de ce”. Pentru dezvoltatori și ingineri de rețea, latența nu este doar un număr pe un ecran; este mâna invizibilă care modelează întreaga experiență a utilizatorului. În aplicațiile de astăzi, milisecundele sunt totul. Chiar și o mică întârziere poate face diferența între un serviciu care se simte instantaneu și unul care se simte defect.
Gândește-te la consecințele din lumea reală:
- Reactivitatea API-ului: Un singur apel API lent poate crea un efect de domino, întârziind totul, de la încărcarea profilului unui utilizator până la procesarea unei plăți critice.
- Fluxuri de Date în Timp Real: Pentru jocurile online, video live sau tranzacționarea financiară, latența scăzută și constantă este fundația absolută. Fără ea, aceste aplicații pur și simplu nu funcționează.
- Retenția Utilizatorilor: Există o legătură directă între site-urile și aplicațiile care se încarcă lent și ratele mai mari de abandon și coșurile de cumpărături abandonate. Aceste lucruri afectează serios profitul.
Distingerea Conceptelor Cheie de Latență
Pentru a măsura cu acuratețe latența rețelei, trebuie să știi la ce te uiți. Cele două concepte fundamentale sunt Timpul de Răspuns (RTT) și latența pe o singură direcție.
RTT este timpul total necesar pentru ca un semnal să meargă de la punctul A la punctul B și înapoi. Este cea mai comună metrică pe care o vei vedea deoarece este simplu de măsurat—ai nevoie doar de acces la un capăt al conexiunii.
Latența pe o singură direcție, așa cum sugerează numele, măsoară timpul necesar pentru ca datele să călătorească într-o singură direcție. Aceasta este o măsurătoare mult mai complicată de obținut corect deoarece necesită ceasuri perfect sincronizate la ambele capete. Totuși, este un indicator mult mai precis pentru conexiunile asimetrice, unde căile de încărcare și descărcare se comportă foarte diferit.
Importanța tuturor acestor lucruri devine clară atunci când efectuezi teste serioase de performanță la încărcare, unde teoria se întâlnește cu realitatea și blocajele sunt expuse.
Ca să punem niște cifre pe asta, experții în monitorizarea rețelei clasifică de obicei latența astfel:
- Latență scăzută: Sub 50 milisecunde
- Latență moderată: 50-150 ms
- Latență mare: Peste 150 ms
Din experiența mea, un test rapid către un server din apropiere ar putea arăta o latență perfect acceptabilă de 20-40 ms. Dar acel număr poate crește ușor la peste 200 ms pentru traficul care trebuie să traverseze un ocean, ceea ce poate schimba radical performanța aplicației tale.
Pentru a înțelege jargonul pe care îl vei întâlni, iată o referință rapidă.
Conceptelor Cheie de Latență pe Scurt
| Concept | Ce Măsoară | De ce Este Important |
|---|---|---|
| Latență (Ping) | Timpul necesar pentru ca un singur pachet de date să călătorească de la o sursă la o destinație și înapoi. Măsurat în milisecunde (ms). | Aceasta este măsura brută a întârzierii. Latența scăzută este crucială pentru aplicațiile în timp real, cum ar fi jocurile, VoIP și conferințele video. |
| Timpul de Răspuns (RTT) | Practic același lucru cu latența, aceasta este durata totală pentru ca un semnal să fie trimis plus timpul necesar pentru a primi o confirmare. | RTT este cea mai comună și practică modalitate de a măsura latența dintr-un singur punct, făcându-l metrică de bază pentru instrumente precum ping. |
| Latența pe O Singură Direcție | Timpul necesar pentru ca un pachet să călătorească de la sursă la destinație într-o singură direcție. | Oferă o vedere mai detaliată, mai ales pentru rețele asimetrice unde căile de încărcare și descărcare au latențe diferite. |
| Jitter | Variatia latenței în timp. Măsoară inconsistența timpilor de sosire a pachetelor. | Jitterul ridicat este la fel de rău ca latența mare pentru streaming media și apeluri online, cauzând întreruperi, buffering și erori. |
| Bandwidth | Cantitatea maximă de date care poate fi transmisă printr-o conexiune de rețea într-o anumită perioadă de timp. Măsurat în Mbps sau Gbps. | Adesea confundat cu viteza, bandwidth-ul se referă la capacitate. Poți avea un bandwidth mare, dar să suferi în continuare de latență mare. |
Aceste concepte sunt blocurile de bază pentru înțelegerea oricărei probleme de performanță a rețelei.
Aici devine atât de important să ai instrumente accesibile și integrate. În loc să rulezi suite de diagnosticare complexe, extensiile moderne de browser și instrumentele de dezvoltare îți pot oferi informațiile de care ai nevoie fără a părăsi fluxul de lucru. Este vorba despre a face măsurarea latenței o parte ușoară și de rutină din construirea și întreținerea unui software excelent.
Intrând în Detalii cu Instrumentele de Latență din Linia de Comandă
Pentru a simți cu adevărat performanța rețelei tale, trebuie să deschizi terminalul. Linia de comandă este locul unde vei găsi instrumentele fundamentale care îți oferă date brute, nefiltrate despre conexiunea ta. Este vorba despre a vedea ce se întâmplă cu adevărat cu pachetele care se mișcă între tine și o destinație, și este primul pas esențial pentru orice dezvoltator serios în măsurarea latenței.
Utilitarul clasic, de bază este ping. Este frumos de simplu: trimite un pachet mic de date (o cerere ICMP echo) către un server și așteaptă să se întoarcă. Acea simplă călătorie dus-întors este baza pentru calcularea Timpului de Răspuns (RTT) și îți oferă un control rapid asupra stării unei conexiuni.
Primul Tău Control al Latenței cu Ping
Executarea unui test ping nu ar putea fi mai simplă. Deschide terminalul sau promptul de comandă, tastează ping și urmează-l cu domeniul pe care vrei să-l testezi.
Implicit, ping va continua să ruleze la nesfârșit pe macOS și Linux, în timp ce Windows trimite doar patru pachete și se oprește. Pentru orice analiză reală, vei dori să controlezi acest lucru. Trimiterea a zece sau douăzeci de pachete îți oferă o imagine mult mai fiabilă asupra stabilității conexiunii decât doar câteva.
Odată ce s-a terminat, vei obține un rezumat ordonat cu cifrele esențiale:
- Pachete Transmise/Recepționate: Acest lucru îți spune dacă au fost pierdute date pe parcurs. Chiar și o mică pierdere de pachete este un semn major de alarmă pentru problemele de rețea.
- Round-trip min/avg/max/mdev: Acestea sunt statisticile tale de bază privind latența. Obții timpul cel mai bun (
min), media (avg) și cel mai rău caz (max).mdev(devierea medie) este măsura ta de jitter—cât de mult variază latența de la un pachet la altul.
Acordă o atenție deosebită diferenței dintre RTT-ul tău minim și maxim. Dacă este mare, conexiunea ta este instabilă, chiar dacă media arată bine. Acest jitter poate fi mult mai disruptiv pentru aplicațiile în timp real, cum ar fi apelurile video sau jocurile, decât o conexiune care este constant puțin lentă.
O greșeală comună este să te uiți doar la RTT-ul mediu. O medie de 50ms ar putea părea acceptabilă, dar dacă minimul tău este 20ms și maximul este 250ms, experiența utilizatorului va părea fragmentată și nesigură. Întotdeauna privește întreaga gamă pentru a înțelege jitterul.
Urmărind Drumul cu Traceroute și MTR
Așadar, ce faci când ping dezvăluie latență mare sau pierdere de pachete? Următoarea ta sarcină este să afli unde este problema. Aici intervine traceroute (sau tracert pe Windows). Acesta mapează întreaga cale pe care o urmează pachetele tale, arătându-ți fiecare „hop”—fiecare router—între mașina ta și destinația finală.
Fiecare linie din ieșirea traceroute este un hop, și de obicei arată trei măsurători separate ale latenței până la acel punct. Acest lucru îți permite să identifici dacă un anumit router de-a lungul căii cauzează o încetinire majoră sau pierde pachete.
Dar traceroute este o fotografie unică. Pentru o privire mai dinamică și continuă, cei mai mulți profesioniști în rețea pe care îi cunosc jură pe MTR (My Traceroute). MTR este ca un instrument superîncărcat care combină ping și traceroute. Trimite constant pachete către fiecare hop de pe traseu, oferindu-ți o vedere live, actualizată a latenței și pierderii de pachete la fiecare punct. Acest lucru îl face extrem de eficient în captarea problemelor intermitente pe care un singur traceroute le-ar putea rata.
De ce Alegerea Instrumentului Tău Contează
Instrumentul pe care îl alegi și modul în care îl configurezi pot schimba drastic rezultatele tale. Acest lucru este valabil mai ales în medii ultra-rapide, cu latență scăzută, cum ar fi centrele de date cloud.
Este de fapt destul de surprinzător cât de diferite pot fi cifrele. Într-un experiment detaliat realizat de Google Cloud, un test standard ping a raportat un RTT mediu de 146 microsecunde. Dar când au folosit un alt instrument care trimite tranzacții una după alta fără o pauză, RTT-ul a scăzut la doar 66.59 microsecunde—de mai mult de două ori mai rapid!
Aceasta este un exemplu perfect de ce ping poate uneori supraestima latența. Arată că înțelegerea modului în care funcționează un instrument este esențială pentru a obține măsurători de care poți avea încredere.
Găsind Viteza Maximă a Conexiunii Tale cu iperf
Latența nu este întotdeauna întreaga imagine. Uneori trebuie să știi cantitatea maximă de date pe care conexiunea ta o poate transmite efectiv—bandwidth-ul său. Pentru această sarcină, instrumentul pe care îl vrei este iperf.
În timp ce ping măsoară întârzierea, iperf se concentrează pe throughput. Funcționează prin configurarea unei conexiuni client-server și apoi trimite cât mai multe date între ele pentru o perioadă de timp stabilită.
Pentru a folosi iperf, vei avea nevoie de două mașini:
- Pe o mașină, rulezi
iperfîn mod server. Aceasta va sta acolo și va asculta pentru o conexiune. - Pe cealaltă mașină, rulezi
iperfîn mod client, indicându-i adresa serverului.
Clientul se va conecta și testul va începe. Ieșirea îți spune totalul de date transferate și, cel mai important, bitrate-ul (bandwidth-ul tău) în megabiți sau gigabiți pe secundă. Este modul perfect de a testa o legătură de rețea și de a descoperi ce poate face cu adevărat.
Măsurarea Latenței din Perspectiva Utilizatorului
În timp ce instrumentele din linia de comandă îți oferă o privire brută, nefiltrată asupra rețelei tale, singura latență care contează cu adevărat pentru o aplicație web este ceea ce experimentează efectiv utilizatorul final. Aici ne mutăm atenția de la terminal la browserul în sine. Ce se întâmplă în interiorul browserului spune o poveste mult mai bogată și mai relevantă despre performanță.
Nu este niciodată vorba doar despre o singură călătorie a unui pachet. Latența pe care un utilizator o simte este un cocktail complex de căutări DNS, handshake-uri TCP, negocieri TLS, timp de procesare pe server și, desigur, timpul necesar pentru a reda efectiv conținutul pe ecran. Din fericire, browserele moderne vin echipate cu instrumente puternice integrate pentru a ne ajuta să disecăm întregul proces.
Explorând Instrumentele de Dezvoltare ale Browserului
Fiecare browser major—Chrome, Firefox, Edge, Safari—vine echipat cu o suită de instrumente pentru dezvoltatori. Tab-ul „Rețea” din aceste instrumente este centrul tău de comandă pentru a înțelege cum se încarcă site-ul tău. Acesta prezintă totul într-un grafic de tip cascade, care este o descompunere vizuală a fiecărei cereri pe care browserul o face pentru a reda o pagină.
Această vedere în cascade este inestimabilă. Poți vedea exact cât timp a durat fiecare resursă pentru a fi descărcată, de la documentul HTML inițial și fișierele CSS până la imagini și apeluri API. Mai important, descompune ciclul de viață al fiecărei cereri în faze distincte:
- Căutare DNS: Timpul necesar pentru a rezolva un nume de domeniu într-o adresă IP.
- Conexiune Inițială: Timpul petrecut pentru a stabili o conexiune TCP cu serverul.
- Handshake SSL/TLS: Supraponderarea necesară pentru a stabili o conexiune securizată.
- Timp până la Primul Byte (TTFB): Acesta este un aspect major. Măsoară cât timp a așteptat browserul înainte de a primi primul byte de date de la server.
- Descărcarea Conținutului: Timpul petrecut efectiv pentru a descărca resursa în sine.
Un TTFB ridicat, de exemplu, este un semn clasic al unei probleme lente de backend sau de procesare pe server—ceva ce un simplu test ping nu ar descoperi niciodată. Prin analizarea acestei cascade, poți identifica rapid care resurse blochează redarea sau durează prea mult pentru a se încărca.
O concluzie cheie din experiența mea este să nu te uiți doar la timpul total de încărcare, ci să cauți cele mai lungi bare din cascada. O singură imagine neoptimizată sau un API terț lent poate ține întreaga pagină ostatică, creând o experiență slabă pentru utilizator, chiar dacă restul site-ului este extrem de rapid.
Măsurători Programatice cu API-urile de Timp
Pentru măsurători mai automate și precise, poți accesa API-urile JavaScript integrate ale browserului. API-ul de Timp de Navigare și API-ul de Timp al Resurselor îți oferă acces programatic la aceleași date detaliate de performanță pe care le vezi în instrumentele de dezvoltare. Acest lucru este perfect pentru colectarea datelor de monitorizare a utilizatorilor reali (RUM) pentru a înțelege cum performează site-ul tău pentru vizitatorii reali din întreaga lume.
Poti obține aceste metrici cu doar câteva linii de JavaScript, chiar în consola browserului. De exemplu, pentru a obține timpii de performanță esențiali pentru încărcarea principală a paginii, poți folosi performance.getEntriesByType('navigation'). Acesta returnează un obiect plin de timpi valoroși.
Din acele date, poți calcula metrici vitale:
- Timpul de Căutare DNS:
domainLookupEnd - domainLookupStart - Timpul de Handshake TCP:
connectEnd - connectStart - Timp până la Primul Byte (TTFB):
responseStart - requestStart - Timpul Total de Încărcare a Paginii:
loadEventEnd - startTime
Această abordare vă permite să construiți tablouri de bord personalizate sau să trimiteți date de performanță către instrumentele dvs. de analiză, oferindu-vă un puls continuu asupra performanței reale a aplicației dvs. În dezvoltarea web, optimizarea imaginilor este o modalitate comună de a îmbunătăți aceste metrici; pentru cei interesați, avem un ghid util despre alegerea celui mai bun format de imagine pentru site-ul dvs..
Optimizarea verificărilor cu instrumente integrate
Saltul între terminal, instrumentele de dezvoltare ale browserului și scripturile personalizate poate deveni rapid obositor. Aici este locul unde extensiile integrate ale browserului pot netezi cu adevărat fluxul de lucru prin unificarea acestor verificări. De exemplu, suita ShiftShift Extensions include un instrument Speed Test încorporat pe care îl puteți deschide instantaneu din orice tab.
Aceasta vă oferă o modalitate rapidă, axată pe confidențialitate, de a măsura viteza de descărcare, viteza de încărcare și latența conexiunii dvs. fără a fi nevoie să navigați către un site web separat sau să deschideți un terminal. Deoarece face parte dintr-un set mai mare de instrumente, puteți rula un test de viteză, formata un răspuns JSON și verifica un cookie toate din aceeași paletă de comenzi unificată. Acest tip de integrare face ca verificările de performanță să fie o parte naturală, fără fricțiuni, a muncii zilnice de dezvoltare.
Cum să proiectați un test de latență care să vă ofere informații utile
Oricine poate lansa un comandă ping și poate obține un număr înapoi. Dar dacă doriți date în care să aveți încredere—date care să vă ajute să luați decizii reale—trebuie să fiți mai deliberat. O singură măsurare izolată este doar o fotografie într-un moment dat. Pentru a înțelege cu adevărat comportamentul rețelei dvs., trebuie să gândiți ca un detectiv, luând în considerare de unde testați, cât de des testați și ce căutați cu adevărat.
Un test bine conceput transformă numerele brute în informații acționabile. Unul prost conceput? Este doar zgomot.
Diagrama de mai jos descompune toate micile întârzieri care se adună la ceea ce un utilizator simte atunci când încarcă o pagină web. Este o reamintire excelentă că un simplu ping de rețea nu începe nici măcar să spună întreaga poveste.
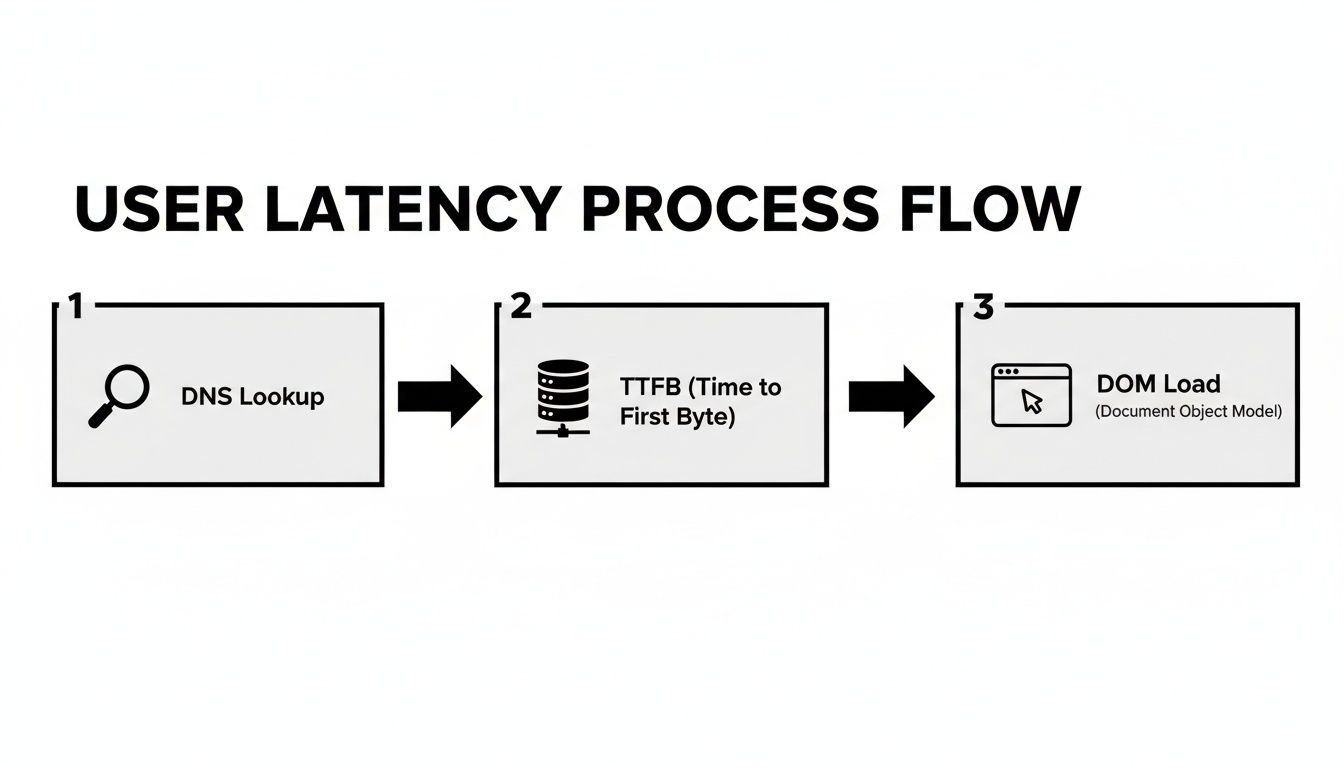
Așa cum puteți vedea, de la căutarea inițială DNS până la redarea finală, mai mulți pași contribuie la timpul total de așteptare.
Alegerea punctelor finale de testare
Prima regulă a testării fiabile este că geografia contează. Un test din biroul dvs. din New York către un server din apropiere în New Jersey nu vă spune absolut nimic despre experiența clienților dvs. din Tokyo. Pentru a obține o imagine realistă, trebuie să testați din locații diverse care reflectă cu adevărat baza dvs. de utilizatori.
Lista dvs. de puncte finale ar trebui să acopere câteva domenii cheie:
- Hub-urile dvs. cele mai mari de utilizatori: Unde locuiesc cei mai mulți dintre clienții dvs.? Testați de acolo.
- Cărți transcontinentale: Vedeți ce se întâmplă când datele trebuie să traverseze un ocean. Testați între Europa și America de Nord sau Asia și SUA pentru a înțelege performanța pe distanțe lungi.
- Regiunile dvs. de cloud: Dacă sunteți pe AWS, Azure sau GCP, testați conectivitatea către și între regiunile specifice ale centrului de date pe care vă bazați.
Împrăștierea testelor în acest mod creează o hartă mult mai precisă a performanței globale. Vă ajută să identificați blocajele specifice regiunii pe care altfel le-ați putea rata complet. Acesta este, de asemenea, un moment bun pentru a verifica configurația domeniului dvs.; puteți găsi sfaturi utile despre cum să verificați disponibilitatea domeniului și configurațiile conexe pentru a vă asigura că totul este în ordine.
Găsirea ritmului de testare potrivit
Condițiile rețelei sunt în continuă schimbare. Ele se schimbă pe parcursul zilei, săptămânii și chiar minutei. Un test efectuat la 3 AM într-o marți ar putea arăta fantastic, dar acel rezultat este inutil dacă traficul de vârf apare la 2 PM într-o vineri când toată lumea este online.
Pentru a obține o bază de referință adevărată, trebuie să testați constant în timp. Varietatea este cheia:
- Rulați teste în timpul orelor de vârf ale afacerii.
- Programați unele pentru feronerie de întreținere pe timp de noapte.
- Nu uitați de weekenduri, când modelele de trafic pot fi complet diferite.
Prin eșantionarea datelor în mod repetat, puteți netezi vârfurile și scăderile aleatorii. Așa identificați problemele recurente, cum ar fi congestia rețelei în fiecare după-amiază de lucru imediat după prânz.
Nu uitați de jitter
Latența medie este un punct de plecare solid, dar adesea ascunde o problemă mai sinistră: jitter. Jitter este pur și simplu variabilitatea latenței dvs. în timp. Gândiți-vă la asta—o conexiune stabilă cu o întârziere previzibilă de 80ms este adesea mult mai bună pentru aplicațiile în timp real decât una care are o medie de 50ms dar oscilează brusc între 10ms și 200ms.
Jitter este ucigașul tăcut al experienței utilizatorului pentru orice aplicație în timp real, cum ar fi apelurile VoIP, conferințele video sau jocurile online. Jitterul ridicat este ceea ce cauzează audio întrerupt, video înghețat și vârfuri frustrante de întârziere care fac ca o aplicație să pară complet defectă, chiar și atunci când latența medie arată bine pe hârtie.
Înțelegerea jitter-ului înseamnă a privi dincolo de medie. Este răufăcătorul neglijat deoarece dezvăluie de ce mediile singure pot fi atât de înșelătoare. De exemplu, datele de la Pandora FMS arată că jitterul peste 30ms poate crește ratele de pierdere a pachetelor în jocuri la 15%—suficient pentru a face un joc injucabil. Măsurarea deviației standard a rezultatelor dvs. de latență este primul pas pentru a pune un număr pe acea instabilitate.
Lista de verificare pentru proiectarea testului de latență
Pentru a aduna toate acestea, iată o listă rapidă de verificare pentru a vă ghida. Urmarea acestor pași va ajuta la asigurarea că datele pe care le colectați sunt atât precise, cât și cu adevărat utile.
| Element de verificare | De ce este important | Sfat acționabil |
|---|---|---|
| Definiți obiective clare | Nu puteți măsura ceea ce nu definiți. Încercați să rezolvați o problemă specifică sau să stabiliți o bază de referință? | Scrieți-vă obiectivul înainte de a începe. "Diagnosticați întârzierea pentru utilizatorii din Asia de Sud-Est" este un obiectiv mai bun decât "verificați latența." |
| Selectați puncte finale diverse | O singură cale nu reprezintă experiența globală a utilizatorului dvs. | Alegeți 3-5 locații: una locală, una pe un alt continent și câteva în piețele dvs. cheie de utilizatori. |
| Stabiliți un ritm | Testele unice ratează modelele bazate pe timp, cum ar fi congestia în orele de vârf. | Programați teste să ruleze automat la fiecare oră timp de o săptămână pentru a captura un ciclu complet de comportament al rețelei. |
| Măsurați jitter | Mediile ascund performanța eratică care distruge aplicațiile în timp real. | Nu vă uitați doar la RTT-ul mediu. Calculați deviația standard sau folosiți un instrument precum mtr care arată latența minimă/maximă/medie. |
| Folosiți instrumentele potrivite | ping este bun pentru o verificare rapidă, dar instrumente precum mtr sau iperf oferă informații mai profunde. |
Pentru performanța web, folosiți instrumentele de dezvoltare ale browserului. Pentru căile de rețea brute, mtr este o alegere excelentă. |
| Documentați totul | Veți uita "de ce" din spatele testului dvs. în șase luni. | Păstrați un jurnal simplu: dată, oră, puncte finale, instrument utilizat și o notă scurtă despre ceea ce ați observat. |
Fiind metodic, treceți de la simpla măsurare a latenței la înțelegerea ei cu adevărat. Această abordare atentă este ceea ce separă un număr aleatoriu de un indicator de performanță fiabil.
Înțelegerea numerelor (și ce să evitați)
Bine, ați rulat testele și aveți o grămadă de date. Aici începe adevărata muncă—traducerea acelor numere brute în ceva care înseamnă cu adevărat ceva. Datele vă spun o poveste despre sănătatea rețelei dvs.; trebuie doar să învățați cum să o citiți.
De exemplu, o creștere bruscă a timpului de răspuns (RTT) pe un traceroute este un indiciu clasic. Dacă latența sare la hop-ul numărul trei și rămâne ridicată până la final, probabil ați găsit problema: este acel al treilea router sau legătura imediat după el. Dar fiți atenți. Dacă doar acel hop singular arată latență ridicată și destinația finală este încă rapidă, ar putea fi doar un router configurat să deprioritizeze exact tipul de trafic pe care îl folosește testul dvs. Este o alarmă falsă comună care vă poate trimite pe o cale greșită.
Decodificarea jitter-ului și a pierderii de pachete
Privind dincolo de RTT-ul simplu este locul unde veți găsi cele mai critice informații. Jitterul ridicat, care este doar un cuvânt fancy pentru latență inconsistentă, poate fi mult mai disruptiv decât latența care este constant ridicată. Acest lucru este valabil mai ales pentru orice aplicație în timp real.
Dacă rezultatele dvs. arată un RTT mediu de 40ms, dar minimul a fost 10ms și maximul a fost 150ms, conexiunea dvs. este instabilă. Acea variabilitate masivă este exact ceea ce cauzează întreruperi enervante în apelurile video și vârfuri de întârziere care provoacă furie în jocurile online.
Pierderea de pachete este un semnal și mai mare de alarmă. Chiar și 1% pierdere de pachete poate paraliza complet aplicațiile bazate pe TCP, forțându-le să retrimită constant date și încetinind totul până la o viteză de melc. Când vă uitați la rezultatele testului, orice diferență reală între pachetele trimise și cele primite trebuie investigată imediat.
Una dintre cele mai mari greșeli pe care le văd oamenii făcând este să presupună că un singur test spune întreaga poveste. Condițiile rețelei se schimbă constant. Un test efectuat la 3 AM va arăta complet diferit de unul la 3 PM în timpul orelor de vârf. Singura modalitate de a obține o bază de referință adevărată a performanței este prin testare consistentă și repetată.
Pentru a anticipa problemele, merită să căutați instrumente dedicate pentru monitorizarea performanței rețelei. Aceasta vă schimbă abordarea de la a repara frenetic lucrurile când se strică la a menține proactiv rețeaua sănătoasă.
Cele mai comune greșeli de măsurare
Chiar și cu cele mai bune instrumente din lume, câteva greșeli simple pot face ca rezultatele dvs. să fie complet inutile. Evitarea acestor capcane comune este esențială dacă doriți date în care să aveți cu adevărat încredere.
- Testarea prin Wi-Fi: Serios, pur și simplu nu o faceți. Conexiunile wireless sunt notoriu capricioase, predispuse la interferențe de la tot felul de surse, de la cuptoare cu microunde la routerul vecinului. Pentru orice testare serioasă a latenței, conectați-vă cu un cablu Ethernet. Este singura modalitate de a obține o bază de referință stabilă și fiabilă.
- Uitați de suprasarcina VPN: VPN-urile sunt excelente pentru securitate, dar adaugă o oprire suplimentară și criptare călătoriei traficului dvs. Aceasta va crește întotdeauna latența. Dacă încercați să diagnosticați o conexiune lentă a unui utilizator, una dintre primele întrebări ar trebui să fie: "Ești pe VPN?" Testarea cu și fără acesta vă va arăta exact cât de mult întârziere adaugă.
- Ignorarea congestiei rețelei locale: Rezultatele testului dvs. vor fi distorsionate dacă cineva altcineva de pe rețeaua dvs. folosește toată lățimea de bandă. Dacă un coleg transmite video 4K sau descarcă fișiere masive în timp ce testați, numerele dvs. de latență vor fi umflate și veți ajunge să urmăriți o problemă care nu există.
Un alt factor subtil, dar critic, este instrumentul pe care îl alegeți. Așa cum am acoperit, diferite utilitare măsoară latența în moduri diferite. Fiți întotdeauna consecvent cu instrumentele pe care le folosiți pentru comparație și asigurați-vă că înțelegeți ce măsoară fiecare—fie că este un simplu echo ICMP sau o cerere complexă la nivel de aplicație. Și amintiți-vă, performanța poate fi afectată de multe straturi; de exemplu, dacă explorați performanța web, ghidul nostru despre Cookie Editor Chrome Extension poate arăta cum elementele de client joacă un rol.
Prin interpretarea rezultatelor dvs. în contextul corect și evitarea acestor greșeli comune, veți trece dincolo de simpla colectare a numerelor. Veți începe să înțelegeți de ce performanța rețelei dvs. este așa cum este, iar aceasta este cheia pentru construirea unor sisteme mai rapide și mai fiabile.
Întrebări frecvente despre latența rețelei
Chiar și cu instrumentele potrivite, câteva întrebări comune par să apară întotdeauna atunci când începeți să explorați latența rețelei. Să trecem în revistă câteva dintre cele mai frecvente întrebări pe care le aud pentru a vă ajuta să înțelegeți rezultatele.
Ce număr de latență este de fapt „bun”?
Aceasta este întrebarea clasică „depinde”, dar putem stabili cu siguranță câteva repere solide. O latență „bună” este complet relativă la ceea ce încercați să realizați.
- Navigare web casuală: Pentru majoritatea dintre noi, orice sub 100ms RTT se va simți perfect. Pagini se încarcă rapid și nu veți observa nicio întârziere reală.
- Jocuri online competitive: Aici fiecare milisecundă contează. Gamerii serioși și traderii de înaltă frecvență caută latențe mult sub 20ms. Este diferența dintre a câștiga și a pierde.
- Apeluri video & VoIP: Aici, consistența este cheia. Aveți nevoie de o latență stabilă sub 150ms și jitter scăzut (sub 30ms) pentru a evita acea senzație de întrerupere sau, mai rău, apeluri pierdute.
Ca regulă generală, cei mai mulți profesioniști din rețea pe care îi cunosc ar clasifica orice sub 50ms ca latență scăzută. De la 50-150ms este moderată, iar odată ce depășiți 150ms, veți începe să simțiți o întârziere în majoritatea aplicațiilor interactive.
De ce rezultatele mele de ping și testul de viteză din browser nu se potrivesc niciodată?
Aceasta este o întrebare fantastică și un punct de confuzie foarte comun. Se întâmplă deoarece un ping din linia de comandă și un test de viteză bazat pe browser sunt instrumente fundamental diferite care măsoară lucruri diferite.
Pentru început, aproape cu siguranță comunică cu servere diferite. Când ping un domeniu, loviți un țintă specifică. Un test de viteză web, pe de altă parte, este conceput pentru a găsi un server geografic apropiat din propria sa rețea pentru a vă oferi cel mai bun rezultat posibil.
Protocolele sunt, de asemenea, complet diferite. Ping folosește un protocol foarte ușor numit ICMP. Cele mai multe teste din browser rulează pe TCP, care necesită un întreg proces de configurare („handshake-ul în trei pași”) doar pentru a stabili o conexiune. Acea interacțiune inițială adaugă puțin timp înainte ca testul real să înceapă.
În cele din urmă, testele din browser adesea includ mai mult decât doar timpul de călătorie al rețelei. Numărul lor de „latență” ar putea include timpul de procesare al serverului sau chiar întârzieri mici în cadrul browserului dvs. în sine, ceea ce poate umfla cifra finală comparativ cu un ping ICMP brut.
Cum pot să îmi reduc efectiv latența rețelei?
Reducerea latenței constă în identificarea și eliminarea blocajelor, fie că acestea se află în biroul tău sau pe internet.
Primul loc unde trebuie să te uiți este mediul tău imediat. Cea mai eficientă schimbare pe care o poți face este să treci de la Wi-Fi la o conexiune Ethernet prin cablu. Este un factor decisiv pentru stabilitate și viteză. Dacă trebuie să folosești Wi-Fi, apropie-te de routerul tău și conectează-te la banda de 5GHz, dacă poți—de obicei este mai puțin aglomerată.
Privind dincolo de rețeaua ta locală, uneori un schimb de DNS poate ajuta. Utilizarea unui server DNS mai rapid poate reduce timpul de conectare inițial cu câteva milisecunde atunci când cauți un site web.
Dacă încerci să îmbunătățești accesul la un serviciu pe care îl controlezi, o rețea de livrare a conținutului (CDN) este soluția. Aceasta funcționează prin plasarea copiilor conținutului tău fizic mai aproape de utilizatorii tăi. Și dacă folosești un VPN, încearcă să-l dezactivezi. Acea hop suplimentară și stratul de criptare adaugă aproape întotdeauna latență.
Am văzut VPN-uri corporative care adaugă până la 70ms la timpul de întoarcere. Poate transforma o conexiune excelentă într-una frustrant de lentă. Testează întotdeauna cu și fără VPN-ul tău pentru a vedea ce fel de impact asupra performanței ai, de fapt.
Care este adevărata diferență între latență și lățime de bandă?
Înțelegerea corectă a acestui aspect este fundamentală pentru a înțelege performanța rețelei. Este ușor să le confunzi, dar ele măsoară două lucruri foarte diferite.
Iată analogia pe care o folosesc întotdeauna: gândește-te la ea ca la o autostradă.
- Lățimea de bandă este câte benzi are autostrada. Mai multe benzi înseamnă că mai multe mașini (date) pot circula în același timp.
- Latența este limita de viteză. Aceasta dictează cât de repede poate ajunge o singură mașină (un pachet de date) de la A la B.
Poti avea o autostradă masivă, cu zece benzi (lățime de bandă mare) și o limită de viteză de 20 mph (latență mare). Ai putea muta o tonă de date în cele din urmă, dar lucruri în timp real, cum ar fi un apel video, ar fi dureros de lente. Pe de altă parte, o conexiune cu latență foarte mică se simte incredibil de rapidă și receptivă, chiar dacă lățimea sa de bandă nu este enormă. Ai nevoie cu adevărat de un bun echilibru între ambele pentru o experiență excelentă.
Pregătit să faci testarea performanței o parte integrantă a fluxului tău de lucru zilnic? Suita ShiftShift Extensions oferă un test de viteză puternic, un formatter JSON și zeci de alte instrumente pentru dezvoltatori direct în browserul tău, accesibile cu un singur comandă. Oprește-te din jonglatul cu tab-uri și începe să lucrezi mai inteligent. Descarcă ShiftShift Extensions gratuit și îmbunătățește-ți productivitatea astăzi.