Hur man mäter nätverkslatens: En praktisk guide för utvecklare
Lär dig hur du mäter nätverkslatens med denna omfattande guide. Vi täcker viktiga verktyg som ping och traceroute samt webbläsarbaserade testtekniker.

Rekommenderade tillägg
Vill du mäta nätverkslatens? Du kan börja med enkla, inbyggda kommandoradsverktyg som ping och traceroute för att få en snabb översikt över Round-Trip Time (RTT). Eller så kan du öppna din webbläsares utvecklarverktyg för att se hur fördröjningar påverkar vad dina användare faktiskt upplever.
Dessa metoder ger dig en snabb, användbar översikt över hur lång tid det tar för ett datapaket att resa från en källa, nå en destination och göra resan tillbaka.
Varför Mätning av Latens är Icke-Förhandlingsbar
Innan vi går in på "hur", låt oss prata om "varför". För utvecklare och nätverksingenjörer är latens inte bara en siffra på en skärm; det är den osynliga handen som formar hela användarupplevelsen. I dagens applikationer är millisekunder allt. Även en liten fördröjning kan vara skillnaden mellan en tjänst som känns omedelbar och en som känns trasig.
Tänk på de verkliga konsekvenserna:
- API Responsivitet: Ett enda långsamt API-anrop kan skapa en dominoeffekt, som fördröjer allt från att ladda en användarprofil till att behandla en kritisk betalning.
- Real-Tids Datastreams: För onlinespel, livevideo eller finansiell handel är låg och konsekvent latens den absoluta grunden. Utan det fungerar dessa applikationer helt enkelt inte.
- Användarretention: Det finns en direkt koppling mellan långsamt laddande webbplatser och appar och högre avvisningsfrekvenser samt övergivna kundvagnar. Detta påverkar resultatet, hårt.
Att Åtskilja Nyckelkoncept för Latens
För att mäta nätverkslatens noggrant måste du veta vad du tittar på. De två mest grundläggande koncepten är Round-Trip Time (RTT) och envägs latens.
RTT är den totala tiden det tar för en signal att gå från punkt A till punkt B och tillbaka igen. Det är den vanligaste metrik du kommer att se eftersom den är enkel att mäta—du behöver bara tillgång till ena änden av anslutningen.
Envägs latens, som namnet antyder, mäter den tid det tar för data att resa i endast en riktning. Detta är en mycket svårare mätning att få rätt eftersom det kräver perfekt synkroniserade klockor vid båda ändpunkterna. Men det är en mycket mer exakt indikator för asymmetriska anslutningar, där dina uppladdnings- och nedladdningsvägar beter sig mycket olika.
Betydelsen av allt detta blir kristallklar när du gör seriös lastprestandatestning, där teori möter verklighet och flaskhalsar avslöjas.
För att sätta några siffror på det, klassificerar nätverksövervakningsexperter vanligtvis latens på följande sätt:
- Låg latens: Under 50 millisekunder
- Moderat latens: 50-150 ms
- Hög latens: Över 150 ms
Utifrån min erfarenhet kan ett snabbt test till en närliggande server visa en helt acceptabel 20-40 ms. Men det numret kan lätt svälla till över 200 ms för trafik som måste korsa ett hav, vilket kan vara en avgörande faktor för din applikations prestanda.
För att förstå jargongen du kommer att stöta på, här är en snabb referens.
Nyckelkoncept för Latens i Sammanfattning
| Koncept | Vad Det Mäter | Varför Det Är Viktigt |
|---|---|---|
| Latens (Ping) | Tiden det tar för ett enda datapaket att resa från en källa till en destination och tillbaka. Mätt i millisekunder (ms). | Detta är det råa måttet på fördröjning. Låg latens är avgörande för realtidsapplikationer som spel, VoIP och videokonferenser. |
| Round-Trip Time (RTT) | I stort sett samma som latens, detta är den totala varaktigheten för att en signal ska skickas plus tiden för att en bekräftelse ska tas emot. | RTT är det vanligaste och praktiska sättet att mäta latens från en enda punkt, vilket gör det till den föredragna metrik för verktyg som ping. |
| Envägs Latens | Tiden det tar för ett paket att resa från källa till destination i en enda riktning. | Ger en mer detaljerad vy, särskilt för asymmetriska nätverk där uppladdnings- och nedladdningsvägar har olika latenser. |
| Jitter | Variation i latens över tid. Det mäter inkonsekvensen i paketens ankomsttider. | Hög jitter är lika dåligt som hög latens för strömmande media och onlinetelefoner, vilket orsakar hackande, buffring och glitchar. |
| Bandbredd | Den maximala mängden data som kan överföras över en nätverksanslutning under en viss tidsperiod. Mätt i Mbps eller Gbps. | Ofta förväxlat med hastighet, bandbredd handlar om kapacitet. Du kan ha hög bandbredd men ändå drabbas av hög latens. |
Dessa koncept är byggstenarna för att förstå eventuella nätverksprestandaproblem.
Det är här tillgången till integrerade verktyg blir så viktig. Istället för att köra komplexa diagnostiska sviter kan moderna webbläsartillägg och utvecklarverktyg ge dig de insikter du behöver utan att någonsin lämna ditt arbetsflöde. Det handlar om att göra latensmätning till en enkel, rutinmässig del av att bygga och underhålla bra mjukvara.
Att Få Händerna Smutsiga med Kommandoradsverktyg för Latens
För att verkligen få en känsla för ditt nätverks prestanda måste du öppna terminalen. Kommandoraden är där du hittar de grundläggande verktygen som ger dig rå, ofiltrerad data om din anslutning. Det handlar om att se vad som verkligen händer med paketen som rör sig mellan dig och en destination, och det är det avgörande första steget för varje utvecklare som är seriös med att mäta latens.
Det klassiska, självklara verktyget är ping. Det är vackert enkelt: det skickar ett litet datapaket (en ICMP-eko-förfrågan) till en server och väntar bara på att det ska komma tillbaka. Denna enkla rundtur är grunden för att beräkna Round-Trip Time (RTT) och ger dig en omedelbar hälsokontroll av en anslutning.
Din Första Latenskontroll med Ping
Att köra ett ping-test kan inte bli enklare. Starta din terminal eller kommandotolk, skriv ping, och följ det med domänen du vill testa.
Som standard kommer ping att fortsätta för alltid på macOS och Linux, medan Windows skickar bara fyra paket och stoppar. För någon verklig analys vill du kontrollera detta. Att skicka tio eller tjugo paket ger dig en mycket mer pålitlig bild av anslutningens stabilitet än bara ett par.
När det är klart får du en snygg sammanfattning med de avgörande siffrorna:
- Överförda/Mottagna Paket: Detta berättar om någon data gick förlorad längs vägen. Även en liten mängd paketförlust är en stor varningssignal för nätverksproblem.
- Round-trip min/medel/max/mdev: Dessa är dina kärnlatensstatistik. Du får bästa möjliga tid (
min), medelvärdet (avg), och värsta fallet (max).mdev(medelavvikelse) är ditt mått på jitter—hur mycket latensen varierar från ett paket till nästa.
Var noga med att uppmärksamma skillnaden mellan din minimi- och maximala RTT. Om den är bred är din anslutning instabil, även om medelvärdet ser okej ut. Denna jitter kan vara mycket mer störande för realtidsappar som videosamtal eller spel än en anslutning som konsekvent är lite långsam.
Ett vanligt misstag är att bara kasta ett öga på medel-RTT. Ett medelvärde på 50ms kan verka okej, men om din minimum är 20ms och din maximum är 250ms, kommer användarupplevelsen att kännas hackig och opålitlig. Titta alltid på hela spannet för att förstå jitter.
Följa Spåret med Traceroute och MTR
Så, vad gör du när ping avslöjar hög latens eller paketförlust? Ditt nästa jobb är att ta reda på var problemet ligger. Det är vad traceroute (eller tracert på Windows) är till för. Det kartlägger hela vägen dina paket tar, och visar varje enskild "hop"—varje router—mellan din maskin och den slutliga destinationen.
Varje rad i traceroute-utdata är en hop, och den visar vanligtvis tre separata latensmätningar till den punkten. Detta låter dig pinpointa om en specifik router längs vägen orsakar en stor fördröjning eller tappar paket.
Men traceroute är en engångsöversikt. För en mer dynamisk, kontinuerlig vy svär de flesta nätverksproffs jag känner vid MTR (My Traceroute). MTR är som ett superladdat verktyg som kombinerar ping och traceroute. Det skickar ständigt paket till varje hop på vägen, vilket ger dig en live, uppdaterad vy av latens och paketförlust vid varje enskild punkt. Detta gör det otroligt effektivt för att fånga intermittenta problem som en enda traceroute sannolikt skulle missa.
Varför Ditt Val av Verktyg Är Viktigt
Det verktyg du väljer och hur du konfigurerar det kan drastiskt förändra dina resultat. Detta gäller särskilt i ultrahurtiga, låglatensmiljöer som molndatahallar.
Det är faktiskt ganska ögonöppnande hur olika siffrorna kan vara. I ett detaljerat experiment som genomfördes av Google Cloud rapporterade ett standard ping-test ett genomsnittligt RTT på 146 mikrosekunder. Men när de använde ett annat verktyg som skickar transaktioner utan paus, sjönk RTT till bara 66.59 mikrosekunder—mer än dubbelt så snabbt!
Detta är ett perfekt exempel på varför ping ibland kan överskatta latens. Det visar att förstå hur ett verktyg fungerar är avgörande för att få mätningar du kan lita på.
Hitta Din Anslutnings Topp Hastighet med iperf
Latens är inte alltid hela bilden. Ibland behöver du veta den maximala mängden data som din anslutning faktiskt kan skicka igenom—dess bandbredd. För det jobbet är verktyget du vill ha iperf.
Medan ping mäter fördröjning, handlar iperf om genomströmning. Det fungerar genom att sätta upp en klient-server-anslutning och sedan skicka så mycket data som möjligt mellan dem under en viss tidsperiod.
För att använda iperf behöver du två maskiner:
- På en maskin kör du
iperfi serverläge. Den kommer bara att sitta där och lyssna efter en anslutning. - På den andra maskinen kör du
iperfi klientläge, och pekar den mot serverns adress.
Klienten kommer att ansluta och testet kommer att starta. Utdata berättar för dig den totala data som överförts och, viktigast av allt, bitrate (din bandbredd) i megabit eller gigabit per sekund. Det är det perfekta sättet att stressa ett nätverkslänk och ta reda på vad det verkligen klarar av.
Mäta Latens från en Användares Perspektiv
Medan kommandoradsverktyg ger dig en rå, ofiltrerad vy av ditt nätverk, är den enda latens som verkligen spelar roll för en webbapplikation vad slutanvändaren faktiskt upplever. Det är här vi skiftar vårt fokus från terminalen till webbläsaren själv. Vad som händer inuti webbläsaren berättar en mycket rikare, mer relevant historia om prestanda.
Det handlar aldrig bara om en enda pakets rundtur. Den latens en användare känner är en komplex cocktail av DNS-uppslag, TCP-handshakes, TLS-förhandlingar, serverbehandlingstid och självklart, den tid det tar att faktiskt rendera innehållet på skärmen. Tack och lov kommer moderna webbläsare packade med kraftfulla inbyggda verktyg för att hjälpa oss att dissekera hela denna process.
Dyk In i Webbläsarens Utvecklarverktyg
Varje större webbläsare—Chrome, Firefox, Edge, Safari—kommer utrustad med en uppsättning utvecklarverktyg. Fliken "Nätverk" inom dessa verktyg är ditt kommandocenter för att förstå hur din webbplats laddas. Den lägger allt i en vattenfallsdiagram, vilket är en visuell nedbrytning av varje enskild begäran som webbläsaren gör för att rendera en sida.
Denna vattenfallsvy är ovärderlig. Du kan se exakt hur lång tid varje tillgång tog att ladda ner, från det initiala HTML-dokumentet och CSS-stilmallar till bilder och API-anrop. Viktigare är att den bryter ner livscykeln för varje begäran i distinkta faser:
- DNS-uppslag: Tiden det tar att översätta ett domännamn till en IP-adress.
- Initial Anslutning: Tiden som spenderas på att etablera en TCP-anslutning med servern.
- SSL/TLS Handshake: Den overhead som krävs för att sätta upp en säker anslutning.
- Tid till Första Byte (TTFB): Detta är en stor grej. Det mäter hur länge webbläsaren väntade innan den fick det första bytet av data från servern.
- Innehållsnedladdning: Tiden som spenderas på att faktiskt ladda ner resursen själv.
En hög TTFB, till exempel, är ett klassiskt tecken på en trög backend eller serverbehandlingsproblem—något som ett enkelt ping-test aldrig skulle avslöja. Genom att analysera detta vattenfall kan du snabbt se vilka resurser som blockerar rendering eller bara tar alldeles för lång tid att ladda.
En viktig lärdom från min erfarenhet är att inte bara titta på den totala laddningstiden utan att leta efter de längsta staplarna i vattenfallet. En enda icke-optimerad bild eller ett långsamt tredjeparts-API kan hålla hela sidan som gisslan, vilket skapar en dålig användarupplevelse även om resten av webbplatsen är blixtsnabb.
Programmatisk Mätning med Timing-API:er
För mer automatiserade och precisa mätningar kan du utnyttja webbläsarens inbyggda JavaScript-API:er. Navigation Timing API och Resource Timing API ger dig programmatisk tillgång till samma detaljerade prestandadata som du ser i utvecklarverktygen. Detta är perfekt för att samla in data för verklig användarövervakning (RUM) för att förstå hur din webbplats presterar för faktiska besökare över hela världen.
Du kan hämta dessa mätvärden med bara några rader JavaScript, direkt i webbläsarens konsol. För att få de centrala prestandatiderna för den huvudsakliga sidladdningen, till exempel, kan du använda performance.getEntriesByType('navigation'). Detta returnerar ett objekt packat med värdefulla tidsstämplar.
Från dessa data kan du beräkna viktiga mätvärden:
- DNS-uppslagstid:
domainLookupEnd - domainLookupStart - TCP-handshakets tid:
connectEnd - connectStart - Tid till Första Byte (TTFB):
responseStart - requestStart - Total Sidlastningstid:
loadEventEnd - startTime
Denna metod gör att du kan bygga anpassade instrumentpaneler eller skicka prestandadata till dina analysverktyg, vilket ger dig en kontinuerlig känsla för din applikations verkliga prestanda. Inom webbutveckling är optimering av bilder ett vanligt sätt att förbättra dessa mätvärden; för dem som är intresserade har vi en hjälpsam guide om hur man väljer det bästa bildformatet för din webbplats.
Effektivisera kontroller med integrerade verktyg
Att hoppa mellan terminalen, webbläsarens utvecklarverktyg och anpassade skript kan snabbt bli tråkigt. Här kan integrerade webbläsartillägg verkligen jämna ut ditt arbetsflöde genom att förena dessa kontroller. Till exempel inkluderar ShiftShift Extensions en inbyggd Hastighetstest-verktyg som du kan öppna direkt från vilken flik som helst.
Detta ger dig ett snabbt, integritetsfokuserat sätt att mäta din anslutnings nedladdningshastighet, uppladdningshastighet och latens utan att behöva navigera till en separat webbplats eller öppna en terminal. Eftersom det är en del av ett större verktyg kan du köra ett hastighetstest, formatera ett JSON-svar och kontrollera en cookie, allt från samma enhetliga kommandopalett. Denna typ av integration gör prestandakontroller till en naturlig, friktionsfri del av den dagliga utvecklingsprocessen.
Hur man designar ett latens test som faktiskt ger dig information
Vem som helst kan skicka ett ping-kommando och få ett nummer tillbaka. Men om du vill ha data som du faktiskt kan lita på—data som hjälper dig att fatta verkliga beslut—måste du vara mer medveten. En enda, isolerad mätning är bara en ögonblicksbild i tiden. För att verkligen förstå ditt nätverks beteende måste du tänka som en detektiv, överväga varifrån du testar, hur ofta du testar och vad du verkligen letar efter.
En väl utformad test omvandlar råa siffror till handlingsbara insikter. En dåligt utformad? Den är bara brus.
Diagrammet nedan bryter ner alla små fördröjningar som bidrar till vad en användare känner när de laddar en webbsida. Det är en bra påminnelse om att en enkel nätverks-ping inte ens börjar berätta hela historien.
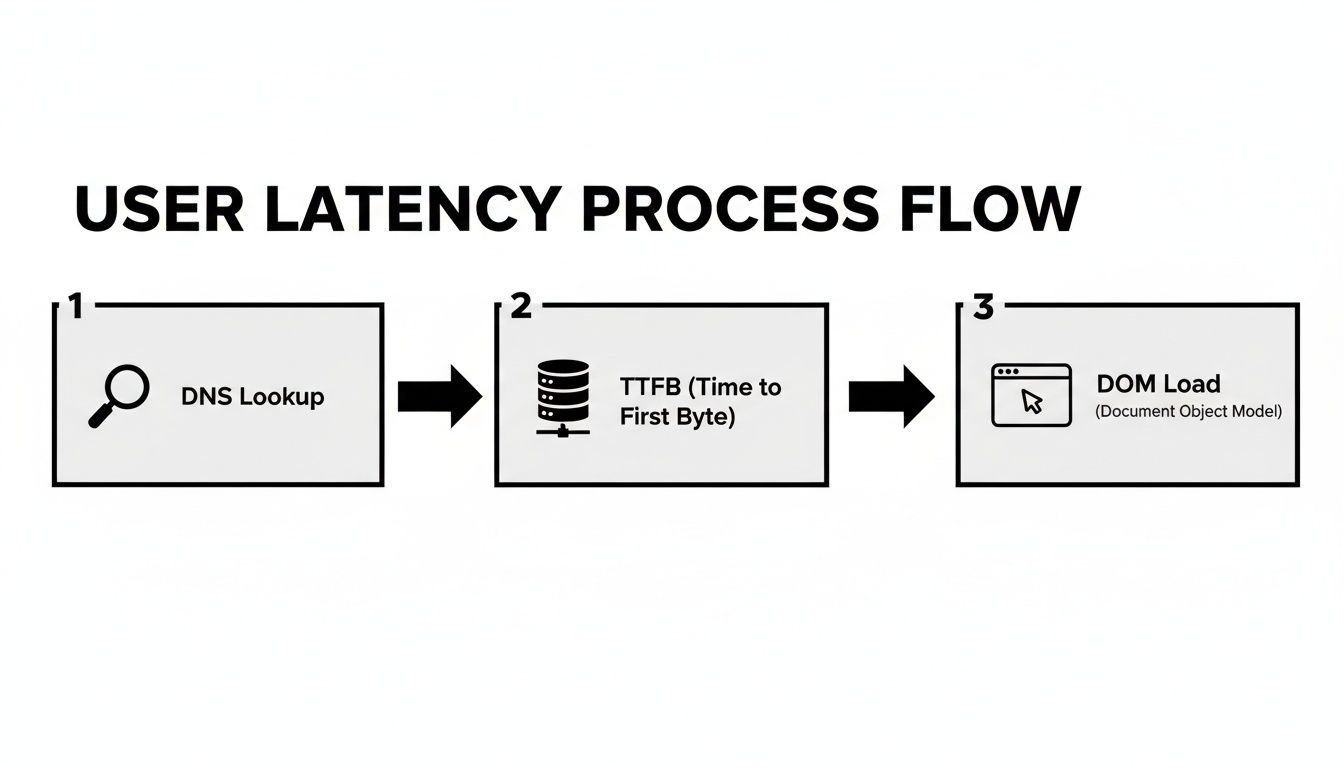
Som du kan se, från den initiala DNS-uppslagningen till den slutliga renderingen, bidrar flera steg till den totala väntetiden.
Välja dina testpunkter
Den första regeln för pålitlig testning är att geografi spelar roll. Ett test från ditt kontor i New York till en server längre ner på vägen i New Jersey säger dig absolut ingenting om upplevelsen för dina kunder i Tokyo. För att få en realistisk bild måste du testa från olika platser som faktiskt speglar din användarbas.
Din lista över punkter bör täcka några viktiga områden:
- Dina största användarhubbar: Var bor de flesta av dina kunder? Testa därifrån.
- Tvärkontinentala vägar: Se vad som händer när data måste korsa ett hav. Testa mellan Europa och Nordamerika, eller Asien och USA, för att förstå långdistansprestanda.
- Dina molnregioner: Om du är på AWS, Azure eller GCP, testa anslutning till och mellan de specifika datacenterregioner du förlitar dig på.
Att sprida ut dina tester på detta sätt skapar en mycket mer exakt karta över global prestanda. Det hjälper dig att upptäcka regionspecifika flaskhalsar som du annars skulle missa helt. Detta är också ett bra tillfälle att dubbelkolla din domäninställning; du kan hitta hjälpsamma tips om hur man kontrollerar domänens tillgänglighet och relaterade konfigurationer för att säkerställa att allt är i ordning.
Hitta rätt testrytm
Nätverksförhållanden är ständigt i förändring. De ändras under dagen, veckan och till och med minuten. Ett test som körs klockan 3 på morgonen en tisdag kan se fantastiskt ut, men det resultatet är värdelöst om din topptrafik inträffar klockan 14 på en fredag när alla är online.
För att få en sann baslinje måste du testa konsekvent över tid. Variera:
- Kör tester under högtrafik timmar.
- Planera några för underhållsfönster på natten.
- Glöm inte helgerna, när trafikmönster kan vara helt olika.
Genom att upprepade gånger samla in data kan du jämna ut de slumpmässiga topparna och dalarna. Så här upptäcker du återkommande problem, som att nätverket blir överbelastat varje vardagseftermiddag direkt efter lunch.
Glöm inte jitter
Genomsnittlig latens är en solid utgångspunkt, men den döljer ofta ett mer illavarslande problem: jitter. Jitter är helt enkelt variationen i din latens över tid. Tänk på det—en stabil anslutning med en förutsägbar 80ms fördröjning är ofta mycket bättre för realtidsappar än en som i genomsnitt är 50ms men hoppar vilt mellan 10ms och 200ms.
Jitter är den tysta mördaren av användarupplevelsen för allt realtid, som VoIP-samtal, videokonferenser eller onlinespel. Hög jitter orsakar hackigt ljud, fryst video och frustrerande fördröjningar som får en applikation att kännas helt trasig, även när den genomsnittliga latensen ser bra ut på papper.
Att förstå jitter innebär att se bortom genomsnittet. Det är den osjungna skurken eftersom det avslöjar varför genomsnittet ensamt kan vara så missvisande. Till exempel visar data från Pandora FMS att jitter över 30ms kan öka paketförlusten i spel till 15%—tillräckligt för att göra ett spel ospelbart. Att mäta standardavvikelsen av dina latensresultat är det första steget för att sätta ett nummer på den instabiliteten.
Checklista för latens testdesign
För att sammanfoga allt detta, här är en snabb checklista för att vägleda dig. Att följa dessa steg kommer att hjälpa till att säkerställa att de data du samlar in är både korrekta och verkligen användbara.
| Checklista Post | Varför det är viktigt | Handlingsbar tips |
|---|---|---|
| Definiera tydliga mål | Du kan't mäta vad du inte definierar. Felsöker du ett specifikt problem eller etablerar en baslinje? | Skriv ner ditt mål innan du börjar. "Diagnostisera fördröjning för användare i Sydostasien" är ett bättre mål än "kontrollera latens." |
| Välj olika punkter | En enda väg representerar inte din globala användarupplevelse. | Välj 3-5 platser: en lokal, en på en annan kontinent och några i dina nyckelanvändarmarknader. |
| Etablera en rytm | Engångstester missar tidsbaserade mönster som högtrafikbelastning. | Planera tester att köras automatiskt varje timme under en vecka för att fånga en full cykel av nätverksbeteende. |
| Mät jitter | Genomsnitt döljer den oregelbundna prestanda som förstör realtidsapplikationer. | Titta inte bara på den genomsnittliga RTT. Beräkna standardavvikelsen eller använd ett verktyg som mtr som visar min/max/avg latens. |
| Använd rätt verktyg | ping är bra för en snabb kontroll, men verktyg som mtr eller iperf ger djupare insikter. |
För webbprestanda, använd webbläsarens utvecklarverktyg. För råa nätverksvägar är mtr ett utmärkt val. |
| Dokumentera allt | Du kommer att glömma "varför" bakom ditt test om sex månader. | Håll en enkel logg: datum, tid, punkter, verktyg som användes och en kort anteckning om vad du observerade. |
Genom att vara metodisk går du från att bara mäta latens till att verkligen förstå den. Denna genomtänkta metod är vad som skiljer ett slumpmässigt nummer från en pålitlig prestandaindikator.
Att förstå siffrorna (och vad man ska undvika)
Okej, du har kört dina tester och har en hög med data. Det är här det verkliga arbetet börjar—att översätta dessa råa siffror till något som faktiskt betyder något. Data berättar en historia om ditt nätverks hälsa; du måste bara lära dig att läsa den.
Till exempel, en plötslig topp i Round-Trip Time (RTT) på en traceroute är en klassisk ledtråd. Om latensen hoppar vid hopp nummer tre och förblir hög hela vägen till slutet, har du sannolikt hittat ditt problem: det är den tredje routern eller länken precis efter den. Men var försiktig. Om endast det enskilda hoppet visar hög latens och den slutliga destinationen fortfarande är snabb, kan det bara vara en router som är konfigurerad för att nedprioritera den exakta typen av trafik som ditt test använder. Det är en vanlig falsk alarm som kan skicka dig ner i en kaninhål.
Avkoda jitter och paketförlust
Att se bortom enkel RTT är där du hittar de mest kritiska insikterna. Hög jitter, som bara är ett fint ord för inkonsekvent latens, kan vara mycket mer störande än latens som är konsekvent hög. Detta gäller särskilt för allt realtid.
Om dina resultat visar en genomsnittlig RTT på 40ms, men minimum var 10ms och maximum var 150ms, är din anslutning instabil. Den massiva variansen är exakt vad som orsakar irriterande hackningar i videosamtal och rasande fördröjningar i onlinespel.
Paketförlust är en ännu större varningssignal. Även 1% paketförlust kan helt förlama TCP-baserade applikationer, vilket tvingar dem att ständigt skicka om data och sänka allt till en snigelfart. När du ser på dina testresultat, behöver varje verklig skillnad mellan skickade och mottagna paket undersökas omedelbart.
En av de största misstagen jag ser folk göra är att anta att ett enda test berättar hela historien. Nätverksförhållanden förändras ständigt. Ett test som körs klockan 3 på morgonen kommer att se helt annorlunda ut än ett klockan 15 under högtrafik timmar. Det enda sättet att få en sann prestandabaslinje är genom konsekvent, upprepad testning.
För att förebygga problem är det värt att titta på dedikerade verktyg för nätverksövervakning. Detta skiftar din strategi från att frenetiskt fixa saker när de går sönder till att proaktivt hålla ditt nätverk friskt.
De vanligaste mätfelen
Även med de bästa verktygen i världen kan några enkla misstag göra dina resultat helt värdelösa. Att undvika dessa vanliga fallgropar är icke-förhandlingsbart om du vill ha data som du faktiskt kan lita på.
- Testa över Wi-Fi: Seriöst, gör det inte. Trådlösa anslutningar är notoriska för att vara opålitliga, benägna att störas av allt från mikrovågsugnar till din grannes router. För seriös latens testning, koppla in med en Ethernet-kabel. Det är det enda sättet att få en stabil, pålitlig baslinje.
- Glömma VPN-överhead: VPN:er är bra för säkerhet, men de lägger till ett extra stopp och kryptering till din trafiks resa. Detta kommer alltid att öka latensen. Om du försöker diagnostisera en användares långsamma anslutning, bör en av dina första frågor vara, "Är du på VPN?" Att testa med och utan det kommer att visa dig exakt hur mycket fördröjning det lägger till.
- Ignorera lokal nätverksbelastning: Dina testresultat kommer att bli snedvridna om någon annan på ditt nätverk tar all bandbredd. Om en kollega streamar 4K-video eller laddar ner stora filer medan du testar, kommer dina latenssiffror att vara uppblåsta, och du kommer att sluta jaga ett problem som inte existerar.
En annan subtil men kritisk faktor är det verktyg du väljer. Som vi har täckt, mäter olika verktyg latens på olika sätt. Var alltid konsekvent med de verktyg du använder för jämförelse, och se till att du förstår vad varje verktyg faktiskt mäter—oavsett om det är en enkel ICMP-återkoppling eller en komplex, applikationsnivåförfrågan. Och kom ihåg, prestanda kan påverkas av många lager; till exempel, om du gräver i webbprestanda, kan vår guide om en Cookie Editor Chrome Extension visa hur klientbaserade element spelar en roll.
Genom att tolka dina resultat med rätt sammanhang och undvika dessa vanliga misstag, kommer du att gå bortom att bara samla in siffror. Du kommer att börja förstå varför bakom ditt nätverks prestanda, och det är nyckeln till att bygga snabbare, mer pålitliga system.
Vanliga frågor om nätverkslatens
Även med rätt verktyg verkar några vanliga frågor alltid dyka upp när du börjar gräva i nätverkslatens. Låt oss gå igenom några av de mest frekventa som jag hör för att hjälpa dig att förstå dina resultat.
Vad är egentligen ett "bra" latensnummer?
Detta är den klassiska "det beror på" frågan, men vi kan definitivt sätta några solida riktmärken. En "bra" latens är helt relativ till vad du försöker åstadkomma.
- Avslappnad webbläsning: För de flesta av oss kommer allt under 100ms RTT att kännas helt okej. Sidor laddas snabbt, och du kommer inte att märka någon verklig fördröjning.
- Konkurrensutsatt onlinespel: Här räknas varje millisekund. Seriösa spelare och högfrekventa handlare letar efter latens långt under 20ms. Det är skillnaden mellan att vinna och förlora.
- Videosamtal & VoIP: Här är konsekvens kung. Du behöver en stabil latens under 150ms och låg jitter (mindre än 30ms) för att undvika den hackiga, ur synk-känslan eller, ännu värre, avbrutna samtal.
Som en tumregel skulle de flesta nätverksproffs jag känner klassificera allt under 50ms som låg latens. Från 50-150ms är måttlig, och när du kryper över 150ms kommer du att börja känna draget på de flesta interaktiva applikationer.
Varför matchar aldrig mina ping- och webbläsartestresultat?
Detta är en fantastisk fråga och en supervanlig förvirring. Det händer eftersom ett kommandorads ping och ett webbläsarbaserat hastighetstest är fundamentalt olika verktyg som mäter olika saker.
För det första pratar de nästan säkert med olika servrar. När du pingar en domän, träffar du ett specifikt mål. Ett webbhastighetstest, å sin sida, är utformat för att hitta en geografiskt nära server från sitt eget nätverk för att ge dig det bästa möjliga resultatet.
Protokollen är också helt olika. Ping använder ett mycket lätt protokoll som kallas ICMP. De flesta webbläsartester körs över TCP, vilket kräver en hel installationsprocess (den "trevägs handskakningen") bara för att etablera en anslutning. Den initiala fram-och-tillbaka lägger till lite tid innan det verkliga testet ens börjar.
Slutligen bakar webbläsartester ofta in mer än bara ren nätverksresertid. Deras "latens" nummer kan inkludera serverbehandlingstid eller till och med små fördröjningar inom din webbläsare själv, vilket kan blåsa upp den slutliga siffran jämfört med en rå ICMP-ping.
Hur kan jag faktiskt sänka min nätverkslatens?
Att minska latens handlar om att jaga och eliminera flaskhalsar, oavsett om de finns på ditt kontor eller över internet.
Den första platsen att titta på är din omedelbara miljö. Den mest effektiva förändringen du kan göra är att byta från Wi-Fi till en trådad Ethernet-anslutning. Det är en spelväxlare för stabilitet och hastighet. Om du måste använda Wi-Fi, kom närmare din router och hoppa på 5GHz-bandet om du kan – det är vanligtvis mindre trångt.
Ser man bortom ditt lokala nätverk kan en DNS-byte ibland hjälpa. Att använda en snabbare DNS-server kan spara några millisekunder från den initiala anslutningstiden när du söker efter en webbplats.
Om du försöker förbättra åtkomsten till en tjänst som du kontrollerar, är ett Content Delivery Network (CDN) svaret. Det fungerar genom att placera kopior av ditt innehåll fysiskt närmare dina användare. Och om du använder en VPN, försök att stänga av den. Det extra steget och krypteringslagret lägger nästan alltid till latens.
Jag har sett företags-VPN lägga till så mycket som 70ms till en rundturstid. Det kan förvandla en bra anslutning till en frustrerande långsam. Testa alltid med och utan din VPN för att se vilken typ av prestandaförlust du faktiskt upplever.
Vad är den verkliga skillnaden mellan latens och bandbredd?
Att få detta rätt är grundläggande för att förstå nätverksprestanda. Det är lätt att blanda ihop dem, men de mäter två helt olika saker.
Här är analogin jag alltid använder: tänk på det som en motorväg.
- Bandbredd är hur många fält motorvägen har. Fler fält betyder att fler bilar (data) kan färdas samtidigt.
- Latens är hastighetsgränsen. Den dikterar hur snabbt en enda bil (ett datapaket) kan ta sig från A till B.
Du kan ha en massiv, tio-fälts motorväg (stor bandbredd) med en hastighetsgräns på 20 mph (hög latens). Du skulle kunna flytta en massa data så småningom, men realtidsgrejer som ett videosamtal skulle vara plågsamt långsamt. Å andra sidan känns en anslutning med mycket låg latens otroligt snabb och responsiv, även om dess bandbredd inte är enorm. Du behöver verkligen en bra balans mellan båda för en fantastisk upplevelse.
Redo att göra prestandatestning till en sömlös del av ditt dagliga arbetsflöde? ShiftShift Extensions svit ger en kraftfull hastighetstest, JSON-formatterare och dussintals andra utvecklarverktyg direkt i din webbläsare, tillgängliga med ett enda kommando. Sluta jonglera flikar och börja arbeta smartare. Ladda ner ShiftShift Extensions gratis och superladda din produktivitet idag.