Como Medir a Latência de Rede: Um Guia Prático para Desenvolvedores
Aprenda a medir a latência da rede com este guia abrangente. Abordamos ferramentas essenciais como ping e traceroute, bem como técnicas de teste baseadas em navegador.

Extensões Recomendadas
Quer medir a latência da rede? Pode começar com ferramentas simples e integradas de linha de comando como ping e traceroute para obter uma leitura rápida do Tempo de Ida e Volta (RTT). Ou pode abrir as ferramentas de desenvolvedor do seu navegador para ver como os atrasos estão a afetar a experiência real dos seus utilizadores.
Estes métodos oferecem um instantâneo rápido e útil de quanto tempo leva para um pacote de dados viajar de uma fonte, alcançar um destino e voltar.
Por Que Medir a Latência É Não Negociável
Antes de entrarmos no "como", vamos falar sobre o "porquê". Para desenvolvedores e engenheiros de rede, a latência não é apenas um número numa tela; é a mão invisível que molda toda a experiência do utilizador. Nas aplicações de hoje, milissegundos são tudo. Mesmo um pequeno atraso pode ser a diferença entre um serviço que parece instantâneo e um que parece avariado.
Pense nas consequências no mundo real:
- Responsividade da API: Uma única chamada de API lenta pode criar um efeito dominó, atrasando tudo, desde o carregamento do perfil de um utilizador até ao processamento de um pagamento crítico.
- Fluxos de Dados em Tempo Real: Para jogos online, vídeo ao vivo ou negociação financeira, uma latência baixa e consistente é a base absoluta. Sem isso, estas aplicações simplesmente não funcionam.
- Retenção de Utilizadores: Existe uma ligação direta entre websites e aplicações que carregam lentamente e taxas de rejeição mais altas e carrinhos de compras abandonados. Isto afeta diretamente o resultado financeiro.
Distinguir Conceitos Chave de Latência
Para medir a latência da rede com precisão, é necessário saber o que está a observar. Os dois conceitos mais fundamentais são Tempo de Ida e Volta (RTT) e latência de uma só via.
RTT é o tempo total que leva para um sinal ir do ponto A ao ponto B e voltar novamente. É a métrica mais comum que verá porque é simples de medir—só precisa de acesso a uma das extremidades da conexão.
Latência de uma só via, como o nome sugere, mede o tempo que leva para os dados viajarem numa única direção. Esta é uma medição muito mais complicada de obter corretamente porque requer relógios perfeitamente sincronizados em ambos os pontos finais. No entanto, é um indicador muito mais preciso para conexões assimétricas, onde os caminhos de upload e download se comportam de forma muito diferente.
A importância de tudo isto torna-se clara quando está a realizar testes sérios de performance de carga, onde a teoria encontra a realidade e os gargalos são expostos.
Para colocar alguns números, especialistas em monitorização de rede geralmente classificam a latência assim:
- Baixa latência: Abaixo de 50 milissegundos
- Latência moderada: 50-150 ms
- Alta latência: Acima de 150 ms
Da minha experiência, um teste rápido a um servidor próximo pode mostrar uma latência perfeitamente aceitável de 20-40 ms. Mas esse número pode facilmente aumentar para mais de 200 ms para tráfego que tem de atravessar um oceano, o que pode ser um fator decisivo para o desempenho da sua aplicação.
Para entender a terminologia que encontrará, aqui está uma referência rápida.
Conceitos Chave de Latência em Resumo
| Conceito | O Que Mede | Por Que É Importante |
|---|---|---|
| Latência (Ping) | O tempo que leva para um único pacote de dados viajar de uma fonte a um destino e voltar. Medido em milissegundos (ms). | Esta é a medida bruta do atraso. Baixa latência é crucial para aplicações em tempo real como jogos, VoIP e videoconferências. |
| Tempo de Ida e Volta (RTT) | Essencialmente o mesmo que latência, esta é a duração total para um sinal ser enviado mais o tempo para um reconhecimento ser recebido. | RTT é a forma mais comum e prática de medir a latência a partir de um único ponto, tornando-se a métrica de referência para ferramentas como ping. |
| Latência de Uma Só Via | O tempo que leva para um pacote viajar de fonte a destino numa única direção. | Fornece uma visão mais granular, especialmente para redes assimétricas onde os caminhos de upload e download têm latências diferentes. |
| Jitter | A variação na latência ao longo do tempo. Mede a inconsistência dos tempos de chegada dos pacotes. | Um alto jitter é tão mau quanto uma alta latência para streaming de media e chamadas online, causando gagueira, buffering e falhas. |
| Largura de Banda | A quantidade máxima de dados que pode ser transmitida através de uma conexão de rede num determinado período de tempo. Medido em Mbps ou Gbps. | Frequentemente confundida com velocidade, a largura de banda diz respeito à capacidade. Pode ter uma alta largura de banda mas ainda assim sofrer de alta latência. |
Estes conceitos são os blocos de construção para entender qualquer problema de desempenho de rede.
É aqui que ter ferramentas acessíveis e integradas se torna tão importante. Em vez de executar suítes de diagnóstico complexas, extensões modernas de navegador e ferramentas de desenvolvimento podem fornecer as informações necessárias sem nunca sair do seu fluxo de trabalho. Trata-se de tornar a medição da latência uma parte fácil e rotineira da construção e manutenção de um ótimo software.
Colocando as Mãos na Massa com Ferramentas de Latência de Linha de Comando
Para realmente sentir o desempenho da sua rede, precisa abrir o terminal. A linha de comando é onde encontrará as ferramentas fundamentais que lhe dão dados brutos e não filtrados sobre a sua conexão. Trata-se de ver o que está realmente a acontecer com os pacotes que se movem entre si e um destino, e é o primeiro passo essencial para qualquer desenvolvedor sério sobre a medição da latência.
A ferramenta clássica e de referência é o ping. É maravilhosamente simples: envia um pequeno pacote de dados (um pedido de eco ICMP) para um servidor e apenas espera que ele volte. Essa simples viagem de ida e volta é a base para calcular o Tempo de Ida e Volta (RTT) e dá-lhe uma verificação instantânea da saúde de uma conexão.
A Sua Primeira Verificação de Latência com Ping
Executar um teste ping não poderia ser mais fácil. Abra o seu terminal ou prompt de comando, digite ping e siga-o com o domínio que deseja testar.
Por padrão, o ping continuará a correr indefinidamente no macOS e Linux, enquanto o Windows envia apenas quatro pacotes e para. Para qualquer análise real, desejará controlar isto. Enviar dez ou vinte pacotes dá-lhe uma imagem muito mais fiável da estabilidade da conexão do que apenas alguns.
Uma vez terminado, receberá um resumo organizado com os números cruciais:
- Pacotes Transmitidos/Recebidos: Isto diz-lhe se algum dado foi perdido ao longo do caminho. Mesmo uma pequena quantidade de perda de pacotes é um grande sinal de alerta para problemas de rede.
- Ida e volta min/média/máx/mdev: Estas são as suas estatísticas de latência principais. Você obtém o tempo do melhor caso (
min), a média (avg) e o pior caso (max). Omdev(desvio médio) é a sua medida de jitter—quanto a latência varia de um pacote para o próximo.
Preste atenção ao intervalo entre o seu RTT mínimo e máximo. Se for amplo, a sua conexão é instável, mesmo que a média pareça aceitável. Este jitter pode ser muito mais disruptivo para aplicações em tempo real como chamadas de vídeo ou jogos do que uma conexão que é consistentemente um pouco lenta.
Um erro comum é apenas olhar para a média do RTT. Uma média de 50ms pode parecer aceitável, mas se o seu mínimo é 20ms e o seu máximo é 250ms, a experiência do utilizador parecerá irregular e pouco fiável. Olhe sempre para a gama completa para entender o jitter.
Seguindo o Rastro com Traceroute e MTR
Então, o que fazer quando o ping revela alta latência ou perda de pacotes? O seu próximo trabalho é descobrir onde está o problema. É para isso que serve o traceroute (ou tracert no Windows). Ele mapeia todo o caminho que os seus pacotes percorrem, mostrando cada "salto"—cada router—entre a sua máquina e o destino final.
Cada linha na saída do traceroute é um salto, e geralmente mostra três medições de latência separadas até aquele ponto. Isso permite que você identifique se um router específico ao longo do caminho está a causar uma desaceleração significativa ou a descartar pacotes.
Mas o traceroute é um instantâneo único. Para uma visão mais dinâmica e contínua, a maioria dos profissionais de rede que conheço jura pelo MTR (My Traceroute). O MTR é como uma ferramenta supercarregada que combina ping e traceroute. Ele envia constantemente pacotes para cada salto na rota, dando-lhe uma visão ao vivo e atualizada da latência e perda de pacotes em cada ponto. Isso torna-o incrivelmente eficaz para capturar problemas intermitentes que um único traceroute provavelmente perderia.
Por Que a Sua Escolha de Ferramenta É Importante
A ferramenta que escolher e como a configurar pode mudar drasticamente os seus resultados. Isso é especialmente verdadeiro em ambientes ultra-rápidos e de baixa latência, como centros de dados em nuvem.
É realmente surpreendente como os números podem ser diferentes. Numa experiência detalhada realizada pela Google Cloud, um teste padrão de ping reportou um RTT médio de 146 microsegundos. Mas quando usaram outra ferramenta que envia transações consecutivas sem pausa, o RTT caiu para apenas 66.59 microsegundos—mais de duas vezes mais rápido!
Este é um exemplo perfeito de por que o ping pode às vezes superestimar a latência. Mostra que entender como uma ferramenta funciona é crítico para obter medições em que pode confiar.
Encontrando a Velocidade Máxima da Sua Conexão com iperf
A latência nem sempre é o quadro completo. Às vezes, precisa saber a quantidade máxima de dados que a sua conexão pode realmente transmitir—sua largura de banda. Para essa tarefa, a ferramenta que deseja é o iperf.
Enquanto o ping mede o atraso, o iperf é todo sobre a taxa de transferência. Funciona configurando uma conexão cliente-servidor e, em seguida, enviando o máximo de dados que puder entre eles durante um período de tempo definido.
Para usar o iperf, precisará de duas máquinas:
- Em uma máquina, execute o
iperfem modo servidor. Ele ficará lá e ouvirá por uma conexão. - Na outra máquina, execute o
iperfem modo cliente, apontando para o endereço do servidor.
O cliente irá conectar-se e o teste começará. A saída informa-lhe o total de dados transferidos e, mais importante, a taxa de bits (sua largura de banda) em megabits ou gigabits por segundo. É a maneira perfeita de testar a resistência de um link de rede e descobrir do que ele é realmente capaz.
Medindo a Latência da Perspectiva do Utilizador
Enquanto as ferramentas de linha de comando lhe dão uma visão bruta e não filtrada da sua rede, a única latência que realmente importa para uma aplicação web é o que o utilizador final realmente experimenta. É aqui que mudamos o nosso foco do terminal para o próprio navegador. O que acontece dentro do navegador conta uma história muito mais rica e relevante sobre o desempenho.
Nunca se trata apenas de uma única viagem de ida e volta de um pacote. A latência que um utilizador sente é um coquetel complexo de pesquisas DNS, handshakes TCP, negociações TLS, tempo de processamento do servidor e, claro, o tempo que leva para realmente renderizar o conteúdo na tela. Felizmente, os navegadores modernos vêm equipados com poderosas ferramentas integradas para nos ajudar a dissecar todo esse processo.
Mergulhando nas Ferramentas de Desenvolvedor do Navegador
Cada navegador principal—Chrome, Firefox, Edge, Safari—vem equipado com um conjunto de ferramentas de desenvolvedor. A aba "Rede" dentro dessas ferramentas é o seu centro de comando para entender como o seu site carrega. Ela apresenta tudo num gráfico de cascata, que é uma divisão visual de cada pedido que o navegador faz para renderizar uma página.
Esta visão em cascata é inestimável. Você pode ver precisamente quanto tempo cada ativo levou para ser descarregado, desde o documento HTML inicial e folhas de estilo CSS até imagens e chamadas de API. Mais importante, ela divide o ciclo de vida de cada pedido em fases distintas:
- Pesquisa DNS: O tempo que leva para resolver um nome de domínio em um endereço IP.
- Conexão Inicial: O tempo gasto para estabelecer uma conexão TCP com o servidor.
- Handshake SSL/TLS: O overhead necessário para configurar uma conexão segura.
- Tempo até o Primeiro Byte (TTFB): Este é um ponto crucial. Mede quanto tempo o navegador esperou antes de receber o primeiro byte de dados do servidor.
- Download de Conteúdo: O tempo gasto realmente a descarregar o recurso em si.
Um alto TTFB, por exemplo, é um sinal clássico de um backend lento ou problema de processamento do lado do servidor—algo que um simples teste ping nunca revelaria. Ao analisar esta cascata, pode rapidamente identificar quais recursos estão a bloquear a renderização ou simplesmente a demorar demasiado a carregar.
Uma lição importante da minha experiência é não apenas olhar para o tempo total de carregamento, mas procurar as barras mais longas na cascata. Uma única imagem não otimizada ou uma API de terceiros lenta pode manter toda a página refém, criando uma má experiência para o utilizador, mesmo que o resto do site seja extremamente rápido.
Medida Programática com APIs de Tempo
Para medições mais automatizadas e precisas, pode aceder às APIs JavaScript integradas do navegador. A API de Tempo de Navegação e a API de Tempo de Recursos oferecem acesso programático aos mesmos dados detalhados de desempenho que vê nas ferramentas de desenvolvedor. Isso é perfeito para coletar dados de monitoramento de utilizadores reais (RUM) para entender como o seu site se comporta para visitantes reais em todo o mundo.
Você pode obter essas métricas com apenas algumas linhas de JavaScript, diretamente no console do navegador. Para obter os tempos de desempenho principais para o carregamento da página principal, por exemplo, pode usar performance.getEntriesByType('navigation'). Isso retorna um objeto repleto de timestamps valiosos.
Com esses dados, pode calcular métricas vitais:
- Tempo de Pesquisa DNS:
domainLookupEnd - domainLookupStart - Tempo de Handshake TCP:
connectEnd - connectStart - Tempo até o Primeiro Byte (TTFB):
responseStart - requestStart - Tempo Total de Carregamento da Página:
loadEventEnd - startTime
Esta abordagem permite-lhe construir painéis personalizados ou enviar dados de desempenho para as suas ferramentas de análise, dando-lhe um pulso contínuo sobre o desempenho real da sua aplicação. No desenvolvimento web, otimizar imagens é uma forma comum de melhorar estas métricas; para aqueles interessados, temos um guia útil sobre como escolher o melhor formato de imagem para o seu website.
Agilizando Verificações com Ferramentas Integradas
Alternar entre o terminal, as ferramentas de desenvolvimento do navegador e scripts personalizados pode tornar-se cansativo rapidamente. É aqui que as extensões de navegador integradas podem realmente suavizar o seu fluxo de trabalho ao unificar estas verificações. Por exemplo, o conjunto de ShiftShift Extensions inclui uma ferramenta de Teste de Velocidade embutida que pode abrir instantaneamente a partir de qualquer aba.
Isso oferece uma forma rápida e focada na privacidade de medir a velocidade de download, a velocidade de upload e a latência da sua conexão sem ter que navegar para um site separado ou abrir um terminal. Como faz parte de um conjunto de ferramentas maior, pode realizar uma verificação de velocidade, formatar uma resposta JSON e verificar um cookie tudo a partir da mesma palete de comandos unificada. Este tipo de integração torna as verificações de desempenho uma parte natural e sem atritos da rotina diária de desenvolvimento.
Como Projetar um Teste de Latência que Realmente Diga Algo
Qualquer um pode disparar um comando ping e obter um número de volta. Mas se quiser dados em que realmente possa confiar—dados que o ajudem a tomar decisões reais—precisa de ser mais deliberado. Uma única medição isolada é apenas uma instantânea no tempo. Para entender verdadeiramente o comportamento da sua rede, tem de pensar como um detetive, considerando de onde testa, com que frequência testa e o que está realmente à procura.
Um teste bem projetado transforma números brutos em insights acionáveis. Um mal projetado? É apenas ruído.
O diagrama abaixo detalha todos os pequenos atrasos que se somam ao que um utilizador sente ao carregar uma página web. É um ótimo lembrete de que um simples ping de rede não começa a contar toda a história.
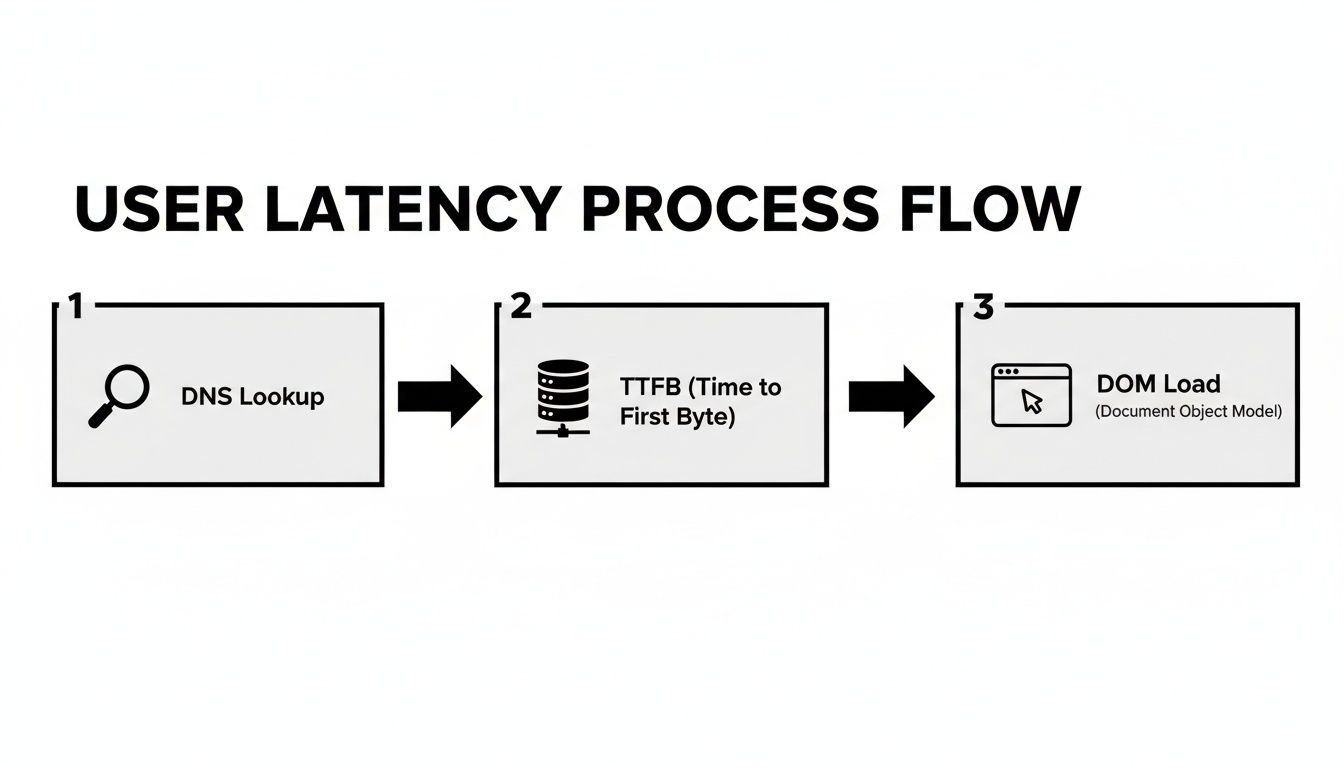
Como pode ver, desde a pesquisa DNS inicial até à renderização final, múltiplos passos contribuem para o tempo total de espera.
Escolhendo os Seus Endpoints de Teste
A primeira regra de testes fiáveis é que a geografia importa. Um teste do seu escritório em Nova Iorque para um servidor ali perto em Nova Jérsia não lhe diz absolutamente nada sobre a experiência dos seus clientes em Tóquio. Para obter uma imagem realista, tem de testar a partir de locais diversos que realmente reflitam a sua base de utilizadores.
A sua lista de endpoints deve cobrir algumas áreas-chave:
- Os Seus Maiores Centros de Utilizadores: Onde vivem a maioria dos seus clientes? Teste a partir daí.
- Caminhos Transcontinentais: Veja o que acontece quando os dados têm de cruzar um oceano. Teste entre a Europa e a América do Norte, ou a Ásia e os EUA, para entender o desempenho de longa distância.
- As Suas Regiões de Nuvem: Se estiver na AWS, Azure ou GCP, teste a conectividade para e entre as regiões específicas dos centros de dados em que confia.
Espalhar os seus testes desta forma cria um mapa muito mais preciso do desempenho global. Ajuda-o a identificar gargalos específicos de região que, de outra forma, poderia perder completamente. Este também é um bom momento para verificar a configuração do seu domínio; pode encontrar dicas úteis sobre como verificar a disponibilidade do domínio e configurações relacionadas para garantir que tudo está em ordem.
Encontrando o Ritmo de Teste Certo
As condições da rede estão constantemente em mudança. Elas mudam ao longo do dia, da semana e até mesmo do minuto. Um teste realizado às 3 da manhã numa terça-feira pode parecer fantástico, mas esse resultado é inútil se o seu tráfego de pico ocorrer às 2 da tarde numa sexta-feira, quando todos estão online.
Para obter uma linha de base verdadeira, precisa de testar consistentemente ao longo do tempo. Varie:
- Realize testes durante as horas de pico de negócios.
- Agende alguns para janelas de manutenção noturnas.
- Não se esqueça dos fins de semana, quando os padrões de tráfego podem ser completamente diferentes.
Ao amostrar dados repetidamente, pode suavizar os picos e quedas aleatórias. É assim que identifica problemas recorrentes, como a rede a ficar congestionada todas as tardes de dias úteis logo após o almoço.
Não Se Esqueça do Jitter
A latência média é um bom ponto de partida, mas muitas vezes esconde um problema mais sinistro: jitter. Jitter é simplesmente a variação na sua latência ao longo do tempo. Pense nisso—uma conexão estável com um atraso previsível de 80ms é muitas vezes muito melhor para aplicações em tempo real do que uma que tem uma média de 50ms mas oscila entre 10ms e 200ms.
O jitter é o assassino silencioso da experiência do utilizador para qualquer coisa em tempo real, como chamadas VoIP, videoconferências ou jogos online. Um alto jitter é o que causa áudio entrecortado, vídeo congelado e picos de latência frustrantes que fazem uma aplicação parecer completamente quebrada, mesmo quando a latência média parece boa no papel.
Compreender o jitter significa olhar além da média. É o vilão não reconhecido porque revela por que as médias sozinhas podem ser tão enganosas. Por exemplo, dados de Pandora FMS mostram que jitter acima de 30ms pode aumentar as taxas de perda de pacotes em jogos para 15%—suficiente para tornar um jogo injogável. Medir o desvio padrão dos seus resultados de latência é o primeiro passo para quantificar essa instabilidade.
Lista de Verificação para o Design de Testes de Latência
Para juntar tudo isto, aqui está uma lista de verificação rápida para o guiar. Seguir estes passos ajudará a garantir que os dados que recolhe são tanto precisos como genuinamente úteis.
| Item da Lista de Verificação | Por Que É Importante | Dica Acionável |
|---|---|---|
| Defina Objetivos Claros | Não pode medir o que não define. Está a resolver um problema específico ou a estabelecer uma linha de base? | Escreva o seu objetivo antes de começar. "Diagnosticar latência para utilizadores no Sudeste Asiático" é um objetivo melhor do que "verificar latência." |
| Selecione Endpoints Diversos | Um único caminho não representa a sua experiência global de utilizador. | Escolha 3-5 locais: um local, um em outro continente e alguns nos seus principais mercados de utilizadores. |
| Estabeleça uma Cadência | Testes únicos perdem padrões baseados no tempo, como congestionamento nas horas de pico. | Agende testes para serem executados automaticamente a cada hora durante uma semana para capturar um ciclo completo do comportamento da rede. |
| Meça o Jitter | As médias escondem o desempenho errático que arruína aplicações em tempo real. | Não olhe apenas para o RTT médio. Calcule o desvio padrão ou use uma ferramenta como mtr que mostra a latência mínima/máxima/média. |
| Use as Ferramentas Certas | ping é bom para uma verificação rápida, mas ferramentas como mtr ou iperf fornecem insights mais profundos. |
Para desempenho web, use ferramentas de desenvolvimento do navegador. Para caminhos de rede brutos, mtr é uma ótima escolha. |
| Documente Tudo | Esquecerá o "porquê" por trás do seu teste seis meses a partir de agora. | Mantenha um registo simples: data, hora, endpoints, ferramenta utilizada e uma breve nota sobre o que observou. |
Ao ser metódico, passa de simplesmente medir a latência para realmente compreendê-la. Esta abordagem cuidadosa é o que separa um número aleatório de um indicador de desempenho fiável.
Dando Sentido aos Números (e o que Evitar)
Está bem, você executou os seus testes e tem uma pilha de dados. É aqui que o verdadeiro trabalho começa—traduzir esses números brutos em algo que realmente signifique algo. Os dados estão a contar-lhe uma história sobre a saúde da sua rede; você só precisa aprender a lê-la.
Por exemplo, um pico repentino no Tempo de Ida e Volta (RTT) num traceroute é uma pista clássica. Se a latência salta no número de salto três e permanece alta até ao final, provavelmente encontrou o seu problema: é aquele terceiro router ou o link logo a seguir. Mas tenha cuidado. Se apenas aquele único salto mostrar alta latência e o destino final ainda for rápido, pode ser apenas um router configurado para despriorizar o tipo exato de tráfego que o seu teste utiliza. É um falso alarme comum que pode levá-lo a um buraco de coelho.
Decodificando Jitter e Perda de Pacotes
Olhar além do simples RTT é onde encontrará os insights mais críticos. Um alto jitter, que é apenas uma palavra chique para latência inconsistente, pode ser muito mais disruptivo do que uma latência que é consistentemente alta. Isso é especialmente verdadeiro para qualquer coisa em tempo real.
Se os seus resultados mostram um RTT médio de 40ms, mas o mínimo foi 10ms e o máximo foi 150ms, a sua conexão é instável. Essa enorme variação é exatamente o que causa interrupções irritantes em chamadas de vídeo e picos de latência que provocam raiva em jogos online.
A perda de pacotes é um sinal de alerta ainda maior. Mesmo 1% de perda de pacotes pode incapacitar completamente aplicações baseadas em TCP, forçando-as a reenviar dados constantemente e desacelerando tudo até um ponto de paragem. Quando olhar para os seus resultados de teste, qualquer diferença real entre pacotes enviados e pacotes recebidos precisa ser investigada imediatamente.
Um dos maiores erros que vejo as pessoas cometerem é assumir que um único teste conta toda a história. As condições da rede estão constantemente a mudar. Um teste realizado às 3 da manhã parecerá completamente diferente de um às 3 da tarde durante as horas de pico de negócios. A única forma de obter uma verdadeira linha de base de desempenho é através de testes consistentes e repetidos.
Para antecipar problemas, vale a pena investigar ferramentas dedicadas para monitorização de desempenho de rede. Isso muda a sua abordagem de consertar coisas freneticamente quando elas quebram para manter proativamente a sua rede saudável.
Os Erros de Medição Mais Comuns
Mesmo com as melhores ferramentas do mundo, alguns erros simples podem tornar os seus resultados completamente inúteis. Evitar estas armadilhas comuns é inegociável se quiser dados em que realmente possa confiar.
- Testar via Wi-Fi: Sério, simplesmente não o faça. Conexões sem fio são notoriamente caprichosas, propensas a interferências de tudo, desde micro-ondas até ao router do seu vizinho. Para qualquer teste sério de latência, ligue-se com um cabo Ethernet. É a única forma de obter uma linha de base estável e fiável.
- Esquecer a Sobrecarga do VPN: VPNs são ótimas para segurança, mas adicionam uma paragem extra e criptografia à jornada do seu tráfego. Isso sempre aumentará a latência. Se estiver a tentar diagnosticar a conexão lenta de um utilizador, uma das suas primeiras perguntas deve ser: ">Está a usar o VPN?" Testar com e sem ele mostrará exatamente quanto atraso está a adicionar.
- Ignorar o Congestionamento da Rede Local: Os seus resultados de teste estarão distorcidos se alguém mais na sua rede estiver a monopolizar toda a largura de banda. Se um colega estiver a transmitir vídeo 4K ou a descarregar arquivos enormes enquanto você está a testar, os seus números de latência estarão inflacionados, e você acabará a perseguir um problema que não existe.
Outro fator sutil, mas crítico, é a ferramenta que você escolhe. Como já abordamos, diferentes utilitários medem a latência de maneiras diferentes. Esteja sempre consistente com as ferramentas que usa para comparação e certifique-se de que entende o que cada uma está realmente a medir—seja um simples eco ICMP ou um pedido complexo a nível de aplicação. E lembre-se, o desempenho pode ser afetado por muitas camadas; por exemplo, se estiver a investigar o desempenho web, o nosso guia sobre uma Extensão de Editor de Cookies do Chrome pode mostrar como os elementos do lado do cliente desempenham um papel.
Ao interpretar os seus resultados com o contexto certo e evitar estes erros comuns, você irá além de simplesmente coletar números. Começará a entender o porquê por trás do desempenho da sua rede, e essa é a chave para construir sistemas mais rápidos e fiáveis.
Perguntas Comuns Sobre Latência de Rede
Mesmo com as ferramentas certas, algumas perguntas comuns parecem sempre surgir quando você começa a investigar a latência de rede. Vamos percorrer algumas das mais frequentes que ouço para ajudá-lo a dar sentido aos seus resultados.
Qual é na verdade um Número de Latência “Bom”?
Esta é a clássica pergunta do "depende", mas podemos definitivamente estabelecer alguns benchmarks sólidos. Uma latência "boa" é completamente relativa ao que você está a tentar alcançar.
- Navegação Web Casual: Para a maioria de nós, qualquer coisa abaixo de 100ms de RTT parecerá perfeitamente aceitável. As páginas carregam rapidamente, e você não notará qualquer atraso real.
- Jogos Online Competitivos: Aqui, cada milissegundo conta. Jogadores sérios e traders de alta frequência estão à procura de latências bem abaixo de 20ms. É a diferença entre ganhar e perder.
- Chamadas de Vídeo & VoIP: Aqui, a consistência é fundamental. Você precisa de uma latência estável abaixo de 150ms e baixo jitter (menos de 30ms) para evitar aquela sensação entrecortada e fora de sincronia ou, pior, chamadas perdidas.
Como regra geral, a maioria dos profissionais de rede que conheço classificaria qualquer coisa abaixo de 50ms como baixa latência. De 50-150ms é moderada, e uma vez que ultrapasse 150ms, você começará a sentir o arrasto na maioria das aplicações interativas.
Por Que os Meus Resultados de Ping e Teste de Velocidade do Navegador Nunca Correspondem?
Esta é uma pergunta fantástica e um ponto de confusão super comum. Acontece porque um ping de linha de comando e um teste de velocidade baseado em navegador são ferramentas fundamentalmente diferentes que medem coisas diferentes.
Para começar, eles estão quase certamente a comunicar com servidores diferentes. Quando você ping um domínio, está a atingir um alvo específico. Um teste de velocidade web, por outro lado, é projetado para encontrar um servidor geograficamente próximo da sua própria rede para lhe dar o melhor resultado possível.
Os protocolos também são completamente diferentes. Ping usa um protocolo muito leve chamado ICMP. A maioria dos testes de navegador funciona sobre TCP, que requer todo um processo de configuração (o "handshake de três vias") apenas para estabelecer uma conexão. Esse vai-e-vem inicial adiciona um pouco de tempo antes que o verdadeiro teste comece.
Finalmente, os testes de navegador muitas vezes incluem mais do que apenas o tempo de viagem de rede puro. O seu número de "latência" pode incluir o tempo de processamento do servidor ou até pequenos atrasos dentro do próprio navegador, o que pode inflacionar o número final em comparação com um ping ICMP bruto.
Como Posso Realmente Reduzir a Minha Latência de Rede?
Reduzir a latência é tudo sobre caçar e eliminar gargalos, estejam eles no seu escritório ou através da internet.
O primeiro lugar a olhar é o seu ambiente imediato. A mudança mais eficaz que pode fazer é passar de Wi-Fi para uma ligação Ethernet com fio. É uma mudança radical para a estabilidade e velocidade. Se tiver de usar Wi-Fi, aproxime-se do seu router e conecte-se à banda de 5GHz, se puder—geralmente está menos congestionada.
Olhando além da sua rede local, às vezes uma troca de DNS pode ajudar. Usar um servidor DNS mais rápido pode reduzir milissegundos no tempo de conexão inicial ao procurar um website.
Se está a tentar melhorar o acesso a um serviço que controla, uma Rede de Distribuição de Conteúdo (CDN) é a resposta. Funciona colocando cópias do seu conteúdo fisicamente mais perto dos seus utilizadores. E se estiver a usar uma VPN, experimente desligá-la. Esse salto extra e camada de encriptação quase sempre adiciona latência.
Vi VPNs corporativas adicionar até 70ms ao tempo de ida e volta. Pode transformar uma ótima conexão numa frustrante conexão lenta. Teste sempre com e sem a sua VPN para ver que tipo de impacto de desempenho está realmente a ter.
Qual é a Real Diferença Entre Latência e Largura de Banda?
Compreender isto é fundamental para entender o desempenho da rede. É fácil confundi-los, mas medem duas coisas muito diferentes.
Aqui está a analogia que uso sempre: pense nisso como uma autoestrada.
- Largura de banda é quantas faixas a autoestrada tem. Mais faixas significam que mais carros (dados) podem viajar ao mesmo tempo.
- Latência é o limite de velocidade. Ela dita quão rápido um único carro (um pacote de dados) pode ir de A a B.
Pode ter uma autoestrada enorme, com dez faixas (largura de banda enorme) e um limite de velocidade de 20 mph (alta latência). Poderia mover uma tonelada de dados eventualmente, mas coisas em tempo real, como uma chamada de vídeo, seriam dolorosamente lentas. Por outro lado, uma conexão com latência muito baixa parece incrivelmente rápida e responsiva, mesmo que a sua largura de banda não seja enorme. Precisa realmente de um bom equilíbrio entre ambos para uma ótima experiência.
Pronto para tornar os testes de desempenho uma parte fluida do seu fluxo de trabalho diário? A suíte ShiftShift Extensions coloca um poderoso Teste de Velocidade, formatador JSON e dezenas de outras ferramentas para desenvolvedores diretamente no seu navegador, acessíveis com um único comando. Pare de equilibrar abas e comece a trabalhar de forma mais inteligente. Descarregue as ShiftShift Extensions gratuitamente e potencialize a sua produtividade hoje.