富文本转Markdown终极转换指南
厌倦了格式错乱?学习如何完美地将富文本转换为Markdown。掌握开发者工具、剪贴板技巧和工作流程自动化。

于是,当你尝试把Google文档或网页内容复制到Markdown平台时,整个格式都乱了。列表一团糟,加粗文字消失,标题只剩下纯文本。听起来很熟悉?
这个经典问题几乎所有人都遇到过。它正是富文本编辑器的可视化世界与Markdown简洁代码化世界之间的摩擦所在。
本质上,将 富文本转换为Markdown 就是把那些视觉样式——加粗、斜体、链接和列表——翻译成Markdown能理解的简单纯文本语法。如果不经这一步,你粘贴的只是一堆大多数Markdown系统无法正确解析的隐藏HTML代码。
内容创作的两大阵营
一边是“所见即所得”(WYSIWYG)编辑器。比如 Google Docs, Notion,甚至你的电子邮件编辑器。它们很直观——点击按钮就能加粗文字,而它确实 看起来就是加粗的。一切都是视觉化的。
另一边则是Markdown。这是一种为简洁性和可读性而生的轻量级标记语言。你无需使用隐藏代码,只需用星号(**bold**)或井号(# Headings)这样的简单字符来标记格式。它之所以成为开发者文档、技术博客和版本控制的标准,是因为它简洁、可移植且易于预测。
脱节之所以产生,是因为这两种系统在思考“格式”的方式上根本不同。随着开发者工具的兴起,这个问题变得尤为突出。从21世纪00年代末开始,Markdown悄然成为技术写作的首选。由于像 GitHub(它在2008年就添加了Markdown支持,并报告截至2023年托管超过 2亿个代码仓库)这样的平台普及,正确完成这种转换如今已成为我们许多人的日常任务。
富文本与Markdown的核心差异
要真正理解为什么简单的复制粘贴常常失败,不妨看看两者的核心差异。富文本将复杂性隐藏在可视化界面背后,而Markdown则让其简单语法清晰可见、易于掌控。
| 属性 | 富文本(HTML/WYSIWYG) | Markdown |
|---|---|---|
| 格式化 | 存储为隐藏的HTML标签或专有代码。 | 存储为纯文本字符(例如,**bold**, *italic*). |
| 可移植性 | 在不同应用程序间移动时常常会出错。 | 具有高度可移植性;在不同平台上能保持一致工作。 |
| 可读性 | 原始代码对非开发人员来说难以阅读。 | 原始文本简洁且易于阅读。 |
| 控制性 | 提供可视化工具,但可能添加不必要的样式。 | 提供对每个元素的精确、显式控制。 |
归根结底,了解如何正确转换富文本不仅仅是为了让内容看起来合适。这在几乎所有现代技术环境中都是保持文档整洁、内容工作流顺畅以及协作高效的必备技能。
“快速简便”的在线转换器背后的隐性成本
那么,你需要将一些富文本转换成Markdown。第一步该怎么做?对大多数人来说,通常是快速搜索一个免费的在线工具。你找到一个界面简单的网站,只需粘贴并转换,然后将Google文档中的内容粘贴进去——瞧——你就得到了 看起来 很干净的Markdown。这感觉像是一次成功,但相信我,这种方法往往带来的问题比解决的更多,尤其是在你处理重要内容时。
对我来说,最大的警告信号始终是 数据隐私当你将文本粘贴到一个随机网站时,你实际上是在把内容交给第三方服务器。如果那段文本是未发布的产品文档、公司内部笔记或任何稍有敏感性的内容,你就制造了一个重大的安全风险。你完全不清楚这些数据是如何被存储、记录,或者未来可能被如何使用的。
即使你不担心隐私问题,输出质量也常常令人失望。这些简单工具通常只能处理最基本的任务。一旦你输入任何复杂内容——比如嵌套列表、带有合并单元格的表格,甚至只是你原编辑器中的一些特定格式——事情就往往会出问题。最终,你花费在清理一团糟上的时间,比你使用这个工具“节省”下来的时间还要多。
清理工作的麻烦
让我们来看一个我经常遇到的场景:将一篇技术博客的草稿从共享文档转移到用于静态站点生成器(如 Jekyll 或 Hugo)的 Markdown 文件中。文档里包含了所有常见元素:标题、加粗文本、代码块和一些列表。
基本的在线转换器可能能够正确处理标题和加粗,但细节上就会出问题。
- 代码块: 你精心格式化的代码片段通常无法被正确地包裹在三个反引号(```)中,而是作为纯文本输出,丢失所有的缩进和语法提示。
- 嵌套列表: 多级大纲可能会被完全扁平化为一个冗长的单级列表,这会彻底破坏文档的逻辑流程。
- 字符编码: 特殊字符甚至表情符号可能会变得乱码,在最终文档中留下奇怪的符号。
这就是许多在线编辑器的现状。它们界面整洁,非常适合从头开始编写 Markdown,但它们“粘贴即转换”的逻辑根本无法处理导入富文本的细微之处。
一个“免费”转换器的真正成本不是金钱;而是你浪费在手动清理上的时间,以及你承担的数据风险。一个制造更多工作的工具不是一个解决方案。
归根结底,尽管这些浏览器内工具可能适合快速、非敏感的简单文本转换,但它们为任何严肃的工作流程引入了一个脆弱且低效的环节。修复所有小格式错误所花费的时间会迅速累积,使得这个常见的第一步成为任何需要可靠 富文本转 Markdown 流程的人的糟糕选择。
通过命令面板实现更智能的工作流
说实话,手动转换很麻烦。在标签页之间切换,将文本粘贴到某个随机的在线工具中,然后再复制回来——这是一个笨拙的多步骤操作,会把你从心流中拉出来。一天这样做十几次,浪费的时间和分散的注意力真的会累积起来。
但是,如果整个过程可以瞬间完成,而无需离开你所在的页面呢?
这就是以键盘为核心的方法(比如使用 ShiftShift Extensions 命令面板)彻底改变游戏规则的地方。你无需导航到某个网站,只需用键盘快捷键调出命令栏。它将一项繁琐的杂务变成了你自然工作流中无缝衔接、转瞬即逝的一部分。
即时执行转换
整个构想都是为了速度。假设你刚刚从 Google Docs 或一篇博客文章中复制了一段格式化的文本。当这些富文本在你的剪贴板上时,你只需唤出命令面板。
在 Mac 上,这是一个快速的 Cmd+Shift+P。在 Windows 或 Linux 上,它是 Ctrl+Shift+P.
命令面板一打开,你就可以输入"markdown"。"将富文本转换为 Markdown"的命令会立即出现。按下回车键,瞬间完成——格式完美的 Markdown 就已经在你的剪贴板上,可以粘贴到任何需要的地方了。整个过程可能只需要两秒钟。无需切换上下文,也不会失去焦点。
真正的优势不仅仅在于速度——更在于安全性。像 ShiftShift 这样的工具完全在本地处理,就在你的浏览器内部进行。你的数据永远不会发送到第三方服务器,这完全避开了使用大多数在线转换器时会遇到的隐私风险。
这个简单的流程图清晰地分解了这个决策过程。
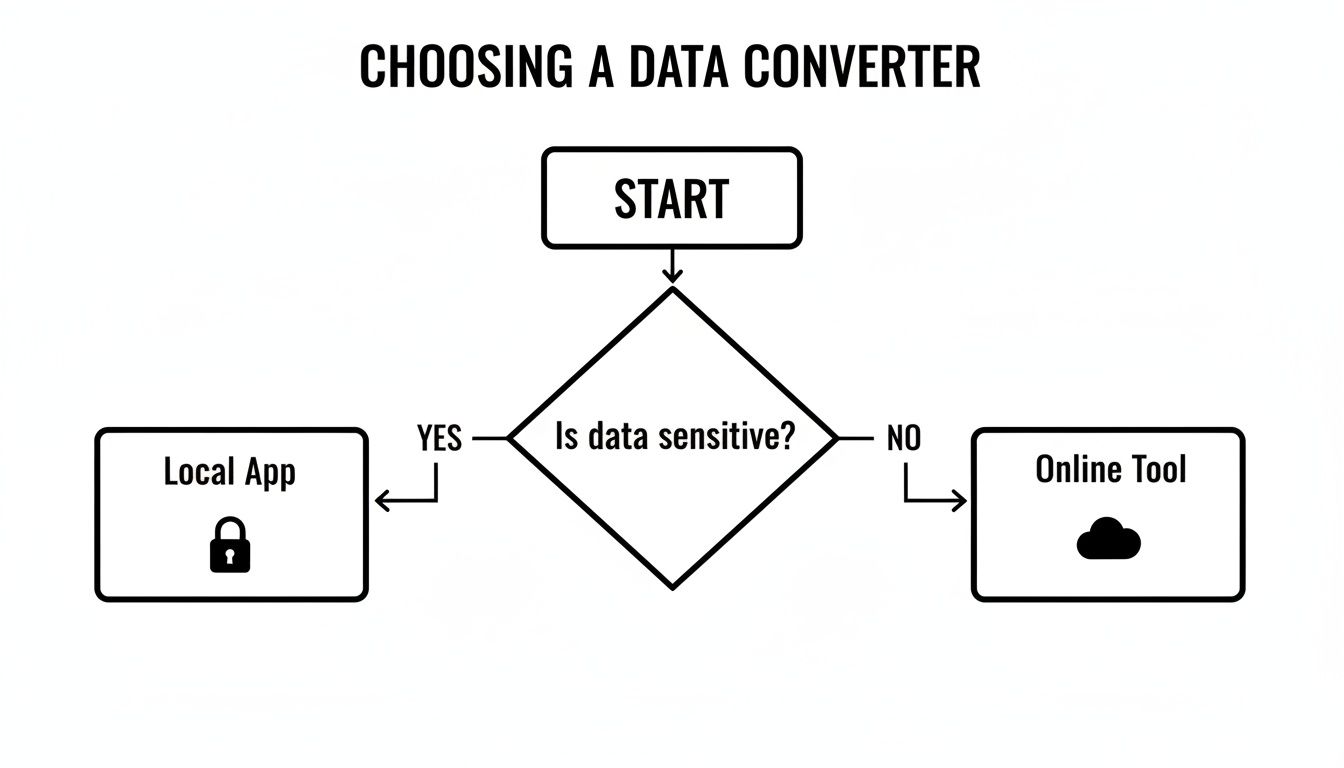
结论很简单:如果数据哪怕有一点点敏感,使用本地的、离线优先的工具是唯一的选择。
集成工具与在线工具对比
虽然命令面板提供了一个流畅且安全的解决方案,但看看它与其他方法的对比也是值得的。例如,一个 在线 Markdown 所见即所得编辑器 提供可视化界面,对于即时检查格式确实很有用。
然而,根本的区别在于工作流程。在线工具始终是一个你必须 前往 的独立目的地。而集成的命令面板是一个你 就在当前所在位置 执行的操作。
正是这种区别,使得许多开发者、写手和高效能用户倾向于选择那些内置于其主要工作环境中的工具。如果你希望真正提升基于浏览器的生产力,查看 最佳生产力 Chrome 扩展(在 https://shiftshift.app/blog/best-productivity-chrome-extensions 上),可以让你大开眼界,了解各种可能性。
最终,对于像 富文本转 Markdown 这样的常见任务,选择集成工具就是为了消除那些打断你节奏和专注力的小干扰。
如何避开常见的转换陷阱
任何 富文本转 Markdown 转换器的真正考验不在于它如何处理简单的粗体或斜体文本——而在于当你抛出复杂内容时它能否经受住考验。你可能前一分钟还觉得转换顺畅,下一分钟就因为列表、表格和图片等未能成功转换而陷入令人沮丧的清理工作。
理解 为什么 理解这些元素为何会出错是第一步。大多数情况下,问题归根结底在于富文本(通常基于HTML)和Markdown之间根本的设计差异。富文本专为视觉复杂性而构建;Markdown则追求结构的简洁性。这种冲突在高级排版中会变得极其明显。
与嵌套列表的搏斗
嵌套列表是最常见的牺牲品之一。你可能在源文档中有一个结构完美的大纲,但转换后,它往往会被扁平化成一片令人困惑的混乱。
这是因为富文本编辑器使用了复杂的HTML(<ul> 和 <ol> 标签内嵌套 <li> 条目)来创建层级结构,而这种结构并不总能与Markdown的简单缩进规则清晰对应。
- 转换前(富文本): 您看到的是一个层次分明的多级列表,其中父项和子项关系清晰。
- 经历错误转换后: 那些精心布置的子项突然全部被提升为顶级项,整个层级结构完全被破坏。
修复方法几乎总是需要手动操作。你需要回到Markdown编辑器中,重新调整列表项的缩进,并特别注意间距(通常每级缩进两个或四个空格),以恢复原始结构。
表格的困扰
表格是另一个令人头疼的大问题。虽然Markdown的管道表语法简洁优美,但这恰恰也是它的弱点——它根本无法处理富文本编辑器中常见的高级功能。
这就是复杂表格经常出错的原因:
- 合并单元格: Markdown 表格没有
colspan或rowspan的概念。如果你的原始表格合并了单元格,转换器很可能会出错。 - 多行内容: 单元格内的换行在转换过程中很容易破坏整个表格结构。
- 内联格式: 单元格中的加粗、斜体或链接有时无法正确转换。
当表格出现错乱时,最佳方案通常是使用 Markdown 语法从头重建。虽然繁琐但效果显著。对于特别复杂的数据,或许可以直接嵌入 HTML <table> 代码块到 Markdown 文件中,因为大多数渲染器都能正常显示。
核心难点在于富文本和 Markdown 存储结构信息的方式存在根本差异。这在大规模迁移场景中尤为明显,此时人工修复并不现实。
我在大型项目中亲身经历过这种情况。批量迁移数千个文件会暴露各类结构问题——表格单元格合并失效、标题层级不一致,以及需要大规模清理的残留 HTML 片段。你可以在以下资源中找到一些优秀的 关于转换脚本的社区讨论 深入探讨开发者在实际工作中如何处理这些问题。
消失的图片和媒体
最后,让我们谈谈图片。当你从网页或文档中复制富文本时,你复制的并不是图片文件本身——你只是复制了一个 引用 指向它。大多数基础转换器根本不知道如何处理这个引用。
结果呢?你的图像就这样消失了,只留下一个损坏的链接,或者更糟的是,什么都没留下。
要修复这个问题,你需要使用 Markdown 语法重新插入图像: 这意味着你必须先将图片上传到可通过公开 URL 访问的位置,然后链接到它。
当你处理多个格式错误时,发现所有细微的差异可能很困难。并排比较工具在这里是救星。
下表总结了我遇到的一些最常见问题及其快速修复方法。
常见转换错误的故障排除
| 问题区域 | 典型问题 | 推荐修复方法 |
|---|---|---|
| 嵌套列表 | 所有子项被扁平化为单层列表,丢失了所有层级结构。 | 手动添加缩进(通常 2-4个空格)在每个子项前,以恢复结构。 |
| 表格 | 表格结构被破坏,特别是当存在合并单元格或单元格内包含多行文本时。 | 使用 Markdown 管道语法重建表格。对于复杂情况,可嵌入原始 HTML 表格。 |
| 图片 | 转换后图片完全消失或显示为损坏的链接。 | 将图片上传至托管服务,获取公共 URL,然后使用  语法重新插入。 |
| 特殊字符 | 诸如 <, > 和 & 的字符会被错误解析,导致布局混乱。 |
使用反斜杠手动转义这些字符(例如 \<),或将其替换为 HTML 实体。 |
使用差异检查工具比对原始内容和输出结果,能显著简化整个流程。您可以在线使用工具,通过粘贴原始文本和转换后文本进行 免费在线文本对比(例如在 https://shiftshift.app/blog/compare-text-online-free),这几乎能让格式错误一目了然。
高级用户的自动化转换
对于开发者、技术写作者或需要处理批量内容的用户而言,手动转换文档显然不可持续。当面对海量文件或需要将转换功能集成到应用程序中时,就必须从程序化角度考虑。这时我们就要告别简单的复制粘贴技巧,开始实现全流程自动化。
这已不再是小众问题。将富文本转换为干净 Markdown 的需求已成为众多工具的核心功能,这都源于现实中的痛点。我在 Joplin 等社区亲眼见过这种情况:用户从其他应用导入笔记后,重新加载时格式会消失。这类问题促使开发者将转换器直接内置到软件中。您可以在 DEVONtechnologies 社区论坛.
看到关于这些可用性挑战的类似讨论。利用JavaScript库
如果您身处Web开发领域,JavaScript库将是完成此项任务的最佳助手。我首推的解决方案是turndown。这是一个功能极其强大且高度可配置的库,能够接收HTML并输出整洁优美的Markdown格式。无论是在Node.js服务端脚本还是客户端应用中,它都能同样出色地完成工作。
例如,您可以快速编写一个Node.js脚本来处理本地HTML文件,并将其转换为Markdown格式保存。
const TurndownService = require('turndown');
const fs = require('fs');
const turndownService = new TurndownService();
const htmlContent = fs.readFileSync('source.html', 'utf8');
const markdown = turndownService.turndown(htmlContent);
fs.writeFileSync('output.md', markdown);
console.log('Conversion complete!');
这类脚本非常适合批量处理文件夹中的所有文件,或是将转换步骤整合到更大的内容处理流程中。
程序化转换真正的魔力在于其一致性。一旦设置好规则,每次转换都会遵循相同的逻辑。这完全消除了人工操作中可能出现的错误和随意的不一致性。
另一个巧妙的技术是直接在浏览器中处理粘贴事件。您可以编写一段JavaScript代码,在用户粘贴内容时拦截HTML,即时将其转换为Markdown,然后将整洁的版本插入到您的文本编辑器中。这创造了无缝体验,自动整理来自Google Docs或Word的杂乱内容。虽然这是一个细微的功能,但对于任何构建Web编辑器的人来说,这都是一个变革性的特性。
库与命令行工具的选择
当您的需求超出简单HTML处理时,可能需要使用更强大的工具:命令行界面(CLI)工具。在这个领域,Pandoc是无可争议的冠军。它是文档转换的"瑞士军刀"。虽然像turndown这样的库在HTML转Markdown方面表现出色,但Pandoc能够处理数十种格式,从DOCX、RTF到LaTeX乃至更多格式间的相互转换。
那么,应该如何选择呢?这完全取决于您的项目需求。
- 当您在构建Web应用或Node.js环境内工作时,请使用JavaScript库(
turndown))。它轻量、专注,能够完美完成工作。 - 当处理多种文件格式或在Shell脚本环境中需要将命令串联起来时,请使用命令行工具(Pandoc)。
对于那些希望使用自动化功能但又不愿深入代码的用户而言,基于浏览器的工具如 ShiftShift 扩展提供了绝佳的折中方案。它们将脚本解决方案的速度与可靠性,全部集成于一个易于使用的命令面板中。这对大多数高级用户而言是理想的平衡方案。
思考不同格式的特性表现——正如我们在如何将 Word 转换为 PDF指南中探讨的那样——能让你更深入地理解文档工作流。若想获得更广阔的视野,研究如何将 PDF 转换为 Markdown相关资源,则能展现文档转换领域的深奥程度。
关于富文本转换为 Markdown 的常见问题
即便拥有完善的工作流,将富文本转换为 Markdown 仍可能遇到挑战。你可能在特定文件上遇到障碍,或单纯地想寻求更优的解决方案。让我们深入探讨我在转换过程中常被问及的一些高频问题。
厘清这些细节将帮助你规避常见问题,并构建出真正可靠的处理流程。
在线转换工具是否安全可靠?
这完全取决于使用场景。在线富文本转 Markdown工具的安全性,本质上取决于你转换的内容。如果是公开博客文章的草稿或其他非敏感信息,通常没有问题。但若涉及公司内部文档、私人笔记或任何专有信息,将其粘贴至陌生网站将带来巨大的安全风险。
基本准则在于:若数据无法公开,转换过程也不应公开。一旦将敏感内容粘贴到第三方网站,你便失去了控制权。数据存储位置及可能访问者都将成为未知数。
能否直接从 Word 或 Google 文档复制粘贴?
可以,但必须谨慎。从Google 文档或Microsoft Word复制时,你获得的不仅是文本,还包含描述格式的复杂底层 HTML 代码。
- 对于仅含粗体、斜体和基础列表的简单文档,多数合格的转换工具都能轻松处理剪贴板中的 HTML 代码。
- 对于包含表格、脚注、修订痕迹或嵌入图表的复杂文档——转换结果几乎必然混乱不堪,需要大量手动调整。
求助!转换后图片消失了。
这可能是最常见的"陷阱"。当您复制包含图片的富文本时,实际上复制的并非图片文件本身。您只是复制了一个指向该图片位置的引用,而标准转换器无法通过这个引用追溯到原始文件。
唯一的解决方法是单独处理图片:
- 首先,将原始文档中的每张图片单独保存。
- 然后,将它们上传到您的网络服务器、CDN或其他您使用的资源托管平台,为每张图片获取一个公共URL。
- 最后,返回您的Markdown文件,使用正确的语法手动添加图片:``。
那么,哪种工具最适合这项工作?
"最佳"工具实际上取决于您的身份和需求。
如果您只是偶尔转换非机密内容,任何信誉良好的在线工具都能胜任。但如果您经常需要进行此操作,一个内置于浏览器并通过快捷键驱动的工具——比如ShiftShift Command Palette——将显著提升效率和安全性。对于需要批量转换文件或自动化流程的开发者而言,像turndown库这样的程序化工具,或是功能强大的命令行工具Pandoc.
准备好摆脱笨重的网络工具和手动清理了吗?ShiftShift Extensions通过闪电般快速的命令面板,将强大且注重隐私的富文本转Markdown转换器直接集成到您的浏览器中。无需离开当前页面即可即时转换剪贴板内容。立即下载ShiftShift Extensions,彻底改变您的工作流程。