Hvordan man måler netværkslatens: En praktisk guide for udviklere
Lær hvordan man måler netværkslatens med denne omfattende guide. Vi dækker essentielle værktøjer som ping og traceroute samt browserbaserede testteknikker.

Anbefalede udvidelser
Vil du måle netværkslatens? Du kan starte med enkle, indbyggede kommandolinjeværktøjer som ping og traceroute for at få et hurtigt indblik i Round-Trip Time (RTT). Eller du kan åbne din browsers udviklerværktøjer for at se, hvordan forsinkelser påvirker, hvad dine brugere faktisk oplever.
Disse metoder giver dig et hurtigt, nyttigt snapshot af, hvor lang tid det tager for en datapakke at rejse fra en kilde, nå en destination og komme tilbage.
Hvorfor Måling af Latens Er Uundgåelig
Før vi går ind i "hvordan", lad os tale om "hvorfor". For udviklere og netværksingeniører er latens ikke bare et tal på en skærm; det er den usynlige hånd, der former hele brugeroplevelsen. I dagens applikationer er millisekunder alt. Selv en lille forsinkelse kan være forskellen mellem en tjeneste, der føles øjeblikkelig, og en, der føles defekt.
Tænk på de virkelige konsekvenser:
- API Responsivitet: Et enkelt langsomt API-kald kan skabe en dominoeffekt, der holder alt fra indlæsning af en brugers profil til behandling af en kritisk betaling oppe.
- Real-Time Data Streams: For online gaming, live video eller finansiel handel er lav og konstant latens den absolutte grundsten. Uden det fungerer disse applikationer simpelthen ikke.
- Brugerfastholdelse: Der er en direkte forbindelse mellem langsomt indlæsende hjemmesider og apps til højere afvisningsrater og forladte indkøbskurve. Dette påvirker bundlinjen hårdt.
Adskillelse af Nøglelatensbegreber
For at måle netværkslatens nøjagtigt skal du vide, hvad du kigger på. De to mest grundlæggende begreber er Round-Trip Time (RTT) og envejslatens.
RTT er den samlede tid, det tager for et signal at gå fra punkt A til punkt B og tilbage igen. Det er den mest almindelige måling, du vil se, fordi den er ligetil at måle—du har kun brug for adgang til den ene ende af forbindelsen.
Envejslatens, som navnet antyder, måler den tid, det tager for data at rejse i kun én retning. Dette er en meget sværere måling at få korrekt, fordi det kræver perfekt synkroniserede ure ved begge endepunkter. Det er dog en langt mere præcis indikator for asymmetrisk forbindelser, hvor dine upload- og downloadveje opfører sig meget forskelligt.
Vigtigheden af alt dette bliver krystalklar, når du laver seriøs belastningsprøvning, hvor teori møder virkelighed, og flaskehalse bliver afsløret.
For at sætte nogle tal på det, klassificerer netværksovervågningsspecialister generelt latens på denne måde:
- Lav latens: Under 50 millisekunder
- Moderat latens: 50-150 ms
- Høj latens: Over 150 ms
Fra min erfaring kan en hurtig test til en nærliggende server vise en helt acceptabel 20-40 ms. Men det tal kan nemt stige til over 200 ms for trafik, der skal krydse et ocean, hvilket kan være en game-changer for din applikations ydeevne.
For at forstå den jargon, du vil støde på, her er en hurtig reference.
Nøglelatensbegreber i Et Overblik
| Begreb | Hvad Det Måler | Hvorfor Det Er Vigtigt |
|---|---|---|
| Latens (Ping) | Den tid det tager for en enkelt datapakke at rejse fra en kilde til en destination og tilbage. Målt i millisekunder (ms). | Dette er den rå måling af forsinkelse. Lav latens er afgørende for realtidsapplikationer som gaming, VoIP og videokonferencer. |
| Round-Trip Time (RTT) | Essentialt det samme som latens, dette er den samlede varighed for et signal at blive sendt plus tiden for at modtage en bekræftelse. | RTT er den mest almindelige og praktiske måde at måle latens fra et enkelt punkt, hvilket gør det til den foretrukne måling for værktøjer som ping. |
| Envejslatens | Den tid det tager for en pakke at rejse fra kilde til destination i én retning. | Giver et mere detaljeret billede, især for asymmetrisk netværk, hvor upload- og downloadveje har forskellige latenser. |
| Jitter | Variation i latens over tid. Det måler inkonsistensen af pakkeankomsttider. | Høj jitter er lige så skadelig som høj latens for streaming af medier og online opkald, hvilket forårsager hakken, buffering og glitches. |
| Båndbredde | Den maksimale mængde data, der kan overføres over en netværksforbindelse i en given tidsperiode. Målt i Mbps eller Gbps. | Ofte forvekslet med hastighed, båndbredde handler om kapacitet. Du kan have høj båndbredde, men stadig lide under høj latens. |
Disse begreber er byggestenene til at forstå ethvert netværksydelsesproblem.
Her bliver det så vigtigt at have tilgængelige, integrerede værktøjer. I stedet for at køre komplekse diagnostiske suite kan moderne browserudvidelser og udviklerværktøjer give dig de indsigter, du har brug for, uden nogensinde at forlade dit workflow. Det handler om at gøre latensmåling til en ubesværet, rutinemæssig del af at bygge og vedligeholde fantastisk software.
Få Dine Hænder Beskidt med Kommandolinje Latensværktøjer
For virkelig at få en fornemmelse af dit netværks ydeevne, skal du åbne terminalen. Kommandolinjen er, hvor du finder de grundlæggende værktøjer, der giver dig rå, ufiltreret data om din forbindelse. Det handler om at se, hvad der virkelig sker med pakkerne, der bevæger sig mellem dig og en destination, og det er det essentielle første skridt for enhver udvikler, der er seriøs omkring at måle latens.
Det klassiske, foretrukne værktøj er ping. Det er smukt enkelt: det sender en lille datapakke (en ICMP echo-anmodning) til en server og venter bare på, at den kommer tilbage. Den enkle rundtur er grundlaget for at beregne Round-Trip Time (RTT) og giver dig en øjeblikkelig sundhedstjek af en forbindelse.
Din Første Latenskontrol med Ping
At køre en ping test kunne ikke være lettere. Tænd for din terminal eller kommandoprompt, skriv ping, og følg det med det domæne, du vil teste.
Som standard vil ping fortsætte for evigt på macOS og Linux, mens Windows kun sender fire pakker og stopper. For enhver reel analyse vil du gerne kontrollere dette. At sende ti eller tyve pakker giver dig et meget mere pålideligt billede af forbindelsens stabilitet end bare et par.
Når det er færdigt, får du et pænt resumé med de afgørende tal:
- Sendte/modtagne pakker: Dette fortæller dig, om der er tabt data undervejs. Selv en lille mængde pakke tab er et stort rødt flag for netværksproblemer.
- Round-trip min/avg/max/mdev: Disse er dine kerne latensstatistikker. Du får den bedste tid (
min), gennemsnittet (avg) og den værste (max).mdev(middelafvigelse) er dit mål for jitter—hvor meget latensen varierer fra en pakke til den næste.
Vær opmærksom på kløften mellem din minimum og maksimum RTT. Hvis den er bred, er din forbindelse ustabil, selvom gennemsnittet ser okay ud. Denne jitter kan være langt mere forstyrrende for realtidsapps som videoopkald eller gaming end en forbindelse, der konsekvent er lidt langsom.
En almindelig fejl er blot at kaste et blik på den gennemsnitlige RTT. Et gennemsnit på 50ms kan virke fint, men hvis din minimum er 20ms og din maksimum er 250ms, vil brugeroplevelsen føles hakkende og upålidelig. Se altid på hele spektret for at forstå jitter.
Følge Sporet med Traceroute og MTR
Så hvad gør du, når ping afslører høj latens eller pakke tab? Dit næste job er at finde ud af hvor problemet er. Det er, hvad traceroute (eller tracert på Windows) er til. Det kortlægger hele stien, dine pakker tager, og viser dig hver enkelt "hop"—hver router—mellem din maskine og den endelige destination.
Hver linje i traceroute output er et hop, og det viser normalt tre separate latensmålinger til det punkt. Dette lader dig præcist identificere, om en specifik router langs stien forårsager en stor forsinkelse eller taber pakker.
Men traceroute er et engangs snapshot. For et mere dynamisk, kontinuerligt kig sværger de fleste netværkseksperter, jeg kender, til MTR (My Traceroute). MTR er som et superladet værktøj, der kombinerer ping og traceroute. Det sender konstant pakker til hver hop på ruten, hvilket giver dig et live, opdaterende billede af latens og pakke tab på hvert enkelt punkt. Dette gør det utrolig effektivt til at fange intermitterende problemer, som en enkelt traceroute sandsynligvis ville gå glip af.
Hvorfor Dit Valg af Værktøj Er Vigtigt
Det værktøj, du vælger, og hvordan du konfigurerer det, kan drastisk ændre dine resultater. Dette gælder især i ultra-hurtige, lav-latens miljøer som cloud datacentre.
Det er faktisk ret øjenåbnende, hvor forskellige tallene kan være. I et detaljeret eksperiment udført af Google Cloud rapporterede en standard ping test et gennemsnitligt RTT på 146 mikrosekunder. Men da de brugte et andet værktøj, der sender transaktioner tilbage-til-tilbage uden pause, faldt RTT til kun 66,59 mikrosekunder—mere end dobbelt så hurtigt!
Dette er et perfekt eksempel på, hvorfor ping nogle gange kan overvurdere latens. Det viser, at forståelse af hvordan et værktøj fungerer er kritisk for at få målinger, du kan stole på.
Find Din Forbindelses Top Hastighed med iperf
Latens er ikke altid hele billedet. Nogle gange skal du vide, hvor meget data din forbindelse faktisk kan skubbe igennem—dens båndbredde. Til det job er det værktøj, du vil have, iperf.
Mens ping måler forsinkelse, handler iperf om gennemstrømning. Det fungerer ved at oprette en klient-server forbindelse og derefter sende så meget data som muligt mellem dem i en fastsat tidsperiode.
For at bruge iperf skal du have to maskiner:
- På den ene maskine kører du
iperfi servermode. Den vil bare sidde der og lytte efter en forbindelse. - På den anden maskine kører du
iperfi klientmode, peger den mod serverens adresse.
Klienten vil oprette forbindelse, og testen vil starte. Outputtet fortæller dig den samlede data, der er overført, og vigtigst af alt, bitraten (din båndbredde) i megabit eller gigabit pr. sekund. Det er den perfekte måde at stresse teste et netværkslink og finde ud af, hvad det virkelig er i stand til.
Måling af Latens fra en Brugsers Perspektiv
Mens kommandolinjeværktøjer giver dig et råt, ufiltreret blik på dit netværk, er den eneste latens, der virkelig betyder noget for en webapplikation, hvad slutbrugeren faktisk oplever. Her skifter vi fokus fra terminalen til selve browseren. Hvad der sker inde i browseren fortæller en meget rigere, mere relevant historie om ydeevne.
Det handler aldrig kun om en enkelt pakkes rundtur. Den latens, en bruger føler, er en kompleks cocktail af DNS-opslag, TCP-håndtryk, TLS-forhandlinger, serverbehandlingstid, og selvfølgelig, den tid det tager at faktisk gengive indholdet på skærmen. Heldigvis kommer moderne browsere pakket med kraftfulde indbyggede værktøjer til at hjælpe os med at dissekere hele denne proces.
Dyk Ned i Browserens Udviklerværktøjer
Hver større browser—Chrome, Firefox, Edge, Safari—kommer udstyret med en suite af udviklerværktøjer. Fanen "Netværk" inden for disse værktøjer er dit kommandocenter for at forstå, hvordan din side indlæses. Den lægger alt ud i et vandfaldsdiagram, som er en visuel opdeling af hver enkelt anmodning, som browseren laver for at gengive en side.
Dette vandfaldsvisning er uvurderlig. Du kan se præcist, hvor lang tid hver ressource tog at downloade, fra det indledende HTML-dokument og CSS-stilark til billeder og API-kald. Mere vigtigt, det opdeler livscyklussen for hver anmodning i distinkte faser:
- DNS-opslag: Den tid det tager at oversætte et domænenavn til en IP-adresse.
- Indledende forbindelse: Den tid, der bruges på at etablere en TCP-forbindelse med serveren.
- SSL/TLS-håndtryk: Den overhead, der kræves for at oprette en sikker forbindelse.
- Time to First Byte (TTFB): Dette er en stor en. Det måler, hvor lang tid browseren ventede, før den modtog det allerede første byte data fra serveren.
- Indholdsdownload: Den tid, der bruges på faktisk at downloade ressourcen selv.
En høj TTFB, for eksempel, er et klassisk tegn på en sløv backend eller server-side behandlingsproblem—noget en simpel ping test aldrig ville afsløre. Ved at analysere dette vandfald kan du hurtigt spotte, hvilke ressourcer der blokerer for gengivelse eller bare tager alt for lang tid at indlæse.
En vigtig læring fra min erfaring er ikke kun at se på den samlede indlæsningstid, men at lede efter de længste søjler i vandfaldet. Et enkelt uoptimeret billede eller en langsom tredjeparts API kan holde hele siden som gidsel, hvilket skaber en dårlig brugeroplevelse, selvom resten af siden er lynhurtig.
Programmatisk Måling med Timing APIs
For mere automatiserede og præcise målinger kan du få adgang til browserens indbyggede JavaScript APIs. Navigation Timing API og Resource Timing API giver dig programmatisk adgang til de samme detaljerede ydeevnedata, du ser i udviklerværktøjerne. Dette er perfekt til at indsamle data om reel brugerovervågning (RUM) for at forstå, hvordan din side præsterer for faktiske besøgende over hele kloden.
Du kan hente disse målinger med blot et par linjer JavaScript, lige i browserens konsol. For at få de centrale ydeevnetiming for den primære sideindlæsning, for eksempel, kan du bruge performance.getEntriesByType('navigation'). Dette returnerer et objekt fyldt med værdifulde tidsstempler.
Fra disse data kan du beregne vitale målinger:
- DNS-opslagstid:
domainLookupEnd - domainLookupStart - TCP-håndtrykstid:
connectEnd - connectStart - Time to First Byte (TTFB):
responseStart - requestStart - Total sideindlæsningstid:
loadEventEnd - startTime
Denne tilgang giver dig mulighed for at opbygge tilpassede dashboards eller sende præstationsdata til dine analyseværktøjer, hvilket giver dig en kontinuerlig puls på din applikations præstation i den virkelige verden. I webudvikling er optimering af billeder en almindelig måde at forbedre disse målinger på; for dem, der er interesserede, har vi en nyttig guide til at vælge det bedste billedeformat til din hjemmeside.
Strømlining af Tjek med Integrerede Værktøjer
At hoppe mellem terminalen, browserens udviklerværktøjer og tilpassede scripts kan hurtigt blive trættende. Her kan integrerede browserudvidelser virkelig glatte dit workflow ved at forene disse tjek. For eksempel inkluderer ShiftShift Extensions pakken et indbygget Speed Test værktøj, som du kan åbne med det samme fra enhver fane.
Dette giver dig en hurtig, privatlivsorienteret måde at måle din forbindelses downloadhastighed, uploadhastighed og latenstid uden at skulle navigere til en separat hjemmeside eller åbne en terminal. Fordi det er en del af et større værktøjssæt, kan du køre en hastighedstest, formatere et JSON-svar og tjekke en cookie alt sammen fra den samme samlede kommandopalette. Denne form for integration gør præcisionskontroller til en naturlig, friktionsfri del af den daglige udviklingsrutine.
Sådan Designer du en Latenstest, der Rent Faktisk Fortæller dig Noget
Enhver kan sende en ping kommando og få et tal tilbage. Men hvis du vil have data, du rent faktisk kan stole på—data der hjælper dig med at træffe reelle beslutninger—skal du være mere bevidst. En enkelt, isoleret måling er blot et øjebliksbillede i tiden. For virkelig at forstå dit netværks adfærd, skal du tænke som en detektiv, overveje hvor du tester fra, hvor ofte du tester, og hvad du egentlig leder efter.
En veludformet test omdanner rå tal til handlingsorienterede indsigter. En dårligt designet test? Det er bare støj.
Diagrammet nedenfor nedbryder alle de små forsinkelser, der summerer sig til, hvad en bruger føler, når de indlæser en webside. Det er en god påmindelse om, at en simpel netværksping ikke engang begynder at fortælle hele historien.
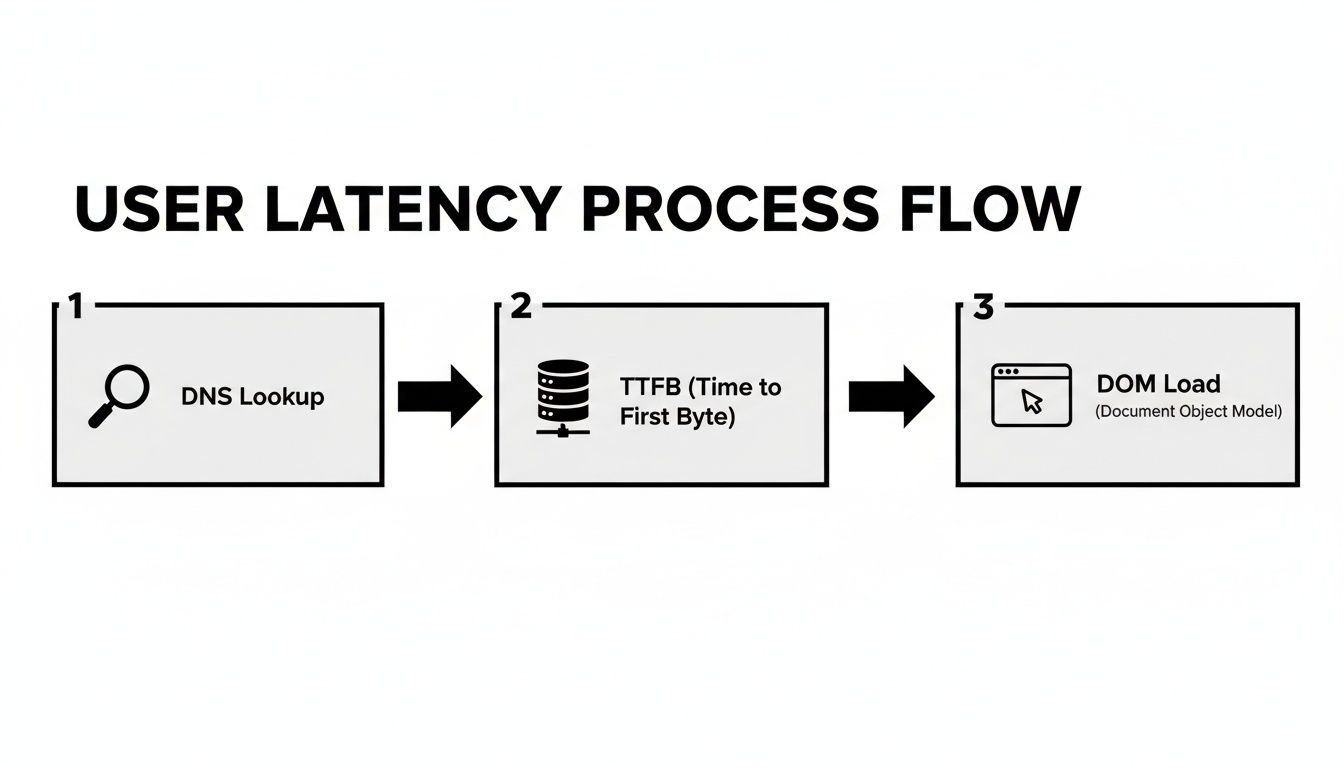
Som du kan se, bidrager flere trin fra den indledende DNS-opslag til den endelige rendering til den samlede ventetid.
Valg af Dine Test Endepunkter
Den første regel for pålidelig testning er, at geografi betyder noget. En test fra dit kontor i New York til en server nede ad vejen i New Jersey fortæller dig absolut ingenting om oplevelsen for dine kunder i Tokyo. For at få et realistisk billede, skal du teste fra forskellige steder, der rent faktisk afspejler din brugerbase.
Din liste over endepunkter bør dække et par nøgleområder:
- Dine Største Brugerhubs: Hvor bor de fleste af dine kunder? Test derfra.
- Tværkontinentale Stier: Se hvad der sker, når data skal krydse et hav. Test mellem Europa og Nordamerika, eller Asien og USA, for at forstå langdistancepræstation.
- Dine Cloud-regioner: Hvis du er på AWS, Azure eller GCP, test forbindelsen til og mellem de specifikke datacenterregioner, du er afhængig af.
At sprede dine tests ud på denne måde skaber et meget mere præcist kort over global præstation. Det hjælper dig med at opdage regionsspecifikke flaskehalse, som du ellers ville gå glip af. Dette er også et godt tidspunkt at dobbelttjekke din domæneopsætning; du kan finde nyttige tips om hvordan man tjekker domænetilgængelighed og relaterede konfigurationer for at sikre, at alt er i orden.
At Finde den Rette Testrytme
Netværksforhold er konstant i forandring. De ændrer sig i løbet af dagen, ugen og endda minuttet. En test udført kl. 3 om natten på en tirsdag kan se fantastisk ud, men det resultat er ubrugeligt, hvis din spidsbelastning rammer kl. 14 på en fredag, når alle er online.
For at få en sand baseline, skal du teste konsekvent over tid. Variér det:
- Kør tests i spidsbelastningsperioder.
- Planlæg nogle til natlige vedligeholdelsesvinduer.
- Glem ikke weekenderne, hvor trafikmønstre kan være helt forskellige.
Ved at tage prøver af data gentagne gange kan du udjævne de tilfældige toppe og dyk. Dette er, hvordan du opdager tilbagevendende problemer, som netværket bliver overbelastet hver hverdag efter frokost.
Glem ikke om Jitter
Gennemsnitlig latenstid er et solidt udgangspunkt, men det skjuler ofte et mere ondsindet problem: jitter. Jitter er simpelthen variationen i din latenstid over tid. Tænk over det—en stabil forbindelse med en forudsigelig 80ms forsinkelse er ofte meget bedre for realtidsapps end en, der i gennemsnit har 50ms, men svinger vildt mellem 10ms og 200ms.
Jitter er den stille dræber af brugeroplevelsen for alt, der er realtid, som VoIP-opkald, videokonferencer eller online gaming. Høj jitter er det, der forårsager hakket lyd, frosne videoer og frustrerende lag spikes, der får en applikation til at føles helt brudt, selv når den gennemsnitlige latenstid ser god ud på papiret.
At forstå jitter betyder at se ud over gennemsnittet. Det er den usungne skurk, fordi det afslører, hvorfor gennemsnit alene kan være så misvisende. For eksempel viser data fra Pandora FMS, at jitter over 30ms kan øge pakktab i gaming til 15%—nok til at gøre et spil uspilleligt. At måle standardafvigelsen af dine latenstests er det første skridt til at sætte et tal på den ustabilitet.
Checklist til Design af Latenstest
For at samle alt dette, her er en hurtig tjekliste til at guide dig. At følge disse trin vil hjælpe med at sikre, at de data, du indsamler, er både nøjagtige og virkelig nyttige.
| Tjeklistepunkt | Hvorfor det er vigtigt | Handlingsorienteret Tip |
|---|---|---|
| Definer Klare Mål | Du kan ikke måle, hvad du ikke definerer. Er du i gang med at fejlfinde et specifikt problem eller etablere en baseline? | Skriv dit mål ned, før du starter. "Diagnostiser forsinkelse for brugere i Sydøstasien" er et bedre mål end "tjek latenstid." |
| Vælg Forskellige Endepunkter | En enkelt sti repræsenterer ikke din globale brugeroplevelse. | Vælg 3-5 lokationer: en lokal, en på et andet kontinent, og et par i dine nøglebruger-markeder. |
| Etabler en Rytme | Engangstests overser tidsbaserede mønstre som spidsbelastningsbelastning. | Planlæg tests til at køre automatisk hver time i en uge for at fange en fuld cyklus af netværksadfærd. |
| Mål Jitter | Gennemsnit skjuler den uregelmæssige præstation, der ødelægger realtidsapplikationer. | Se ikke kun på den gennemsnitlige RTT. Beregn standardafvigelsen eller brug et værktøj som mtr, der viser min/maks/gennemsnit latenstid. |
| Brug de Rette Værktøjer | ping er godt til en hurtig kontrol, men værktøjer som mtr eller iperf giver dybere indsigter. |
Til webpræstation, brug browserens udviklerværktøjer. Til rå netværksveje er mtr et godt valg. |
| Dokumenter Alt | Du vil glemme "hvorfor" bag din test seks måneder fra nu. | Hold en simpel log: dato, tid, endepunkter, anvendt værktøj, og en kort note om hvad du observerede. |
Ved at være metodisk bevæger du dig fra blot at måle latenstid til virkelig at forstå den. Denne eftertænksomme tilgang er det, der adskiller et tilfældigt tal fra en pålidelig præstationsindikator.
At Give Mening til Tallene (og Hvad man Skal Undgå)
Okay, du har kørt dine tests og har en bunke data. Her begynder det virkelige arbejde—at oversætte disse rå tal til noget, der rent faktisk betyder noget. Dataene fortæller dig en historie om dit netværks sundhed; du skal bare lære at læse det.
For eksempel er et pludseligt spike i Round-Trip Time (RTT) på en traceroute et klassisk spor. Hvis latenstiden springer ved hop nummer tre og forbliver høj hele vejen til slutningen, har du sandsynligvis fundet dit problem: det er den tredje router eller forbindelsen lige efter den. Men vær forsigtig. Hvis kun det enkelte hop viser høj latenstid, og den endelige destination stadig er hurtig, kan det bare være en router, der er konfigureret til at nedprioritere den nøjagtige type trafik, din test bruger. Det er en almindelig falsk alarm, der kan sende dig ned ad en kaninhul.
Afkodning af Jitter og Pakktab
At se forbi simpel RTT er, hvor du finder de mest kritiske indsigter. Høj jitter, som blot er et fancy ord for inkonsekvent latenstid, kan være langt mere forstyrrende end latenstid, der er konsekvent høj. Dette gælder især for alt, der er realtid.
Hvis dine resultater viser en gennemsnitlig RTT på 40ms, men minimum var 10ms og maksimum var 150ms, er din forbindelse ustabil. Den massive variation er præcis det, der forårsager irriterende hak i videoopkald og rasende lag spikes i online spil.
Pakktab er et endnu større rødt flag. Selv 1% pakktab kan fuldstændig lamme TCP-baserede applikationer, hvilket tvinger dem til konstant at gensende data og bremse alt til en sneglefart. Når du ser på dine testresultater, skal enhver reel forskel mellem sendte pakker og modtagne pakker undersøges straks.
En af de største fejl, jeg ser folk lave, er at antage, at en enkelt test fortæller hele historien. Netværksforhold ændrer sig konstant. En test udført kl. 3 om natten vil se helt anderledes ud end en kl. 15 i spidsbelastningsperioder. Den eneste måde at få en sand præstationsbaseline på er gennem konsekvent, gentagen testning.
For at komme foran problemer er det værd at se på dedikerede værktøjer til netværkspræstationsovervågning. Dette skifter din tilgang fra hektisk at reparere ting, når de går i stykker, til proaktivt at holde dit netværk sundt.
De Mest Almindelige Målefejl
Selv med de bedste værktøjer i verden kan et par enkle fejl gøre dine resultater helt ubrugelige. At undgå disse almindelige faldgruber er ikke til forhandling, hvis du vil have data, du rent faktisk kan stole på.
- Testning Over Wi-Fi: Seriøst, gør det ikke. Trådløse forbindelser er notorisk lunefulde, tilbøjelige til interferens fra alt fra mikrobølgeovne til din nabos router. Til enhver seriøs latenstest, tilslut med et Ethernet-kabel. Det er den eneste måde at få en stabil, pålidelig baseline.
- At Glemme VPN Overhead: VPN'er er gode til sikkerhed, men de tilføjer et ekstra stop og kryptering til din trafiks rejse. Dette vil altid øge latenstiden. Hvis du prøver at diagnosticere en brugers langsomme forbindelse, bør et af dine første spørgsmål være, "Er du på VPN?" Testning med og uden det vil vise dig præcis, hvor meget forsinkelse det tilføjer.
- At Ignorere Lokal Netværksbelastning: Dine testresultater vil være skæve, hvis en anden på dit netværk optager al båndbredden. Hvis en kollega streamer 4K-video eller downloader massive filer, mens du tester, vil dine latenstal være oppustede, og du ender med at jagte et problem, der ikke eksisterer.
En anden subtil, men kritisk faktor er det værktøj, du vælger. Som vi har dækket, måler forskellige værktøjer latenstid på forskellige måder. Vær altid konsekvent med de værktøjer, du bruger til sammenligning, og sørg for, at du forstår, hvad hver enkelt faktisk måler—uanset om det er en simpel ICMP-echo eller en kompleks, applikationsniveau anmodning. Og husk, at præstation kan påvirkes af mange lag; for eksempel, hvis du dykker ned i webpræstation, kan vores guide til en Cookie Editor Chrome Extension vise, hvordan klient-side elementer spiller en rolle.
Ved at fortolke dine resultater med den rette kontekst og undgå disse almindelige fejl, vil du bevæge dig ud over blot at indsamle tal. Du vil begynde at forstå hvorfor bag dit netværks præstation, og det er nøglen til at bygge hurtigere, mere pålidelige systemer.
Almindelige Spørgsmål om Netværkslatenstid
Selv med de rigtige værktøjer ser et par almindelige spørgsmål altid ud til at dukke op, når du begynder at grave i netværkslatenstid. Lad os gennemgå nogle af de mest hyppige, jeg hører, for at hjælpe dig med at give mening til dine resultater.
Hvad er Faktisk et “Godt” Latenstal?
Dette er det klassiske "det afhænger" spørgsmål, men vi kan bestemt sætte nogle solide benchmarks. Et "godt" latenstal er helt relativt til, hvad du prøver at opnå.
- Casual Web Browsing: For de fleste af os vil alt under 100ms RTT føles helt fint. Sider indlæses hurtigt, og du vil ikke bemærke nogen reel forsinkelse.
- Competitive Online Gaming: Her tæller hver millisekund. Seriøse gamere og højfrekvente handlende søger latenstid godt under 20ms. Det er forskellen mellem at vinde og tabe.
- Videoopkald & VoIP: Her er konsistens konge. Du har brug for en stabil latenstid under 150ms og lav jitter (mindre end 30ms) for at undgå den hakkede, ude af synk følelse eller, værre, tabte opkald.
Som en tommelfingerregel ville de fleste netværksproffer, jeg kender, klassificere alt under 50ms som lav latenstid. Fra 50-150ms er moderat, og når du kryber over 150ms, vil du begynde at føle draget på de fleste interaktive applikationer.
Hvorfor Matcher Mine Ping- og Browserhastighedstestresultater Aldrig?
Dette er et fantastisk spørgsmål og et super almindeligt forvirringspunkt. Det sker, fordi en kommandolinje ping og en browserbaseret hastighedstest grundlæggende er forskellige værktøjer, der måler forskellige ting.
For det første taler de næsten helt sikkert med forskellige servere. Når du pinger et domæne, rammer du et specifikt mål. En webhastighedstest er derimod designet til at finde en geografisk tæt server fra sit eget netværk for at give dig det bedste resultat.
Protokollerne er også helt forskellige. Ping bruger en meget let protokol kaldet ICMP. De fleste browser tests kører over TCP, som kræver en hel opsætningsproces (den "trevejs håndtryk") blot for at etablere en forbindelse. Den indledende frem og tilbage tilføjer lidt tid, før den rigtige test overhovedet begynder.
Endelig inkluderer browser tests ofte mere end blot ren netværksrejsetid. Deres "latenstid" tal kan inkludere serverbehandlingstid eller endda små forsinkelser inden i din browser selv, hvilket kan oppuste det endelige tal sammenlignet med en rå ICMP ping.
Hvordan Kan Jeg Faktisk Sænke Min Netværkslatenstid?
At reducere latenstid handler om at finde og eliminere flaskehalse, uanset om de er i dit kontor eller på internettet.
Det første sted at kigge er dit umiddelbare miljø. Den mest effektive ændring, du kan foretage, er at skifte fra Wi-Fi til en kablet Ethernet-forbindelse. Det er en game-changer for stabilitet og hastighed. Hvis du er nødt til at bruge Wi-Fi, så kom tættere på din router og hop på 5GHz-båndet, hvis du kan - det er normalt mindre overfyldt.
Ser man ud over dit lokale netværk, kan en DNS-ændring nogle gange hjælpe. At bruge en hurtigere DNS-server kan reducere millisekunder fra den indledende forbindelsestid, når du søger efter en hjemmeside.
Hvis du prøver at forbedre adgangen til en tjeneste, du kontrollerer, er et Content Delivery Network (CDN) svaret. Det fungerer ved at placere kopier af dit indhold fysisk tættere på dine brugere. Og hvis du bruger en VPN, så prøv at slukke for den. Det ekstra hop og krypteringslag tilføjer næsten altid latenstid.
Jeg har set virksomheders VPN'er tilføje så meget som 70ms til en rundrejsetid. Det kan forvandle en god forbindelse til en frustrerende langsom en. Test altid med og uden din VPN for at se, hvilken slags præstationsnedgang du faktisk oplever.
Hvad er den reelle forskel mellem latenstid og båndbredde?
At få dette rigtigt er grundlæggende for at forstå netværksydelse. Det er let at forveksle dem, men de måler to meget forskellige ting.
Her er analogien, jeg altid bruger: tænk på det som en motorvej.
- Båndbredde er, hvor mange baner motorvejen har. Flere baner betyder, at flere biler (data) kan rejse på samme tid.
- Latenstid er fartgrænsen. Den dikterer, hvor hurtigt en enkelt bil (et datapakke) kan komme fra A til B.
Du kunne have en massiv, ti-bane motorvej (enorm båndbredde) med en fartgrænse på 20 mph (høj latenstid). Du kunne flytte en masse data til sidst, men realtids ting som et videoopkald ville være smertefuldt langsomt. På den anden side føles en forbindelse med meget lav latenstid utrolig hurtig og responsiv, selvom dens båndbredde ikke er enorm. Du har virkelig brug for en god balance mellem begge for en fantastisk oplevelse.
Klar til at gøre præstationstestning til en sømløs del af din daglige arbejdsgang? ShiftShift Extensions pakken giver dig et kraftfuldt Speed Test, JSON formatter og dusinvis af andre udvikler værktøjer lige inde i din browser, tilgængelige med en enkelt kommando. Stop med at jonglere med faner og begynd at arbejde smartere. Download ShiftShift Extensions gratis og supercharge din produktivitet i dag.