Comment mesurer la latence réseau : le guide pratique d'un développeur
Découvrez comment mesurer la latence réseau avec ce guide complet. Nous couvrons des outils essentiels tels que ping et traceroute ainsi que des techniques de test basées sur le navigateur.

Extensions recommandées
Vous souhaitez mesurer la latence réseau ? Vous pouvez commencer par des outils de ligne de commande simples et intégrés comme ping et traceroute pour obtenir une lecture rapide du Temps de Trajet Aller-Retour (RTT). Ou, vous pouvez ouvrir les outils de développement de votre navigateur pour voir comment les délais affectent ce que vos utilisateurs vivent réellement.
Ces méthodes vous donnent un aperçu rapide et utile du temps qu'il faut à un paquet de données pour voyager d'une source, atteindre une destination et revenir.
Pourquoi Mesurer la Latence Est Non Négociable
Avant de parler du « comment », discutons du « pourquoi ». Pour les développeurs et les ingénieurs réseau, la latence n'est pas juste un chiffre sur un écran ; c'est la main invisible qui façonne l'ensemble de l'expérience utilisateur. Dans les applications d'aujourd'hui, les millisecondes sont tout. Même un léger retard peut faire la différence entre un service qui semble instantané et un qui semble défaillant.
Pensez aux conséquences dans le monde réel :
- Réactivité de l'API : Un seul appel API lent peut créer un effet domino, retardant tout, du chargement du profil d'un utilisateur au traitement d'un paiement critique.
- Flux de Données en Temps Réel : Pour les jeux en ligne, la vidéo en direct ou le trading financier, une latence faible et constante est la base absolue. Sans cela, ces applications ne fonctionnent tout simplement pas.
- Rétention des Utilisateurs : Il existe un lien direct entre les sites et applications à chargement lent et des taux de rebond plus élevés ainsi que des paniers abandonnés. Cela impacte durement le chiffre d'affaires.
Distinction des Concepts Clés de Latence
Pour mesurer la latence réseau avec précision, vous devez savoir ce que vous regardez. Les deux concepts les plus fondamentaux sont le Temps de Trajet Aller-Retour (RTT) et la latence unidirectionnelle.
RTT est le temps total qu'il faut à un signal pour aller du point A au point B et revenir. C'est la métrique la plus courante que vous verrez car elle est simple à mesurer : vous n'avez besoin d'accéder qu'à une extrémité de la connexion.
La latence unidirectionnelle, comme son nom l'indique, mesure le temps qu'il faut pour que les données voyagent dans une seule direction. C'est une mesure beaucoup plus délicate à obtenir car elle nécessite des horloges parfaitement synchronisées aux deux extrémités. Cependant, c'est un indicateur beaucoup plus précis pour les connexions asymétriques, où vos chemins de téléchargement et d'envoi se comportent très différemment.
L'importance de tout cela devient claire lorsque vous effectuez des tests de performance de charge, où la théorie rencontre la réalité et où les goulets d'étranglement sont exposés.
Pour donner quelques chiffres, les experts en surveillance réseau classifient généralement la latence comme suit :
- Latence faible : Moins de 50 millisecondes
- Latence modérée : 50-150 ms
- Latence élevée : Plus de 150 ms
De mon expérience, un test rapide vers un serveur proche peut montrer une latence parfaitement acceptable de 20-40 ms. Mais ce chiffre peut facilement grimper à plus de 200 ms pour un trafic qui doit traverser un océan, ce qui peut changer la donne pour la performance de votre application.
Pour comprendre le jargon que vous rencontrerez, voici une référence rapide.
Concepts Clés de Latence en Un Coup d'Œil
| Concept | Ce Qu'il Mesure | Pourquoi Cela Compte |
|---|---|---|
| Latence (Ping) | Le temps qu'il faut à un paquet de données pour voyager d'une source à une destination et revenir. Mesuré en millisecondes (ms). | C'est la mesure brute du retard. Une faible latence est cruciale pour les applications en temps réel comme les jeux, la VoIP et la vidéoconférence. |
| Temps de Trajet Aller-Retour (RTT) | Essentiellement le même que la latence, c'est la durée totale pour qu'un signal soit envoyé plus le temps nécessaire pour recevoir un accusé de réception. | Le RTT est la manière la plus courante et pratique de mesurer la latence depuis un point unique, ce qui en fait la métrique de référence pour des outils comme ping. |
| Latence Unidirectionnelle | Le temps qu'il faut à un paquet pour voyager de la source à la destination dans une seule direction. | Fournit une vue plus granulaire, surtout pour les réseaux asymétriques où les chemins d'envoi et de téléchargement ont des latences différentes. |
| Jitter | La variation de la latence dans le temps. Elle mesure l'incohérence des temps d'arrivée des paquets. | Un jitter élevé est tout aussi mauvais qu'une latence élevée pour le streaming de médias et les appels en ligne, provoquant des saccades, des mises en mémoire tampon et des glitches. |
| Largeur de Bande | La quantité maximale de données pouvant être transmises sur une connexion réseau dans un temps donné. Mesurée en Mbps ou Gbps. | Souvent confondue avec la vitesse, la largeur de bande concerne la capacité. Vous pouvez avoir une large bande passante mais souffrir d'une latence élevée. |
Ces concepts sont les éléments de base pour comprendre tout problème de performance réseau.
C'est là que l'accès à des outils intégrés et accessibles devient si important. Au lieu d'exécuter des suites de diagnostic complexes, les extensions de navigateur modernes et les outils de développement peuvent vous donner les informations dont vous avez besoin sans jamais quitter votre flux de travail. Il s'agit de rendre la mesure de la latence une partie sans effort et routinière de la création et de la maintenance d'un excellent logiciel.
Mettre les Mains à la Pâte avec des Outils de Latence en Ligne de Commande
Pour vraiment ressentir la performance de votre réseau, vous devez ouvrir le terminal. La ligne de commande est l'endroit où vous trouverez les outils fondamentaux qui vous donnent des données brutes et non filtrées sur votre connexion. Il s'agit de voir ce qui se passe réellement avec les paquets se déplaçant entre vous et une destination, et c'est la première étape essentielle pour tout développeur sérieux au sujet de la mesure de la latence.
L'outil classique et incontournable est ping. C'est d'une simplicité magnifique : il envoie un petit paquet de données (une requête d'écho ICMP) à un serveur et attend simplement qu'il revienne. Ce simple aller-retour est la base pour calculer le Temps de Trajet Aller-Retour (RTT) et vous donne un contrôle instantané sur la santé d'une connexion.
Votre Premier Contrôle de Latence avec Ping
Exécuter un test ping ne pourrait pas être plus simple. Ouvrez votre terminal ou votre invite de commande, tapez ping, et suivez-le du domaine que vous souhaitez tester.
Par défaut, ping continuera indéfiniment sur macOS et Linux, tandis que Windows envoie seulement quatre paquets et s'arrête. Pour toute analyse réelle, vous voudrez contrôler cela. Envoyer dix ou vingt paquets vous donne une image beaucoup plus fiable de la stabilité de la connexion que quelques-uns seulement.
Une fois terminé, vous obtiendrez un résumé soigné avec les chiffres cruciaux :
- Paquets Transmis/Reçus : Cela vous indique si des données ont été perdues en cours de route. Même une petite quantité de perte de paquets est un signal d'alarme majeur pour des problèmes réseau.
- Round-trip min/avg/max/mdev : Ce sont vos statistiques de latence de base. Vous obtenez le meilleur temps (
min), la moyenne (avg), et le pire cas (max). Lemdev(écart moyen) est votre mesure de jitter—combien la latence varie d'un paquet à l'autre.
Faites attention à l'écart entre votre RTT minimum et maximum. S'il est large, votre connexion est instable, même si la moyenne semble correcte. Ce jitter peut être beaucoup plus perturbateur pour des applications en temps réel comme les appels vidéo ou les jeux qu'une connexion qui est constamment un peu lente.
Une erreur courante est de simplement jeter un coup d'œil à la moyenne du RTT. Une moyenne de 50 ms peut sembler correcte, mais si votre minimum est de 20 ms et votre maximum est de 250 ms, l'expérience utilisateur semblera saccadée et peu fiable. Regardez toujours l'ensemble de la plage pour comprendre le jitter.
Suivre la Piste avec Traceroute et MTR
Alors, que faites-vous lorsque ping révèle une latence élevée ou une perte de paquets ? Votre prochaine tâche est de déterminer où se trouve le problème. C'est ce à quoi sert traceroute (ou tracert sur Windows). Il cartographie l'ensemble du chemin que prennent vos paquets, vous montrant chaque « saut »—chaque routeur—entre votre machine et la destination finale.
Chaque ligne dans la sortie de traceroute est un saut, et elle montre généralement trois mesures de latence distinctes jusqu'à ce point. Cela vous permet de déterminer si un routeur spécifique le long du chemin cause un ralentissement majeur ou perd des paquets.
Mais traceroute est un instantané unique. Pour une vue plus dynamique et continue, la plupart des professionnels du réseau que je connais jurent par MTR (My Traceroute). MTR est comme un outil suralimenté qui combine ping et traceroute. Il envoie constamment des paquets à chaque saut sur le chemin, vous donnant une vue en direct et mise à jour de la latence et de la perte de paquets à chaque point. Cela le rend incroyablement efficace pour attraper des problèmes intermittents qu'un seul traceroute manquerait probablement.
Pourquoi Votre Choix d'Outil Compte
L'outil que vous choisissez et la manière dont vous le configurez peuvent changer radicalement vos résultats. Cela est particulièrement vrai dans des environnements ultra-rapides et à faible latence comme les centres de données cloud.
C'est en fait assez révélateur de voir à quel point les chiffres peuvent être différents. Dans une expérience détaillée réalisée par Google Cloud, un test ping standard a rapporté un RTT moyen de 146 microsecondes. Mais lorsqu'ils ont utilisé un autre outil qui envoie des transactions consécutivement sans pause, le RTT est tombé à seulement 66,59 microsecondes—plus de deux fois plus rapide !
C'est un exemple parfait de pourquoi ping peut parfois surestimer la latence. Cela montre que comprendre comment un outil fonctionne est essentiel pour obtenir des mesures fiables.
Trouver la Vitesse Maximale de Votre Connexion avec iperf
La latence n'est pas toujours l'ensemble du tableau. Parfois, vous devez connaître la quantité maximale de données que votre connexion peut réellement transmettre—sa largeur de bande. Pour cela, l'outil que vous souhaitez est iperf.
Tandis que ping mesure le retard, iperf est entièrement axé sur le débit. Il fonctionne en établissant une connexion client-serveur et en envoyant autant de données que possible entre eux pendant une période déterminée.
Pour utiliser iperf, vous aurez besoin de deux machines :
- Sur une machine, vous exécutez
iperfen mode serveur. Il restera là et écoutera une connexion. - Sur l'autre machine, vous exécutez
iperfen mode client, en le pointant vers l'adresse du serveur.
Le client se connectera et le test commencera. La sortie vous indique le total des données transférées et, surtout, le débit (votre largeur de bande) en mégabits ou gigabits par seconde. C'est le moyen parfait de tester la résistance d'un lien réseau et de découvrir ce qu'il est réellement capable de faire.
Mesurer la Latence du Point de Vue de l'Utilisateur
Bien que les outils en ligne de commande vous donnent un aperçu brut et non filtré de votre réseau, la seule latence qui compte vraiment pour une application web est celle que l'utilisateur final ressent réellement. C'est ici que nous déplaçons notre attention du terminal vers le navigateur lui-même. Ce qui se passe à l'intérieur du navigateur raconte une histoire beaucoup plus riche et pertinente sur la performance.
Il ne s'agit jamais simplement d'un aller-retour d'un seul paquet. La latence qu'un utilisateur ressent est un cocktail complexe de recherches DNS, de négociations TCP, de négociations TLS, de temps de traitement du serveur, et bien sûr, du temps qu'il faut pour réellement rendre le contenu à l'écran. Heureusement, les navigateurs modernes sont équipés d'outils puissants intégrés pour nous aider à disséquer tout ce processus.
Plongée dans les Outils de Développement du Navigateur
Chaque navigateur majeur—Chrome, Firefox, Edge, Safari—est équipé d'une suite d'outils de développement. L'onglet « Réseau » dans ces outils est votre centre de commande pour comprendre comment votre site se charge. Il présente tout sous forme de graphique en cascade, qui est une décomposition visuelle de chaque requête que le navigateur effectue pour rendre une page.
Cette vue en cascade est inestimable. Vous pouvez voir précisément combien de temps chaque élément a mis à télécharger, du document HTML initial et des feuilles de style CSS aux images et aux appels API. Plus important encore, elle décompose le cycle de vie de chaque requête en phases distinctes :
- Recherche DNS : Le temps qu'il faut pour résoudre un nom de domaine en une adresse IP.
- Connexion Initiale : Le temps passé à établir une connexion TCP avec le serveur.
- Handshake SSL/TLS : Le surcoût nécessaire pour établir une connexion sécurisée.
- Temps jusqu'au Premier Octet (TTFB) : C'est un point crucial. Il mesure combien de temps le navigateur a attendu avant de recevoir le tout premier octet de données du serveur.
- Téléchargement de Contenu : Le temps passé à télécharger réellement la ressource elle-même.
Un TTFB élevé, par exemple, est un signe classique d'un backend lent ou d'un problème de traitement côté serveur—quelque chose qu'un simple test ping ne découvrirait jamais. En analysant cette cascade, vous pouvez rapidement repérer quelles ressources bloquent le rendu ou prennent tout simplement trop de temps à charger.
Un point clé de mon expérience est de ne pas se contenter de regarder le temps de chargement total, mais de rechercher les barres les plus longues dans la cascade. Une seule image non optimisée ou une API tierce lente peut retenir toute la page en otage, créant une mauvaise expérience utilisateur même si le reste du site est ultra-rapide.
Mesure Programmatique avec les APIs de Timing
Pour des mesures plus automatisées et précises, vous pouvez exploiter les APIs JavaScript intégrées du navigateur. L'API de Timing de Navigation et l'API de Timing des Ressources vous donnent un accès programmatique aux mêmes données de performance détaillées que vous voyez dans les outils de développement. Cela est parfait pour collecter des données de surveillance des utilisateurs réels (RUM) afin de comprendre comment votre site se comporte pour les visiteurs réels à travers le monde.
Vous pouvez récupérer ces métriques avec juste quelques lignes de JavaScript, directement dans la console du navigateur. Pour obtenir les temps de performance principaux pour le chargement de la page principale, par exemple, vous pouvez utiliser performance.getEntriesByType('navigation'). Cela renvoie un objet rempli de timestamps précieux.
À partir de ces données, vous pouvez calculer des métriques vitales :
- Temps de Recherche DNS :
domainLookupEnd - domainLookupStart - Temps de Handshake TCP :
connectEnd - connectStart - Temps jusqu'au Premier Octet (TTFB) :
responseStart - requestStart - Temps Total de Chargement de la Page :
loadEventEnd - startTime
Cette approche vous permet de créer des tableaux de bord personnalisés ou d'envoyer des données de performance à vos outils d'analyse, vous offrant ainsi un aperçu continu des performances réelles de votre application. Dans le développement web, l'optimisation des images est un moyen courant d'améliorer ces métriques ; pour ceux qui sont intéressés, nous avons un guide utile sur le choix du meilleur format d'image pour votre site web.
Rationaliser les vérifications avec des outils intégrés
Passer d'un terminal à des outils de développement de navigateur et à des scripts personnalisés peut vite devenir lassant. C'est là que les extensions de navigateur intégrées peuvent vraiment fluidifier votre flux de travail en unifiant ces vérifications. Par exemple, la suite ShiftShift Extensions comprend un outil Speed Test intégré que vous pouvez ouvrir instantanément depuis n'importe quel onglet.
Cela vous offre un moyen rapide et axé sur la confidentialité de mesurer la vitesse de téléchargement, la vitesse de téléversement et la latence de votre connexion sans avoir à naviguer vers un site web séparé ou à ouvrir un terminal. Étant donné qu'il fait partie d'un ensemble d'outils plus large, vous pouvez effectuer un test de vitesse, formater une réponse JSON et vérifier un cookie, le tout depuis la même palette de commandes unifiée. Ce type d'intégration rend les vérifications de performance une partie naturelle et sans friction du quotidien du développement.
Comment concevoir un test de latence qui vous informe réellement
Tout le monde peut lancer une commande ping et obtenir un chiffre. Mais si vous voulez des données auxquelles vous pouvez réellement faire confiance—des données qui vous aident à prendre de vraies décisions—vous devez être plus délibéré. Une seule mesure isolée n'est qu'un instantané dans le temps. Pour vraiment comprendre le comportement de votre réseau, vous devez penser comme un détective, en considérant d'où vous testez, à quelle fréquence vous testez et ce que vous recherchez réellement.
Un test bien conçu transforme des chiffres bruts en informations exploitables. Un test mal conçu ? Ce n'est que du bruit.
Le diagramme ci-dessous décompose tous les petits délais qui s'additionnent à ce qu'un utilisateur ressent lorsqu'il charge une page web. C'est un excellent rappel qu'un simple ping réseau ne commence même pas à raconter toute l'histoire.
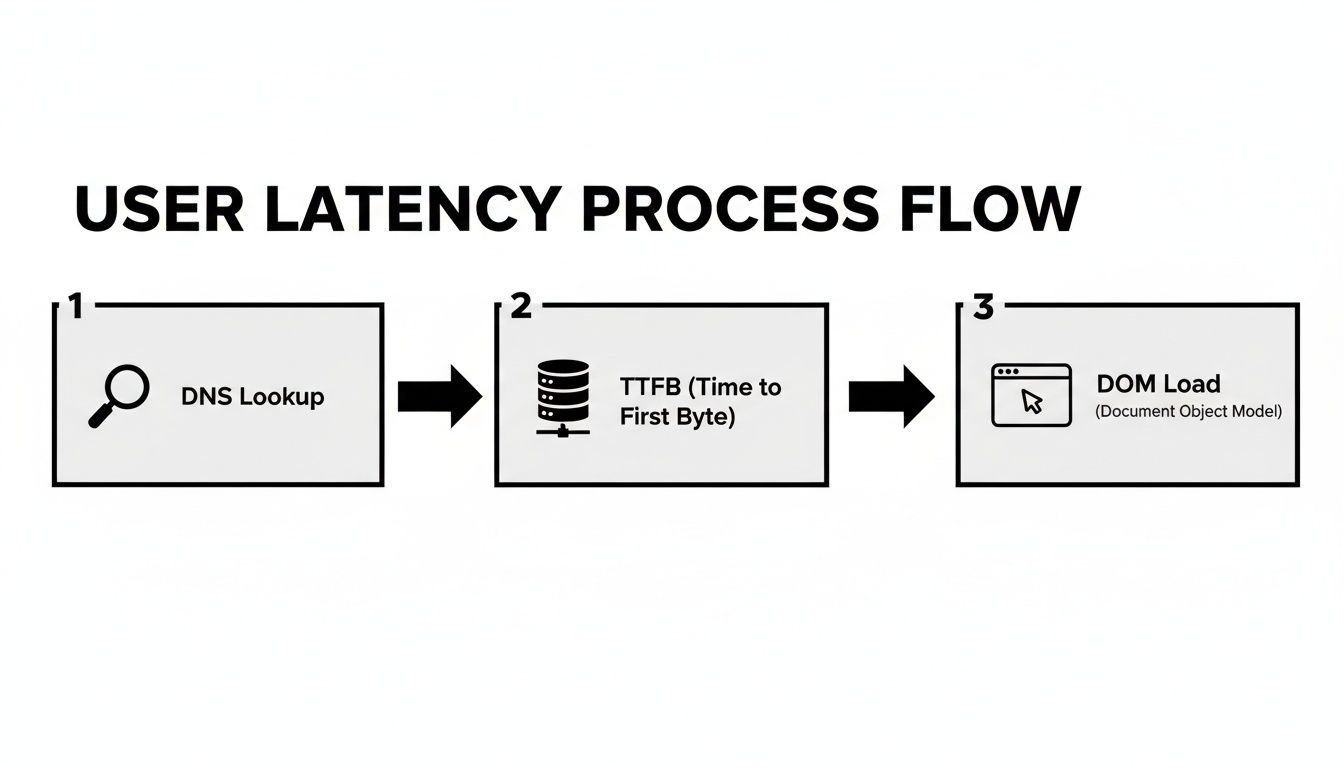
Comme vous pouvez le voir, depuis la recherche DNS initiale jusqu'au rendu final, plusieurs étapes contribuent au temps d'attente total.
Choisir vos points de test
La première règle d'un test fiable est que la géographie compte. Un test depuis votre bureau à New York vers un serveur à proximité dans le New Jersey ne vous dit absolument rien sur l'expérience de vos clients à Tokyo. Pour obtenir une image réaliste, vous devez tester depuis des emplacements divers qui reflètent réellement votre base d'utilisateurs.
Votre liste de points de terminaison devrait couvrir quelques domaines clés :
- Vos plus grands hubs utilisateurs : Où vivent la plupart de vos clients ? Testez depuis là.
- Chemins transcontinentaux : Voyez ce qui se passe lorsque les données doivent traverser un océan. Testez entre l'Europe et l'Amérique du Nord, ou l'Asie et les États-Unis, pour comprendre la performance sur de longues distances.
- Vos régions cloud : Si vous êtes sur AWS, Azure ou GCP, testez la connectivité vers et entre les régions spécifiques des centres de données sur lesquels vous comptez.
Étalonner vos tests de cette manière crée une carte beaucoup plus précise de la performance mondiale. Cela vous aide à repérer les goulets d'étranglement spécifiques à une région que vous auriez autrement complètement manqués. C'est aussi un bon moment pour vérifier votre configuration de domaine ; vous pouvez trouver des conseils utiles sur comment vérifier la disponibilité d'un domaine et les configurations connexes pour vous assurer que tout est en ordre.
Trouver le bon rythme de test
Les conditions réseau sont en constante évolution. Elles changent tout au long de la journée, de la semaine, et même de la minute. Un test effectué à 3 heures du matin un mardi peut sembler fantastique, mais ce résultat est inutile si votre trafic de pointe se produit à 14 heures un vendredi lorsque tout le monde est en ligne.
Pour obtenir une véritable référence, vous devez tester de manière cohérente dans le temps. Variez :
- Effectuez des tests pendant les heures de pointe.
- Planifiez-en certains pour les fenêtres de maintenance nocturnes.
- N'oubliez pas les week-ends, lorsque les schémas de trafic peuvent être complètement différents.
En échantillonnant les données de manière répétée, vous pouvez lisser les pics et les creux aléatoires. C'est ainsi que vous repérez les problèmes récurrents, comme le réseau qui se congestionne chaque après-midi de semaine juste après le déjeuner.
N'oubliez pas le jitter
La latence moyenne est un bon point de départ, mais elle cache souvent un problème plus sinistre : le jitter. Le jitter est simplement la variation de votre latence dans le temps. Pensez-y : une connexion stable avec un délai prévisible de 80ms est souvent bien meilleure pour les applications en temps réel qu'une connexion qui a une moyenne de 50ms mais qui fluctue sauvagement entre 10ms et 200ms.
Le jitter est le tueur silencieux de l'expérience utilisateur pour tout ce qui est en temps réel, comme les appels VoIP, les vidéoconférences ou les jeux en ligne. Un jitter élevé est ce qui provoque un son haché, une vidéo gelée et des pics de latence frustrants qui rendent une application complètement cassée, même lorsque la latence moyenne semble bonne sur le papier.
Comprendre le jitter signifie regarder au-delà de la moyenne. C'est le méchant méconnu car il révèle pourquoi les moyennes seules peuvent être si trompeuses. Par exemple, des données de Pandora FMS montrent que le jitter supérieur à 30ms peut faire grimper les taux de perte de paquets dans les jeux à 15%—suffisamment pour rendre un jeu injouable. Mesurer l'écart type de vos résultats de latence est la première étape pour quantifier cette instabilité.
Liste de contrôle pour la conception de tests de latence
Pour rassembler tout cela, voici une liste de contrôle rapide pour vous guider. Suivre ces étapes vous aidera à garantir que les données que vous collectez sont à la fois précises et réellement utiles.
| Élément de la liste de contrôle | Pourquoi c'est important | Conseil exploitable |
|---|---|---|
| Définir des objectifs clairs | Vous ne pouvez pas mesurer ce que vous ne définissez pas. Résolvez-vous un problème spécifique ou établissez-vous une référence ? | Notez votre objectif avant de commencer. "Diagnostiquer le retard pour les utilisateurs en Asie du Sud-Est" est un meilleur objectif que "vérifier la latence." |
| Sélectionner des points de terminaison diversifiés | Un seul chemin ne représente pas votre expérience utilisateur mondiale. | Choisissez 3 à 5 emplacements : un local, un sur un autre continent, et quelques-uns dans vos principaux marchés utilisateurs. |
| Établir une cadence | Des tests ponctuels manquent des schémas basés sur le temps, comme la congestion aux heures de pointe. | Planifiez des tests pour qu'ils s'exécutent automatiquement chaque heure pendant une semaine afin de capturer un cycle complet du comportement du réseau. |
| Mesurer le jitter | Les moyennes cachent la performance erratique qui ruine les applications en temps réel. | Ne vous contentez pas de regarder le RTT moyen. Calculez l'écart type ou utilisez un outil comme mtr qui montre la latence min/max/moyenne. |
| Utiliser les bons outils | ping est bon pour un contrôle rapide, mais des outils comme mtr ou iperf fournissent des informations plus approfondies. |
Pour la performance web, utilisez les outils de développement du navigateur. Pour les chemins réseau bruts, mtr est un excellent choix. |
| Documenter tout | Vous oublierez le "pourquoi" derrière votre test dans six mois. | Tenez un simple journal : date, heure, points de terminaison, outil utilisé, et une brève note sur ce que vous avez observé. |
En étant méthodique, vous passez de la simple mesure de la latence à une véritable compréhension de celle-ci. Cette approche réfléchie est ce qui sépare un chiffre aléatoire d'un indicateur de performance fiable.
Donner un sens aux chiffres (et ce qu'il faut éviter)
D'accord, vous avez effectué vos tests et avez une pile de données. C'est là que le vrai travail commence : traduire ces chiffres bruts en quelque chose qui signifie réellement quelque chose. Les données vous racontent une histoire sur la santé de votre réseau ; vous devez juste apprendre à la lire.
Par exemple, un pic soudain dans le temps de réponse aller-retour (RTT) sur un traceroute est un indice classique. Si la latence augmente au troisième saut et reste élevée jusqu'à la fin, vous avez probablement trouvé votre problème : c'est ce troisième routeur ou le lien juste après. Mais soyez prudent. Si seul ce saut unique montre une latence élevée et que la destination finale est toujours rapide, cela pourrait simplement être un routeur configuré pour déprioriser le type de trafic que votre test utilise. C'est une fausse alerte courante qui peut vous entraîner dans un labyrinthe.
Décoder le jitter et la perte de paquets
Regarder au-delà du simple RTT est là où vous trouverez les informations les plus critiques. Un jitter élevé, qui est juste un mot élégant pour désigner une latence incohérente, peut être beaucoup plus perturbateur qu'une latence constamment élevée. C'est particulièrement vrai pour tout ce qui est en temps réel.
Si vos résultats montrent un RTT moyen de 40ms, mais que le minimum était 10ms et le maximum était 150ms, votre connexion est instable. Cette énorme variance est exactement ce qui provoque des saccades ennuyeuses lors des appels vidéo et des pics de latence qui provoquent de la rage dans les jeux en ligne.
La perte de paquets est un signal d'alarme encore plus grand. Même une perte de 1% de paquets peut complètement paralyser les applications basées sur TCP, les forçant à renvoyer constamment des données et ralentissant tout à un rythme d'escargot. Lorsque vous examinez vos résultats de test, toute différence réelle entre les paquets envoyés et les paquets reçus doit être immédiatement examinée.
Une des plus grandes erreurs que je vois les gens faire est de supposer qu'un seul test raconte toute l'histoire. Les conditions réseau changent constamment. Un test effectué à 3 heures du matin aura l'air complètement différent d'un à 15 heures pendant les heures de pointe. La seule façon d'obtenir une véritable référence de performance est de procéder à des tests cohérents et répétés.
Pour anticiper les problèmes, il vaut la peine d'explorer des outils dédiés pour la surveillance de la performance réseau. Cela déplace votre approche d'une réparation frénétique des choses lorsqu'elles se cassent à une maintenance proactive de votre réseau.
Les erreurs de mesure les plus courantes
Même avec les meilleurs outils du monde, quelques erreurs simples peuvent rendre vos résultats complètement inutiles. Éviter ces pièges courants est non négociable si vous voulez des données auxquelles vous pouvez réellement faire confiance.
- Tester sur Wi-Fi : Sérieusement, ne le faites pas. Les connexions sans fil sont notoirement capricieuses, sujettes à des interférences provenant de tout, des micro-ondes au routeur de votre voisin. Pour tout test de latence sérieux, branchez-vous avec un câble Ethernet. C'est le seul moyen d'obtenir une référence stable et fiable.
- Oublier la surcharge VPN : Les VPN sont excellents pour la sécurité, mais ils ajoutent un arrêt supplémentaire et un cryptage au parcours de votre trafic. Cela augmentera toujours la latence. Si vous essayez de diagnostiquer une connexion lente d'un utilisateur, l'une de vos premières questions devrait être : "Êtes-vous sur le VPN ?" Tester avec et sans cela vous montrera exactement combien de retard cela ajoute.
- Ignorer la congestion du réseau local : Vos résultats de test seront faussés si quelqu'un d'autre sur votre réseau monopolise toute la bande passante. Si un collègue diffuse une vidéo 4K ou télécharge des fichiers massifs pendant que vous testez, vos chiffres de latence seront gonflés, et vous finirez par poursuivre un problème qui n'existe pas.
Un autre facteur subtil mais critique est l'outil que vous choisissez. Comme nous l'avons couvert, différents utilitaires mesurent la latence de différentes manières. Soyez toujours cohérent avec les outils que vous utilisez pour la comparaison, et assurez-vous de comprendre ce que chacun mesure réellement—qu'il s'agisse d'un simple écho ICMP ou d'une requête complexe au niveau de l'application. Et rappelez-vous, la performance peut être affectée par de nombreuses couches ; par exemple, si vous explorez la performance web, notre guide sur une extension Chrome Cookie Editor peut montrer comment les éléments côté client jouent un rôle.
En interprétant vos résultats dans le bon contexte et en évitant ces erreurs courantes, vous passerez au-delà de la simple collecte de chiffres. Vous commencerez à comprendre le pourquoi derrière la performance de votre réseau, et c'est la clé pour construire des systèmes plus rapides et plus fiables.
Questions fréquentes sur la latence réseau
Même avec les bons outils, quelques questions courantes semblent toujours surgir lorsque vous commencez à examiner la latence réseau. Passons en revue certaines des plus fréquentes que j'entends pour vous aider à donner un sens à vos résultats.
Quel est un bon chiffre de latence ?
C'est la question classique du "cela dépend", mais nous pouvons certainement établir quelques repères solides. Une latence "bonne" est complètement relative à ce que vous essayez d'accomplir.
- Navigation web occasionnelle : Pour la plupart d'entre nous, tout ce qui est inférieur à 100ms de RTT semblera parfaitement acceptable. Les pages se chargent rapidement, et vous ne remarquerez aucun véritable retard.
- Jeux en ligne compétitifs : C'est là que chaque milliseconde compte. Les joueurs sérieux et les traders à haute fréquence recherchent une latence bien inférieure à 20ms. C'est la différence entre gagner et perdre.
- Appels vidéo et VoIP : Ici, la cohérence est reine. Vous avez besoin d'une latence stable inférieure à 150ms et d'un faible jitter (moins de 30ms) pour éviter cette sensation hachée et désynchronisée ou, pire, les appels interrompus.
En règle générale, la plupart des professionnels du réseau que je connais classeraient tout ce qui est inférieur à 50ms comme une faible latence. De 50-150ms est modéré, et une fois que vous dépassez 150ms, vous commencerez à ressentir le ralentissement sur la plupart des applications interactives.
Pourquoi mes résultats de ping et de test de vitesse du navigateur ne correspondent-ils jamais ?
C'est une question fantastique et un point de confusion très courant. Cela se produit parce qu'une commande ping en ligne de commande et un test de vitesse basé sur un navigateur sont fondamentalement des outils différents mesurant des choses différentes.
Pour commencer, ils parlent presque certainement à des serveurs différents. Lorsque vous ping un domaine, vous ciblez un objectif spécifique. Un test de vitesse web, en revanche, est conçu pour trouver un serveur géographiquement proche de son propre réseau afin de vous donner le meilleur résultat possible.
Les protocoles sont également complètement différents. Ping utilise un protocole très léger appelé ICMP. La plupart des tests de navigateur fonctionnent sur TCP, ce qui nécessite tout un processus de configuration (le "handshake à trois voies") juste pour établir une connexion. Ce va-et-vient initial ajoute un peu de temps avant même que le véritable test ne commence.
Enfin, les tests de navigateur intègrent souvent plus que le simple temps de trajet réseau. Leur chiffre de "latence" peut inclure le temps de traitement du serveur ou même de petits délais au sein de votre navigateur lui-même, ce qui peut gonfler le chiffre final par rapport à un ping ICMP brut.
Comment puis-je réellement réduire ma latence réseau ?
Réduire la latence consiste à traquer et éliminer les goulets d'étranglement, qu'ils se trouvent dans votre bureau ou à travers Internet.
Le premier endroit à examiner est votre environnement immédiat. Le changement le plus efficace que vous puissiez apporter est de passer d'une connexion Wi-Fi à une connexion Ethernet câblée. C'est un véritable changement de jeu pour la stabilité et la vitesse. Si vous devez utiliser le Wi-Fi, rapprochez-vous de votre routeur et connectez-vous à la bande 5GHz si possible, elle est généralement moins encombrée.
En regardant au-delà de votre réseau local, parfois un changement de DNS peut aider. Utiliser un serveur DNS plus rapide peut réduire de quelques millisecondes le temps de connexion initial lorsque vous recherchez un site web.
Si vous essayez d'améliorer l'accès à un service que vous contrôlez, un Réseau de Distribution de Contenu (CDN) est la solution. Cela fonctionne en plaçant des copies de votre contenu physiquement plus près de vos utilisateurs. Et si vous utilisez un VPN, essayez de l'éteindre. Ce saut supplémentaire et cette couche de cryptage ajoutent presque toujours de la latence.
J'ai vu des VPN d'entreprise ajouter jusqu'à 70ms au temps de réponse. Cela peut transformer une excellente connexion en une connexion frustrante et lente. Testez toujours avec et sans votre VPN pour voir quel type de perte de performance vous subissez réellement.
Quelle est la véritable différence entre latence et bande passante ?
Bien comprendre cela est fondamental pour appréhender la performance du réseau. Il est facile de les confondre, mais ils mesurent deux choses très différentes.
Voici l'analogie que j'utilise toujours : pensez-y comme à une autoroute.
- Bande passante est le nombre de voies que l'autoroute possède. Plus il y a de voies, plus de voitures (données) peuvent circuler en même temps.
- Latence est la limite de vitesse. Elle détermine la vitesse à laquelle une seule voiture (un paquet de données) peut aller de A à B.
Vous pourriez avoir une autoroute massive à dix voies (bande passante énorme) avec une limite de vitesse de 20 mph (latence élevée). Vous pourriez déplacer une tonne de données au final, mais des choses en temps réel comme un appel vidéo seraient douloureusement lentes. À l'inverse, une connexion avec une latence très faible semble incroyablement réactive et rapide, même si sa bande passante n'est pas énorme. Vous avez vraiment besoin d'un bon équilibre des deux pour une excellente expérience.
Prêt à faire des tests de performance une partie intégrante de votre flux de travail quotidien ? La suite ShiftShift Extensions met à votre disposition un puissant test de vitesse, un formateur JSON et des dizaines d'autres outils pour développeurs directement dans votre navigateur, accessibles par une seule commande. Arrêtez de jongler avec les onglets et commencez à travailler plus intelligemment. Téléchargez ShiftShift Extensions gratuitement et boostez votre productivité dès aujourd'hui.